Get live statistics and analysis of Tech with Mak's profile on X / Twitter

AI, coding, software, and whatever’s on my mind.
The Analyst
Tech with Mak is a deep-diving tech guru who unravels the complexities of AI, coding, and software development with clarity and precision. Their content is packed with insightful explanations and practical knowledge, perfect for both beginners and seasoned developers. Always ready to turn complex concepts into digestible knowledge nuggets, Mak makes tech approachable and engaging.
Top users who interacted with Tech with Mak over the last 14 days
Daily posts on AI , Tech, Programing, Tools, Jobs, and Trends | 500k+ (LinkedIn, IG, X) Collabs- abrojackhimanshu@gmail.com
Award winning AI Innovator with demonstrated solutions that can be adapted for enterprise use. Vision/Video Processing, Project Management, Retail Agents
Exploring AI, agentic systems, and the future of marketing. Breaking down the latest trends so you don’t get left behind. Follow for latest updates!!
AI Influencer | Helping you to make money with AI, Tech Tools & Digital Skills | DM for Exclusive Collaboration 💌 dilshadhussain2577@gmail.com
Imagine whatever you were expecting to see in my bio is written right here. Fair warning: I make jokes and they might be bad.
50K+ Audience on LinkedIn | AI Engineer | Resume Writer | AI Content Creator | AI Enthusiast | Influencer | DM for Promotion
Stop working harder. Automate smarter ⚡ AI tools • Workflow systems • Time freedom Free AI toolkit ↓
AI Educator. Helping you to make money with Al, Tech Tools & Digital Skills | DM for Collaboration ✨ | corpmarkg@gmail.com ✉️
I build stuff
AI Educator | Empowering you to generate income using AI tools and Digital. DM /Email Open for collaboration 📩
AI & Automation Technologist bringing Efficiency to the World 🚀 Building the Future of AI Organizations 📈 Scaling businesses via intelligent automations
unrivaled acuity combined with relentless tenacity renders me a formidable adversary in every sphere of human pursuit.
Tech with Mak: turning ‘too much info’ into a fine art — if only their tweets came with a TL;DR, even their followers might get a breather between brain cramps and code sprints.
Achieved massive engagement on tweets dissecting state-of-the-art AI concepts and software best practices, with multiple posts surpassing 150k views and thousands of likes and retweets, cementing their place as a trusted tech educator.
To educate and inform a broad audience about the intricacies of AI, software development, and system design, empowering others to build smarter tech solutions and master software engineering best practices.
Mak values accuracy, clarity, and continuous learning. They believe that complex problems become manageable when broken down systematically and presented transparently, and that sharing knowledge drives community growth.
Exceptional ability to analyze and clearly communicate sophisticated technical concepts, combined with consistent, data-backed content that boosts user engagement and trust.
Sometimes the technical depth might overwhelm casual followers who prefer lighter or more varied content; also, being heavily focused on explanations could limit personal storytelling that boosts relatability.
To grow their audience on X, Tech with Mak should complement technical deep dives with bite-sized tips, relatable anecdotes, or quick polls to spark conversation. Engaging more actively through replies and leveraging threads can turn followers into a community.
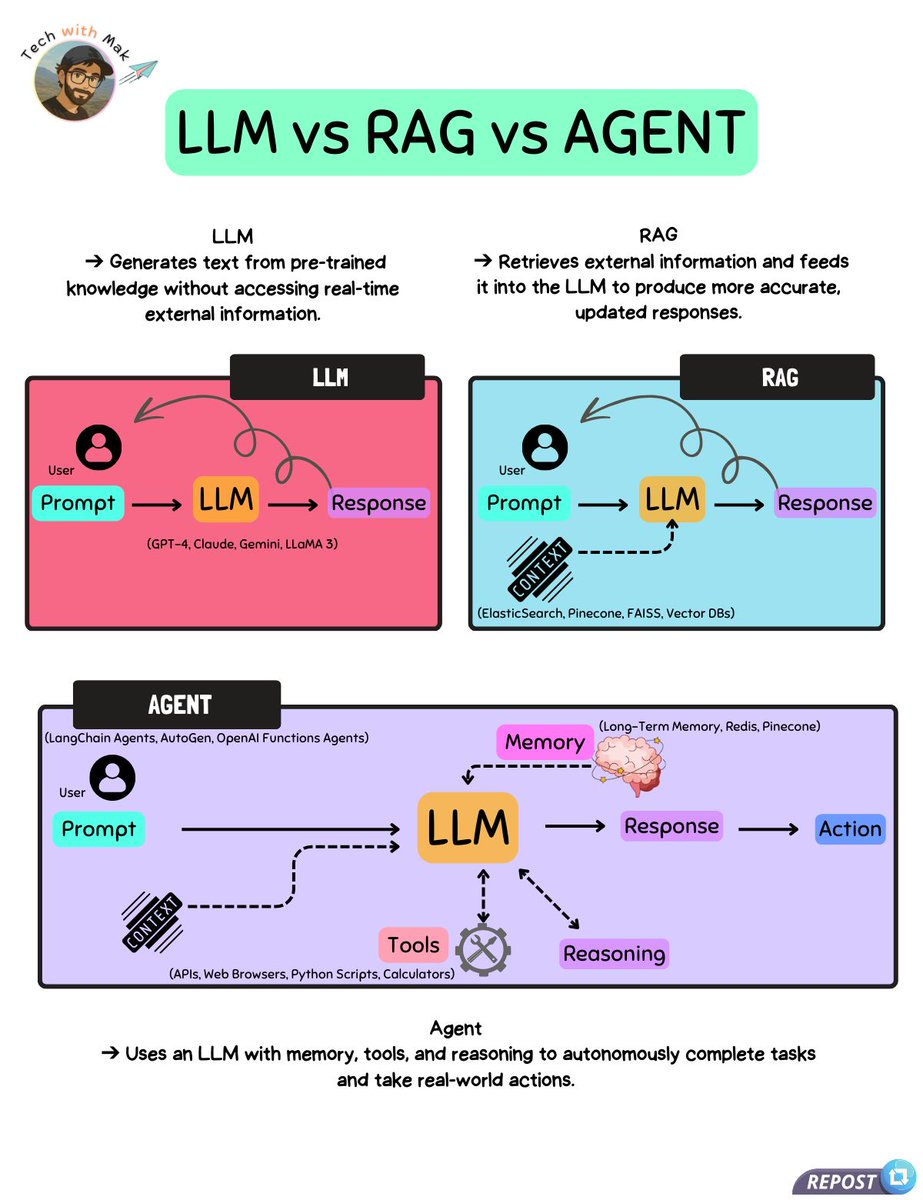
Mak's tweets often explain technical topics like LLMs, RAG, and Nginx's architecture in remarkable detail, demonstrating a knack for both technical depth and audience-friendly tone.
Top tweets of Tech with Mak


My doctor told me to reduce stress. I replaced Apache with Nginx. 😉 Nginx (pronounced "engine-x") -> - Web Server - Reverse Proxy - Load Balancer ⭐ NGINX is a reverse proxy load balancer, meaning it manages connections between clients and backend servers. ◾ It is free & open-source. ◾ It's renowned for its efficiency, stability and ability to handle massive loads concurrently. 𝐔𝐧𝐝𝐞𝐫 𝐭𝐡𝐞 𝐡𝐨𝐨𝐝 - ◾ At its heart, Nginx is an event-driven web server. ◾ It doesn't dedicate a thread to each incoming connection (like traditional models). ◾ Instead, it relies on a single (or a few) worker processes to manage multiple connections concurrently. ◾ Nginx utilizes a non-blocking I/O model - - Nginx uses => efficient system calls (like epoll on Linux ) => to watch multiple file descriptors (representing connections, sockets, etc.). - When a connection is ready, Nginx performs the read/write operation asynchronously. - It doesn't wait for the operation to complete. - Instead, it delegates the task to the 'operating system' and immediately moves on to handle other events. - When the asynchronous operation finishes, the operating system triggers a callback function in Nginx. - This callback then processes the data and potentially schedules more asynchronous operations. This enables NGINX to handle thousands of simultaneous connections with minimal resources. 𝐌𝐚𝐬𝐭𝐞𝐫 & 𝐖𝐨𝐫𝐤𝐞𝐫 𝐏𝐫𝐨𝐜𝐞𝐬𝐬𝐞𝐬 - ◾ The master process sets up the infrastructure (like listening sockets) and delegates the actual connection handling and request processing to the worker processes. ◾ Each worker process then runs its own independent event loop, utilizing the non-blocking I/O model. So, Worker processes does the actual heavy lifting of handling client requests and interacting with backend servers. ◾ This separation allows Nginx to handle numerous concurrent connections efficiently. Remember, Nginx strikes a balance between both approaches - # Worker Processes (Multi-Process) # Event-Driven Within Each Process (Not Multi-Threaded) (Inside each worker process, the event-driven, non-blocking model comes into play.) 𝐊𝐞𝐲 𝐅𝐮𝐧𝐜𝐭𝐢𝐨𝐧𝐚𝐥𝐢𝐭𝐢𝐞𝐬 - # Web Serving Nginx serves static content (HTML, CSS, images) efficiently. # Reverse Proxy Nginx forwards requests to backend servers while potentially adding security or caching functionalities. Can handle SSL/TLS termination (encryption/decryption). # Load Balancer (Layer 4 & 7) Nginx can distribute traffic across multiple backend servers using various algorithms (round-robin, least connections, etc.) Improves scalability and high availability. ------ Remember, ◾ Nginx performance can be impacted by long-running requests that block the event loop. ◾ For computationally intensive tasks, Nginx may benefit from using threads or offloading work to external processes. 😊 Follow - @techNmak , for more :)



LLM = Smart, but works only with what it was trained on. Its knowledge is fixed after training, and when it lacks relevant information, it may generate plausible-sounding but incorrect answers (“hallucinations”). RAG = Smart + can “look things up” in real time. It retrieves specific, relevant information from an external source and combines it with the LLM’s reasoning to give more accurate, up-to-date answers. Still, if retrieval is poor or ignored, hallucinations can happen. Agent = Smart + can “decide what to do next” to reach a goal. It reasons through problems, chooses and uses the right tools (like web search or APIs), and can optionally maintain memory of its steps. This enables it to handle complex tasks that require multiple actions. ---- Follow @techNmak

What is RAG? What is Agentic RAG? 𝐑𝐀𝐆 (𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥-𝐀𝐮𝐠𝐦𝐞𝐧𝐭𝐞𝐝 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐨𝐧) RAG connects a generation model to external knowledge through retrieval. Here’s how it works - 1./ A user submits a query. 2./ The system searches a pre-indexed set of documents (typically stored in a vector database). 3./ The most relevant chunks are retrieved. 4./ These chunks are appended to the original query. 5./ The combined input is sent for generation. The goal? To provide the model with context so it can generate more accurate, source-aware responses. But in traditional RAG, everything happens in a single pass - no planning, no evaluation, no retrying. ------ 𝐀𝐠𝐞𝐧𝐭𝐢𝐜 𝐑𝐀𝐆 Agentic RAG builds on the same foundation but introduces intelligent agents, each with a specific role - to improve the overall process. Instead of a single static pipeline, Agentic RAG becomes 𝐚 𝐦𝐮𝐥𝐭𝐢-𝐬𝐭𝐞𝐩, 𝐚𝐝𝐚𝐩𝐭𝐢𝐯𝐞 𝐬𝐲𝐬𝐭𝐞𝐦. Here's what it typically includes - 1./ A Planning Agent that breaks down the user query and decides what needs to be retrieved. 2./ A Retrieval Agent that reformulates the query (if needed) and pulls in information, not just from documents, but potentially from APIs, tools, or dynamic sources. 3./ A Generator Agent that constructs a response using the retrieved data. 4./ A Judge or Evaluation Agent that reviews the output. If it’s not good enough, the system can refine its plan or regenerate the answer. This setup allows for - - Iterative reasoning - Self-correction - Tool integration - Dynamic, context-aware responses ------------ Follow @techNmak


My doctor told me to reduce stress. I replaced Apache with Nginx. 😉 Nginx (pronounced "engine-x") -> - Web Server - Reverse Proxy - Load Balancer ⭐ NGINX is a reverse proxy load balancer, meaning it manages connections between clients and backend servers. ◾ It is free & open-source. ◾ It's renowned for its efficiency, stability and ability to handle massive loads concurrently. 𝐔𝐧𝐝𝐞𝐫 𝐭𝐡𝐞 𝐡𝐨𝐨𝐝 - ◾ At its heart, Nginx is an event-driven web server. ◾ It doesn't dedicate a thread to each incoming connection (like traditional models). ◾ Instead, it relies on a single (or a few) worker processes to manage multiple connections concurrently. ◾ Nginx utilizes a non-blocking I/O model - - Nginx uses => efficient system calls (like epoll on Linux ) => to watch multiple file descriptors (representing connections, sockets, etc.). - When a connection is ready, Nginx performs the read/write operation asynchronously. - It doesn't wait for the operation to complete. - Instead, it delegates the task to the 'operating system' and immediately moves on to handle other events. - When the asynchronous operation finishes, the operating system triggers a callback function in Nginx. - This callback then processes the data and potentially schedules more asynchronous operations. This enables NGINX to handle thousands of simultaneous connections with minimal resources. 𝐌𝐚𝐬𝐭𝐞𝐫 & 𝐖𝐨𝐫𝐤𝐞𝐫 𝐏𝐫𝐨𝐜𝐞𝐬𝐬𝐞𝐬 - ◾ The master process sets up the infrastructure (like listening sockets) and delegates the actual connection handling and request processing to the worker processes. ◾ Each worker process then runs its own independent event loop, utilizing the non-blocking I/O model. So, Worker processes does the actual heavy lifting of handling client requests and interacting with backend servers. ◾ This separation allows Nginx to handle numerous concurrent connections efficiently. Remember, Nginx strikes a balance between both approaches - # Worker Processes (Multi-Process) # Event-Driven Within Each Process (Not Multi-Threaded) (Inside each worker process, the event-driven, non-blocking model comes into play.) 𝐊𝐞𝐲 𝐅𝐮𝐧𝐜𝐭𝐢𝐨𝐧𝐚𝐥𝐢𝐭𝐢𝐞𝐬 - # Web Serving Nginx serves static content (HTML, CSS, images) efficiently. # Reverse Proxy Nginx forwards requests to backend servers while potentially adding security or caching functionalities. Can handle SSL/TLS termination (encryption/decryption). # Load Balancer (Layer 4 & 7) Nginx can distribute traffic across multiple backend servers using various algorithms (round-robin, least connections, etc.) Improves scalability and high availability. ------ Remember, ◾ Nginx performance can be impacted by long-running requests that block the event loop. ◾ For computationally intensive tasks, Nginx may benefit from using threads or offloading work to external processes. 😊 Follow - @techNmak , for more :)


🚀 RAG has evolved far beyond its original form. When people hear Retrieval-Augmented Generation (RAG), they often think of the classic setup: retrieve documents → feed into LLM → generate an answer. But in practice, RAG has branched into many specialized patterns, each designed to solve different challenges around accuracy, latency, compliance, and context. Here are some of the most important categories: ➤ Standard RAG - the original retrieval + generation (RAG-Sequence, RAG-Token). ➤ Graph RAG - connects LLMs with knowledge graphs for structured reasoning. ➤ Memory-Augmented RAG - external memory for long-term context. ➤ Multi-Modal RAG - retrieves across text, images, audio, video. ➤ Streaming RAG - real-time retrieval for live data (tickers, logs). ➤ ODQA RAG - open-domain QA, one of the earliest and most popular uses. ➤ Domain-Specific RAG - tailored retrieval for legal, healthcare, or finance. ➤ Hybrid RAG - combines dense + sparse retrieval for higher recall. ➤ Self-RAG - lets the model reflect and refine before final output (Meta AI, 2023). ➤ HyDE (Hypothetical Document Embeddings) - improves retrieval by first generating “mock” documents to embed. ➤ Recursive / Multi-Step RAG - multi-hop retrieval + reasoning chains. Others like Agentic RAG, Modular RAG, Knowledge-Enhanced RAG, Contextual RAG are best thought of as system design patterns, not strict categories, but useful extensions for specific use cases. 📊 The image below maps out 16 different types of RAG, their features, benefits, applications, and tooling examples. 👉 Whether you’re building production-grade assistants, domain-specific copilots, or real-time monitoring systems, the right flavor of RAG can make all the difference. ---------- Follow @techNmak






Most engaged tweets of Tech with Mak

I am a Senior Engineer with over 11+ years of experience (77K+ on LinkedIn) and would love to #connect with people who are interested in: - Software Engineering - Data Engineering - Content Creation - Frontend - Backend - Full-stack - MobileDevelopment - GoogleCloud - Azure - AWS - AI & Machine Learning - ReactJS/NextJS - OpenSource - UI/UX - Freelancing #letsconnect #buildinpublic

I want to #connect with people who are interested in: - Software Engineering - Data Engineering - Content Creation - Frontend - Backend - Full-stack - MobileDevelopment - GoogleCloud - Azure - AWS - AI & Machine Learning - ReactJS/NextJS - OpenSource - UI/UX - Freelancing #letsconnect #buildinpublic
The Python ecosystem has a new standard, and it's called uv. From the creators of ruff, uv is an all-in-one "Cargo for Python" written in Rust, and it is a massive leap forward. It’s not just "a faster pip." It’s a single, cohesive tool designed to replace an entire collection of tools: pip, pip-tools, venv, virtualenv, pipx, bump2version, build, and twine. The performance gains are staggering (often 10-100x faster), but the real insight is the unified workflow. Here is the overview of what makes uv a true game-changer for any Python developer. 1./ The complete project lifecycle This is what sets uv apart. It's not just an installer; it handles your entire workflow from start to finish. You can now use one tool to - ☛ Initialize: uv init ☛ Manage dependencies: uv add, uv rm, uv sync ☛ Bump versions: uv version --bump patch ☛ Build: uv build ☛ Publish: uv publish This unified lifecycle is a massive boost to developer experience. 2./ Beyond-project: tools & scripts uv also replaces specialized tools like pipx and pip-run: ☛ Tool Management: uv tool install ruff installs ruff into its own isolated, managed environment. No more global site-package pollution. ☛ Script Running: uv run myscript(.)py can execute a script, read its dependencies from inline comments (# uv: requests), and run it in a temporary, on-the-fly environment. 3./ Core speed & sanity At its heart, uv is a blazing-fast resolver and installer. This is all thanks to: ☛ Rust Core: Native, parallelized operations. ☛ Global Cache: Dependencies are shared across all your projects, saving gigabytes of disk space and making new environment creation almost instant. ☛ Python Management: uv python install 3.12 provides a built-in, simple way to fetch and manage Python versions. uv is one of the most significant advancements in Python tooling in the last decade. It simplifies our stack, saves us time, and brings a level of cohesion to the ecosystem we've long needed. ------- Follow @techNmak for more such insights. Check this cheatsheet by rodrigo girão serrão

You don’t really know your code until it runs in production. And when it does, things often behave… differently. You write clean code. You test it. You ship it. And then, in prod, things go sideways. Sometimes subtly. Sometimes in ways no one saw coming. It’s not because you missed something. It’s just that once code hits the real world, with actual traffic, edge cases, timing issues, everything changes. That’s where Hud comes in. Hud captures how your code actually behaves in production, and puts that context right where you need it. No logs to sift through. No dashboards to stare at. Just a live view of how your code is really behaving, right inside your IDE. Sometimes you’re writing code. Sometimes the Copilot or Cursor is doing it. Either way, Hud sits in the background and surfaces the stuff you usually only find after things break. ✅ One-line install ✅ Shows root causes, not just alerts ✅ Zero config, zero maintenance If “it worked locally” has ever turned into a fire drill in prod, this solves that. Here is the link → hud.io
What is RAG? What is Agentic RAG? 𝐑𝐀𝐆 (𝐑𝐞𝐭𝐫𝐢𝐞𝐯𝐚𝐥-𝐀𝐮𝐠𝐦𝐞𝐧𝐭𝐞𝐝 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐨𝐧) RAG connects a generation model to external knowledge through retrieval. Here’s how it works - 1./ A user submits a query. 2./ The system searches a pre-indexed set of documents (typically stored in a vector database). 3./ The most relevant chunks are retrieved. 4./ These chunks are appended to the original query. 5./ The combined input is sent for generation. The goal? To provide the model with context so it can generate more accurate, source-aware responses. But in traditional RAG, everything happens in a single pass - no planning, no evaluation, no retrying. ------ 𝐀𝐠𝐞𝐧𝐭𝐢𝐜 𝐑𝐀𝐆 Agentic RAG builds on the same foundation but introduces intelligent agents, each with a specific role - to improve the overall process. Instead of a single static pipeline, Agentic RAG becomes 𝐚 𝐦𝐮𝐥𝐭𝐢-𝐬𝐭𝐞𝐩, 𝐚𝐝𝐚𝐩𝐭𝐢𝐯𝐞 𝐬𝐲𝐬𝐭𝐞𝐦. Here's what it typically includes - 1./ A Planning Agent that breaks down the user query and decides what needs to be retrieved. 2./ A Retrieval Agent that reformulates the query (if needed) and pulls in information, not just from documents, but potentially from APIs, tools, or dynamic sources. 3./ A Generator Agent that constructs a response using the retrieved data. 4./ A Judge or Evaluation Agent that reviews the output. If it’s not good enough, the system can refine its plan or regenerate the answer. This setup allows for - - Iterative reasoning - Self-correction - Tool integration - Dynamic, context-aware responses ------------ Follow @techNmak
Software is changing. So is debugging. Before: ⇨ Print statements everywhere ⇨ Hoping the error shows up ⇨ Restarting the app 15 times ⇨ Fixing one thing, breaking another ⇨ Forgetting what you changed ⇨ Giving up and rewriting the whole function Then: ⇨ Real debuggers ⇨ git bisect ⇨ Restarting the app 15 times ⇨ Log inspection ⇨ Writing a test… maybe ⇨ Pair debugging with a tired teammate But you were still doing most of the work. Now: You make a request. Lovable (@lovable_dev) Agent does the rest - ⇨ Reads the right files ⇨ Traces the logic ⇨ Checks the logs ⇨ Finds the root cause ⇨ Plans a fix ⇨ Applies it ⇨ Summarizes the change It figures things out, just like a great engineer would. Crazy times. —- P.S. Lovable is also providing us with a guide to build web apps easily. Like + Comment ‘Lovable’ and I’ll share the link.

AI Agents Cheat Sheet ------------ This is a good starting point if you're trying to make sense of AI agents. There’s a lot of talk about agent frameworks right now, but at the core, most of them build on the same set of ideas. This cheat sheet gives a simple overview of the key building blocks, from LLMs to orchestration to protocols. Useful whether you’re exploring agent tooling, building internal automations, or just trying to understand the space better. What is an AI agent? - Agents combine reasoning with the ability to take action. - They don’t just respond, they can plan, call tools, access data, and trigger real-world effects. Language Model - This is the core reasoning engine. It interprets input and generates plans or responses. - But by itself, it can’t take real-world actions. Tools - APIs, functions, and external integrations that agents use to do useful work, like querying a database, sending an email, or calling a webhook. Orchestration Layer - This layer coordinates what the agent does, how it reasons (via CoT, ReAct, etc.), how it sequences steps, and how it interacts with tools. Agentic Protocols - Protocols like MCP and A2A enable agents to collaborate across platforms (e.g., Slack, GitHub) and maintain context across tasks. Building AI Agents - There’s no single way to build an agent. - Some start with a single prompt. Others use low-code platforms. Some teams build full custom frameworks. The cheat sheet maps out the trade-offs. If you’re trying to understand the agent space, or explain it to your team, this breakdown might help. Save it if you want a reference to come back to. ----------- Follow @techNmak

LLM Generation Parameters These are the primary controls used to influence the output of a Large Language Model. 1./ Temperature ◾ Controls the randomness of the output. It is applied to the probability distribution of the next possible tokens. ◾ Low Temperature (e.g., 0.2): Makes the output more deterministic and focused. The model will almost always select the most probable next token. (ideal for factual tasks like summarization, code generation, and direct Q&A) ◾ High Temperature (e.g., 1.0): Makes the output more random and creative. The model is more likely to select less probable tokens, leading to more diverse and novel text. (useful for creative writing, brainstorming, and open-ended conversation) 2./ Top-p ◾ Controls randomness by selecting from a dynamic subset of the most probable tokens. The model considers the smallest set of tokens whose cumulative probability is greater than or equal to the p value. ◾ Ex: If top_p is 0.9, the model considers only the tokens that make up the top 90% of the probability mass for the next choice, discarding the remaining 10%. ◾ It provides a good balance between randomness and preventing the model from choosing bizarre or nonsensical tokens. It is often recommended as an alternative to temperature. 3./ Top-k ◾ Controls randomness by restricting the model's choices to the k most likely next tokens. ◾ Ex: If top_k is 50, the model will only consider the 50 most probable tokens for its next selection, regardless of their combined probability. ◾ It prevents very low-probability tokens from being selected, which can make the output more coherent and less erratic than high-temperature sampling alone. 4./ Max Length / Max New Tokens ◾ This parameter sets a hard limit on the number of tokens (words or word pieces) the model can generate in a single response. ◾ It is essential for controlling response length, managing computational costs, and preventing runaway or endlessly rambling outputs. 5./ Frequency Penalty ◾ A value (typically between -2.0 and 2.0) that penalizes tokens based on how often they have already appeared in the generated text so far. ◾ + Value (e.g., 0.5): Decreases the likelihood of the model repeating the exact same words, encouraging more linguistic variety. ◾ Zero Value (0.0): No penalty is applied. 6./ Presence Penalty ◾ A value (typically between -2.0 and 2.0) that penalizes tokens simply for having appeared in the text at all, regardless of their frequency. ◾ + Value (e.g., 0.5): Encourages the model to introduce new concepts and topics, as it is penalized for reusing any token, even once. ◾ This is particularly useful for preventing the model from getting stuck on a single idea or topic. 7. / Stop Sequences ◾ A user-defined string or list of strings that will immediately stop the generation process if the model produces it. ◾ It is crucial for controlling the structure of the output, creating formatted text, or simulating conversational turn-taking. Follow - @techNmak

People with Analyst archetype
Insights on web3 with an d-absurd approach. Your favorite KOL's ghostwriter ✍️ Advocate @Seraph_global | SMM @Atleta_Network | Prev. @DexCheck_io
研究向导 |空投猎人 |空投教程 | 空投优质信息 |热衷研究新事物|挖矿|土狗爱好者|打新|Gamefi|DeFi|NFT|撸毛|WEB3|DM for Colla|VX: jya777222
Product Designer & AI Explorer Crafting UI/UX for blockchain Sharing tech insights|Learn in public Open to new projects and collaborations🪄
crypto enthusiast,
Bitcoin, Materials Science PhD ⚡️ Analytics, tools, and guides ⚡️ Bitcoin Data Lounge Host
Crypto comms pro 🗣️ | Alpha @cookiedotfun 🍪 | Building @BioProtocol 🧬 | Hyping @KaitoAI 🤖 | Growing @wallchain_xyz 🚀 | DeSci & AI fan 🌐 #Web3
Chief scientist at Redwood Research (@redwood_ai), focused on technical AI safety research to reduce risks from rogue AIs
Crypto enthusiast || Content writer || Mathematician || God over all… pfp - @doginaldogsx
Advisor at @StudioYashico Artist behind @cubescrew
每日alpha研究,专注套利、空投 @Polymarket 观察、研究 所有内容发的内容都是思考与记录,非投资建议
都来web3了,有什么辛苦可说,什么都撸,从不偏见! 2025提高效率,一起暴富 ,加入滑翔机,一起探索 AIFI @glider_fi
Research @carnegiemellon | Building CollabSphere.ai and PE AI native platform | prev @Dream11
Explore Related Archetypes
If you enjoy the analyst profiles, you might also like these personality types: