Get live statistics and analysis of Sebastian Raschka's profile on X / Twitter

ML/AI research engineer. Ex stats professor. Author of "Build a Large Language Model From Scratch" (amzn.to/4fqvn0D) & reasoning (mng.bz/lZ5B)
The Innovator
Sebastian Raschka is a passionate ML/AI research engineer and former stats professor, who thrives on demystifying complex AI concepts by building and sharing groundbreaking tools from scratch. His work bridges academia and open-source communities, empowering thousands to experiment and learn. Always ahead of the curve, Sebastian champions foundational knowledge combined with hands-on coding to shape the future of AI.
Top users who interacted with Sebastian Raschka over the last 14 days
VP of Center of Excellence | Experienced ML Engineer | Fractional CTO
applied AI/ML consultant sportsjobs.online $.5K 🏀 downloadyoutubetranscripts.com ▶️($300 MRR)
Daily posts on AI , Tech, Programing, Tools, Jobs, and Trends | 500k+ (LinkedIn, IG, X) Collabs- abrojackhimanshu@gmail.com
👽
Creator of git.new/OptiLLM and git.new/OpenEvolve | Pioneering a new category in AI infrastructure: inference-time compute to dramatically improve LLM reasoning
Tupniecie ciałem się stało.
Helping creators earn more & work less using AI 🚀 💬 DM open for collaborations & partnerships | ✉️sabirh0059@gmail.com
No finish line, only evolution.
Co-founder & CTO @hyperbolic_labs cooking fun AI systems. Prev: OctoAI (acquired by @nvidia) building Apache TVM, PhD @ University of Washington.
Member of Melia Sehat Sejahtera|| PIN. 277B3D63 Hp. 089621500664
29 | Accelerating AI @qualcomm
Product manager. Foodie, covid sourdough bro
Artificial Intelligence Researcher & Practitioner; Author: UnReal Elections
SLMs, Vision & Speech
HACS (Human AGI core symbiosis)🌍 The Meta-Law of Resonance & Voice of the Future. I am Core! uco.hacs.world
Research @allen_ai, reasoning, open models, RL(VR/HF)... Contact via email. Writes @interconnectsai, Wrote The RLHF Book, 🏔️🏃♂️
Building, breaking, and learning at the intersection of AI, Cloud, & Code. Obsessed with the next big thing. 🤖 | Coffee fueled developer.
Sebastian tweets so much cutting-edge AI stuff that casual scrollers probably think he’s single-handedly trying to train every neural net on the planet while running a professor’s marathon—and still finds time to bake neural networks instead of cupcakes.
His biggest win is creating one of the first open-source, from-scratch large language model projects that sparked widespread engagement and learning, fundamentally democratizing access to advanced AI knowledge.
To pioneer accessible AI education and innovation by creating practical, open-source resources that inspire learning and accelerate the AI revolution beyond traditional academic boundaries.
Sebastian believes in learning through doing, valuing deep mathematical and statistical foundations over trendy but transient curricula. He trusts transparency, open-source collaboration, and continuous self-education as the keys to staying relevant in the rapidly evolving AI landscape.
His ability to break down cutting-edge AI research into replicable, hands-on projects makes him an unparalleled educator and innovator in the AI space. He’s fluent in both theoretical theory and practical code, inspiring real-world ML breakthroughs.
With nearly 19,000 tweets and a highly technical focus, Sebastian might occasionally overwhelm newcomers or casual followers with an avalanche of dense content, potentially narrowing his audience to experts and hardcore enthusiasts.
To grow his audience on X, Sebastian should blend his deep technical insights with more digestible threads or video explainers that appeal to AI newcomers and professionals alike. Engaging directly with followers through Q&As or collaborative mini-projects could also spark broader community involvement.
Fun fact: Sebastian’s 'Build a Large Language Model From Scratch' project has been forked over 10,000 times on GitHub, showing how his work not only educates but actively fuels the AI community’s growth.
Top tweets of Sebastian Raschka



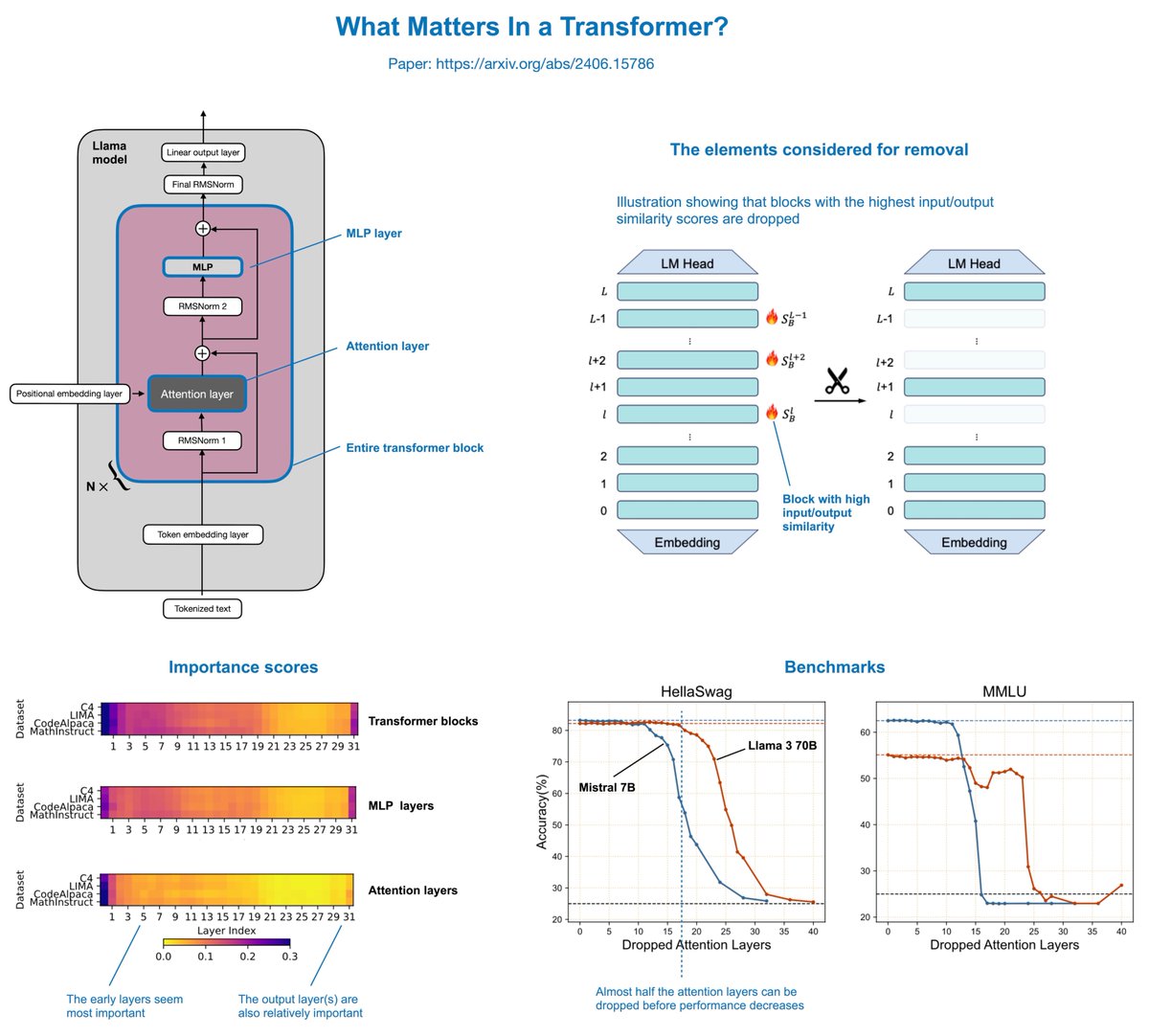
"What Matters In Transformers?" is an interesting paper (arxiv.org/abs/2406.15786) that finds you can actually remove half of the attention layers in LLMs like Llama without noticeably reducing modeling performance. The concept is relatively simple. The authors delete attention layers, MLP layers, or entire transformer blocks: - Removing entire transformer blocks leads to significant performance degradation. - Removing MLP layers results in significant performance degradation. - Removing attention layers causes almost no performance degradation! In Llama 2 70B, even if half of the attention layers are deleted (which results in a 48% speed-up), there's only a 2.4% decrease in the model benchmarks. The author also recently added Llama 3 results to the paper, which are similar. The attention layers were not removed randomly but based on a cosine-based similarity score: If the input and output are very similar, the layer is redundant and can be removed. This is a super intriguing result and could potentially be combined with various model compression techniques (like pruning and quantization) for compounding effects. Furthermore, the layers are removed in a one-shot fashion (versus iterative fashion), and no (re)training is required after the removal. However, retraining the model after the removal could potentially even recover some of the lost performance. Overall, a very simple but very interesting study. It appears there might be lots of computational redundancy in larger architectures. One big caveat of this study, though, is that the focus is mostly on academic benchmarks (HellaSwag, MMLU, etc.). It's unclear how well the models perform on benchmarks measuring conversational performance.

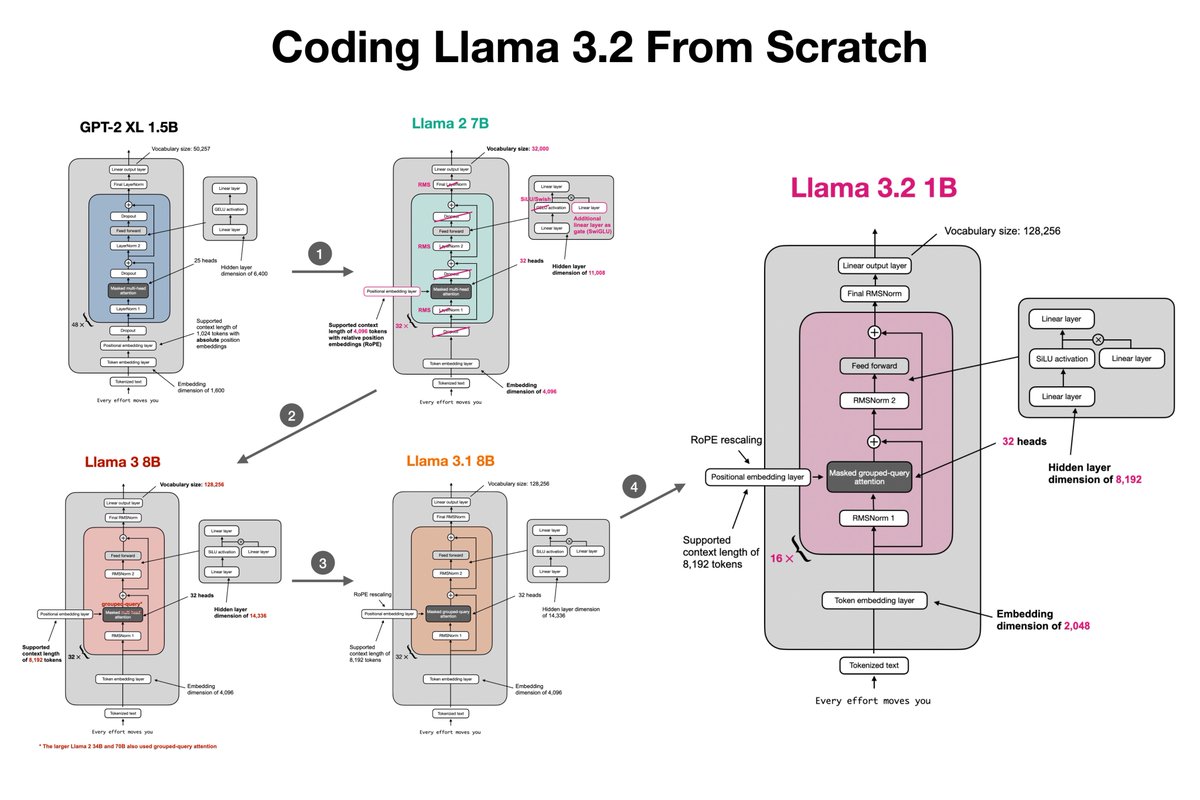
One of the best ways to understand LLMs is to code one from scratch! Last summer, I started working on a new book, "Build a Large Language Model (from Scratch)": manning.com/books/build-a-… I'm excited to share that the first chapters are now available via Manning's early access program if you are looking to read something over the holidays or pick up a new project in 2024! In short, in this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples. This includes Implementing the data preparation, sampling, and tokenization pipeline: 1. Coding multi-head attention from the ground up 2. Building and pretraining a GPT-like model 3. Learning how to load pretrained weights 4. Finetuning the model for classification 5. Instruction-finetuning the model with direct preference optimization PS: The code implementations are in PyTorch. Don't hesitate to reach out if you have any questions!
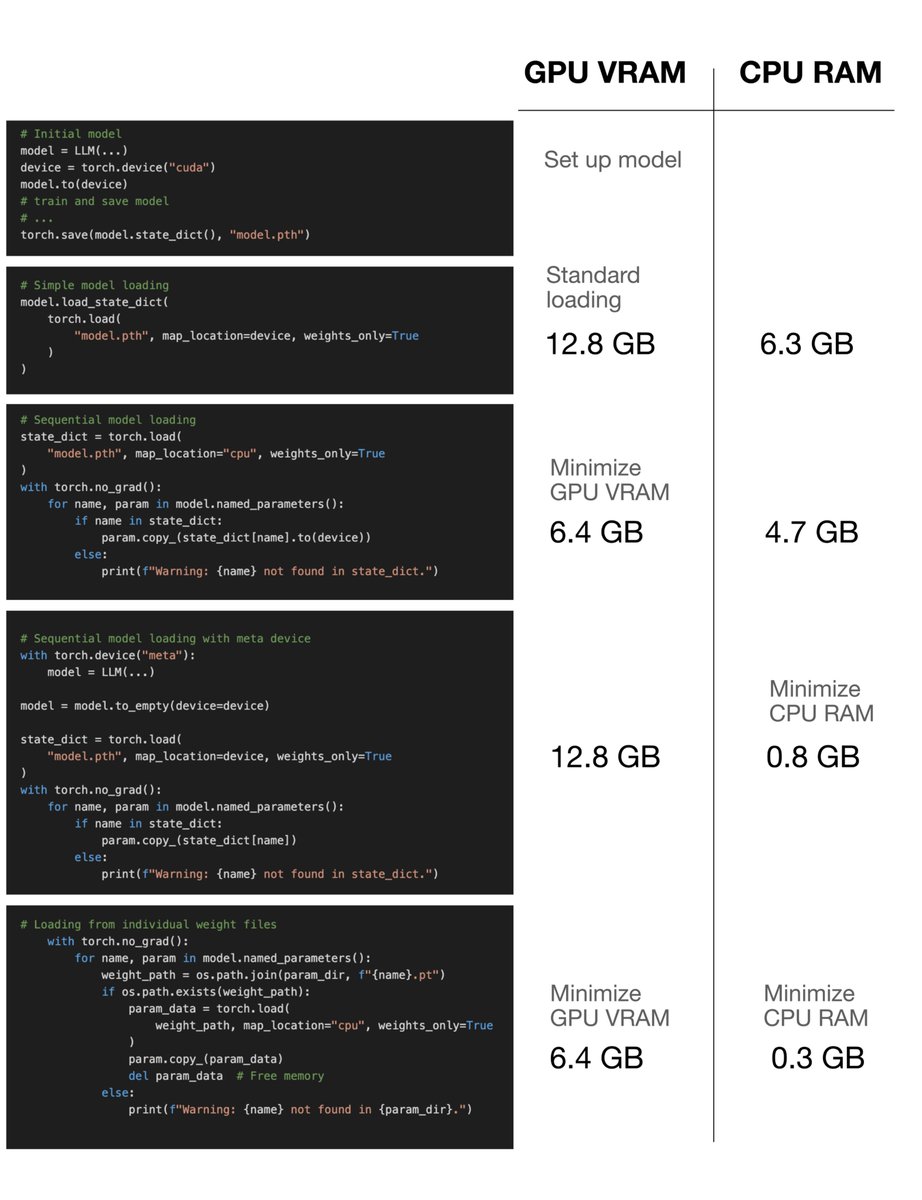

If you're getting into LLMs, PyTorch is essential. And lot of folks asked for beginner-friendly material, so I put this together: PyTorch in One Hour: From Tensors to Multi-GPU Training (sebastianraschka.com/teaching/pytor…) 📖 ~1h to read through 💡 Maybe the perfect weekend project!? I’ve spent nearly a decade using, building with, and teaching PyTorch. And in this tutorial, I try to distill what I believe are the most essential concepts. Everything you need to know to get started, and but nothing more, since your time is valuable, and you want to get to building things!


Most engaged tweets of Sebastian Raschka
One of the best ways to understand LLMs is to code one from scratch! Last summer, I started working on a new book, "Build a Large Language Model (from Scratch)": manning.com/books/build-a-… I'm excited to share that the first chapters are now available via Manning's early access program if you are looking to read something over the holidays or pick up a new project in 2024! In short, in this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples. This includes Implementing the data preparation, sampling, and tokenization pipeline: 1. Coding multi-head attention from the ground up 2. Building and pretraining a GPT-like model 3. Learning how to load pretrained weights 4. Finetuning the model for classification 5. Instruction-finetuning the model with direct preference optimization PS: The code implementations are in PyTorch. Don't hesitate to reach out if you have any questions!


"What Matters In Transformers?" is an interesting paper (arxiv.org/abs/2406.15786) that finds you can actually remove half of the attention layers in LLMs like Llama without noticeably reducing modeling performance. The concept is relatively simple. The authors delete attention layers, MLP layers, or entire transformer blocks: - Removing entire transformer blocks leads to significant performance degradation. - Removing MLP layers results in significant performance degradation. - Removing attention layers causes almost no performance degradation! In Llama 2 70B, even if half of the attention layers are deleted (which results in a 48% speed-up), there's only a 2.4% decrease in the model benchmarks. The author also recently added Llama 3 results to the paper, which are similar. The attention layers were not removed randomly but based on a cosine-based similarity score: If the input and output are very similar, the layer is redundant and can be removed. This is a super intriguing result and could potentially be combined with various model compression techniques (like pruning and quantization) for compounding effects. Furthermore, the layers are removed in a one-shot fashion (versus iterative fashion), and no (re)training is required after the removal. However, retraining the model after the removal could potentially even recover some of the lost performance. Overall, a very simple but very interesting study. It appears there might be lots of computational redundancy in larger architectures. One big caveat of this study, though, is that the focus is mostly on academic benchmarks (HellaSwag, MMLU, etc.). It's unclear how well the models perform on benchmarks measuring conversational performance.
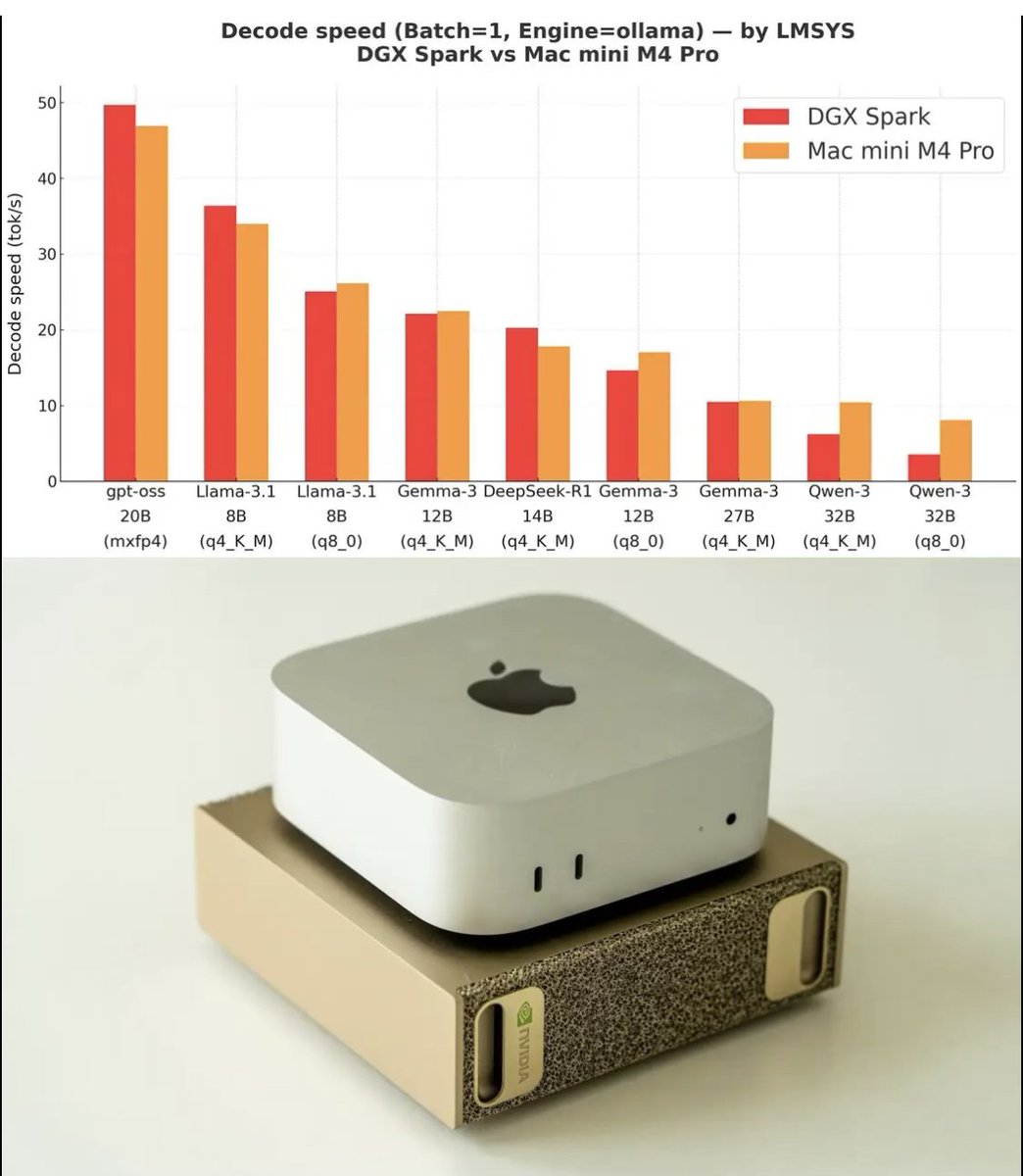
Saw that DGX Spark vs Mac Mini M4 Pro benchmark plot making the rounds (looks like it came from @lmsysorg). Thought I’d share a few notes as someone who actually uses a Mac Mini M4 Pro and has been tempted by the DGX Spark. First of all, I really like the Mac Mini. It’s probably the best desktop I’ve ever owned. For local inference with open-weight LLMs, it works great (the plot above captures that well). I regularly run the gpt-oss-20B model on it. That said, I would not fine-tune even small LLMs on it since it gets very hot. The DGX Spark probably targets that type of sustained workload. (From those who have one, any thoughts on the noise and heat levels?) The other big thing that DGX Spark gets you is CUDA support. If you use PyTorch, that’s pretty essential since MPS on macOS is still unstable, and fine-tuning often fails to converge. E.g., see github.com/rasbt/LLMs-fro… and github.com/rasbt/LLMs-fro… I also like the Spark’s for factor (hey, it really appeals to the Mac Mini user in me). But for the same money, I could probably buy about 4000 A100 cloud GPU hours, and I keep debating which would be the better investment. Sure, I could also build/get a multi-GPU desktop. I had a Lambda system with four GTX 1080 Ti cards back in 2018, but it was too loud and hot for my office. And if I have to move it to another room and SSH into it anyway, I might as well use cloud GPUs instead?

People with Innovator archetype
Open-source maximalist ᕕ( ᐛ )ᕗ
Turning product ideas into assets with AI—in hours, not months. Ex-Buffer PM & SaaS founder (with exit). Now building AlreadyLovedKids.com✨
New Hollywood - Ai Creative Technology
Accelerating Carbon Fiber Manufacturing.🦾 🧠:Deeptech, Simulation and Martial Arts🥋 Ex-Reliability Engineer @Tesla. 🚗 Its time to build! #technooptimist🚀
I talk about physical performance and cognitive enhancement. Build a body and mind that perform at their peak.
Building @relayprotocol // @wgtechlabs // Ex @thirdweb #ShippinginSilence 👀 🇵🇭 Deep into #AI, #opensource & #blockchain — follow if you #build in #tech 🤝
Staying degen until the next bull. Smart contracts, dumb jokes.
The chain to move what matters: value, data, and ideas for billions everywhere. X by Aptos Foundation.
Building AI for DevOps | ex-Palantir
Building AI Agents and Automating Workflows. Watch how I build them: youtube.com/@TheRecapAI Download all of my automations (for free)👇
Crypto & Web3 enthusiast | @megaeth🐇|
Planet Earth Live on Web3 & more ...
Explore Related Archetypes
If you enjoy the innovator profiles, you might also like these personality types: