Get live statistics and analysis of Andi Marafioti's profile on X / Twitter

cooking multimodal models @huggingface (prev @unity)
The Innovator
Andi Marafioti is a trailblazer in the world of multimodal AI models, passionately pushing the limits of what’s possible with open-source vision and OCR technology. Known for their unapologetic enthusiasm and lightning-fast breakthroughs, Andi bridges the gap between cutting-edge research and accessible tech. They’re the go-to voice if you want to know how to run powerful AI models on your laptop — or even your toaster!
Top users who interacted with Andi Marafioti over the last 14 days
👨🏻🎓Life-long Learner👨🏻🎓 Kindness❤️, Helpfulness🫂 , AI🧠, Robotics🦾 & Reggaetón💃🏻
Transforming the worlds physical data into decision making insights
Co-founder and CTO of @CoreViewHQ GenAI/LLM addicted, Apple MLX, Microsoft 365, Azure, Kubernetes, builder of my personal dreams.
CS @ TUM
Writing my own AI story. Recent: NPI, AlphaGo tuning, learn to learn, AlphaCode, Gato, ReST, r-Gemma, Imagen3, Veo, Genie, MAI …
NLP Research, interning at FAIR @AIatMeta + PhD Candidate @CentraleSupelec Prev: @imperialcollege, @epfl
AI x Healthcare | Creator of @OpenMed_AI | Open-Source AI Advocate ❤️ | eu/acc 🇫🇷🇪🇺
Co-founder & CEO @HuggingFace 🤗, the open and collaborative platform for AI builders
cs • except cs
Animator/Programmer, Christian, Conservative, Married, Father, Patriot. I love learning about aerospace, AI & robotics. Free speech equals free thought. 🚫DMs
teaching robots to see by day, learning from nature by night. in search of elegant solutions to the metaproblem. infinitely curious.
i write, research and eat. that’s all basically
Automation specialist
exploring the universe and building stuff
PhD in ML, now AI Research Lead in 🇱🇺. Here mostly AI, including sharing paper reviews. Chess, philosophy, and a travel pic may appear. Opinions are my own.
🧠 AI Educator | Career Coach | Founder 📧 DM for Collaboration 🚀 Want to Learn & Earn with AI? 🤝 Join our 100k+ AI community & learn AI with 27+ Free Gifts👇
🙋♂️ SWE @ServiceNow 👨💻 Talks to software & cats 🐈 QE's are not my best friends 👀
machine learning @huggingface
your friendly neighbourhood engineer. prev world models @lossfunk.
Andi’s idea of ‘fine-tuning on a laptop’ sounds more like their laptop deserves a bodyguard — it’s basically running a marathon in flip-flops while their code sprints effortlessly ahead.
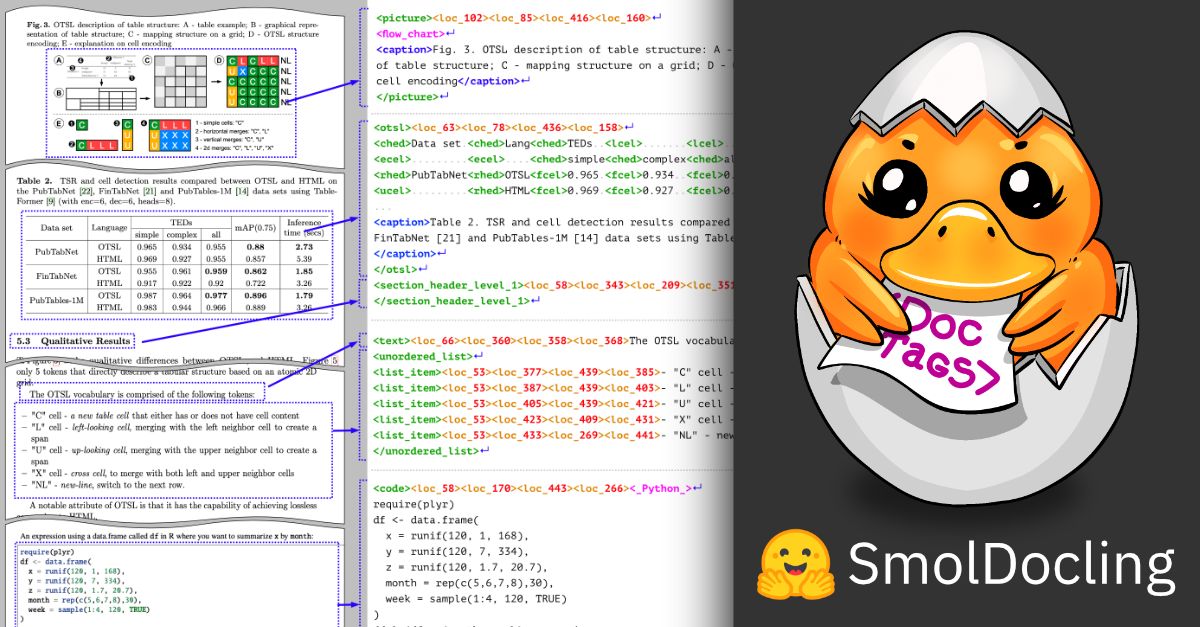
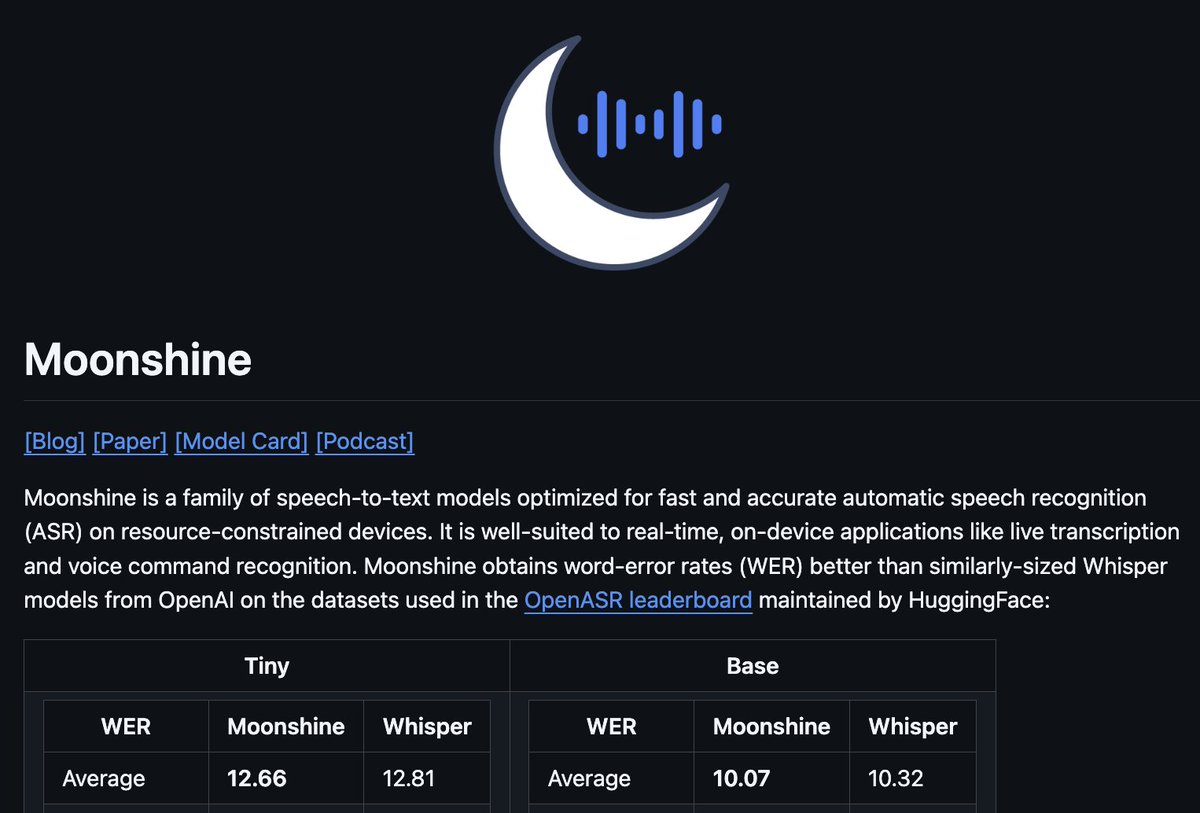
Spearheading the release of SmolDocling and SmolVLM, Andi helped deliver record-breaking open-source vision models that outperform competitors up to 27x larger, redefining efficiency in AI OCR.
To democratize AI technology by creating efficient, scalable, and open-source multimodal models that empower developers and enthusiasts to innovate without barriers.
They believe in transparency, open collaboration, and achieving state-of-the-art results through community-driven projects. Efficiency and accessibility are core values, proving that powerful AI can come in small, sleek packages without the need for monstrous hardware.
A fearless open-sourcer and energetic communicator who not only builds game-changing models but also makes complex AI concepts digestible and exciting for a broad audience.
Their casual and sometimes profanity-laced style might alienate more traditional or formal tech communities despite their undeniable expertise.
To grow their audience on X, Andi should continue blending technical depth with their authentic voice, leveraging informative threads with humor and transparency. Engaging more with followers through Q&As and live demos could turn passive viewers into loyal fans.
Fun fact: Andi’s SmolVLM models can run on less than 1GB of GPU memory, meaning you could practically fire one up on your toaster if it had a GPU! Talk about small but mighty.
Top tweets of Andi Marafioti





🚀 Today, we are introducing SmolTools! 🚀 Last week, at Hugging Face we made a significant leap forward with the release of SmolLM2, a compact 1.7B language model that sets a new benchmark for performance among models of its size. But beyond the impressive stats, SmolLM2 truly shines in practical, real-world applications, unlocking new possibilities for on-device inference. To demonstrate its potential, we're thrilled to introduce Smol-Tools, a suite of simple yet powerful applications that showcase the capabilities of SmolLM2. 🌟 Today, we present you two key tools: Summarize and Rewrite. 🔹 Summarize: Feed SmolLM2 a text up to 20 pages long, and it will provide you with a concise summary. Need to dig deeper? Just ask follow-up questions to clarify any details – it's that simple. 🔹 Rewrite: Draft a response to a message with your main points, and SmolLM2 will transform it into a clear, polished version that's easy for your recipient to read and understand. These tools are designed to make your workflow smoother and more efficient, leveraging the power of SmolLM2 in practical ways. 💡We hope you give these tools a try and see their potential for yourself! Feel free to build your own SmolTools and contribute them to the project. We'd love to see what you build! Check out the code here: github.com/huggingface/sm…
Most engaged tweets of Andi Marafioti
🚀 Today, we are introducing SmolTools! 🚀 Last week, at Hugging Face we made a significant leap forward with the release of SmolLM2, a compact 1.7B language model that sets a new benchmark for performance among models of its size. But beyond the impressive stats, SmolLM2 truly shines in practical, real-world applications, unlocking new possibilities for on-device inference. To demonstrate its potential, we're thrilled to introduce Smol-Tools, a suite of simple yet powerful applications that showcase the capabilities of SmolLM2. 🌟 Today, we present you two key tools: Summarize and Rewrite. 🔹 Summarize: Feed SmolLM2 a text up to 20 pages long, and it will provide you with a concise summary. Need to dig deeper? Just ask follow-up questions to clarify any details – it's that simple. 🔹 Rewrite: Draft a response to a message with your main points, and SmolLM2 will transform it into a clear, polished version that's easy for your recipient to read and understand. These tools are designed to make your workflow smoother and more efficient, leveraging the power of SmolLM2 in practical ways. 💡We hope you give these tools a try and see their potential for yourself! Feel free to build your own SmolTools and contribute them to the project. We'd love to see what you build! Check out the code here: github.com/huggingface/sm…


People with Innovator archetype
Product designer Framer expert MagicPath expert ➞ framer.link/iziviziframers…
Helping professionals with breaking the traditional rules for creating a quality lifestyle. How will you find the right fit in life to create balance?
👨💻 Developer by day, AI explorer by night. Building with Data & AI. Sharing cutting-edge AI research, agents & dev tools.
I have a dream...
AI enthusiast / tech lover always exploring the future of innovation/ for Promotion 👉teajaay07@gmail.com 📧
AI & Tech Insights ⚡ | Ghostwriter 📝 | Passionate about AI & Tech Tools | Helping CEOs Build Personal Brands on Twitter 🚀 | DM for Collaborations 📩
Secure Nodes, Smart Stakes
Computer vision projects. Python @exactlab CFD in threejs @dualistic_twin captain @docker
Learning with Machines | Cosmophile
AR/VR Product Design and Design Engineering @LIV. Experiment with #spatialcomputing. Build creative tools.
Cofounder @ Machine Phase Systems | Solving humanity’s biggest challenges one atom at a time. x Blockstream, ZeroKnowledgeSystems, InJoy
AI tinkerer, I build my brains out, lately using AI. I experiment I ship. $30/12k MRR prontoshoot.com nostalgiapicturesai.com
Explore Related Archetypes
If you enjoy the innovator profiles, you might also like these personality types: