Get live statistics and analysis of Aurimas Griciūnas's profile on X / Twitter

🔨 Founder & CEO @ SwirlAI 📖 Writing about #LLM, #AI, #DataEngineering, #MachineLearning and #Data ✍️ Author of SwirlAI Newsletter.
The Thought Leader
Aurimas Griciūnas is a tech-savvy visionary at the forefront of AI and Data Engineering, blending deep technical expertise with a passion for community education. As the Founder & CEO of SwirlAI and author of its newsletter, Aurimas offers rich insights into LLMs, machine learning, and data system intricacies, guiding professionals to master these complex topics. His content demystifies advanced AI concepts with clarity, making him a trusted source in the data and AI space.
Top users who interacted with Aurimas Griciūnas over the last 14 days
Oh🔰 my god, there has to be something to do, not just watching, right?🫧
Follow me for recipes.
Daily posts on AI , Tech, Programing, Tools, Jobs, and Trends | 500k+ (LinkedIn, IG, X) Collabs- abrojackhimanshu@gmail.com
CEO & Founder of @gtechinnovation, inc • Crypto investor 🇩🇴 behind @onetimedocs #OTDC • @onetimehhcsoft
Decentralized AI Trust & Security. Certify AI on-chain. Web3 for AI, AI for Web3. $DAITS tge is coming
Research Fellow & PhD in Machine Learning @ai_ucl. Founder @VectifyAI.
Co-founder, @epicuri_ai. Building AI + web3. Recovering armored cavalry officer. Combat veteran. @aptos alum.
Exploring AI, agentic systems, and the future of marketing. Breaking down the latest trends so you don’t get left behind. Follow for latest updates!!
Founder and CEO of Z360
Software Engineer | LLMs loooooove @shedboxai
У всякого из нас имеются иллюзии, которые он не хотел бы разрушать.
CTO and Co-Founder, @hanselmedical. In to all things AI, tech, dev, product - as well as nerd stuff; trains, planes, Lego, photography.
“When you know how to listen, everybody is the guru.” Pro North American Confederation
Love - Building | Startups | 🎵 ARR & Raja | 🦁 CSK - getpullrequest.com - getdialo.com - trata.ai
Biologitechnologist
SRE @ Zomato, Tech | Music | Games, I talk to computers more than humans.
Solopreneur ADHD mode: building 15 projects in parallel.
Aurimas tweets so much about AI memory and protocols that even his Twitter feed might start wondering if it has short-term or long-term memory—no worries, you’ve got enough knowledge stored to fill dozens of AI brains!
Aurimas’ top-performing tweet comparing Google's MCP and A2A protocols attracted nearly 200K views and thousands of likes, marking a standout achievement in establishing him as a go-to thought leader on multi-agent AI communication.
Aurimas's life purpose is to bridge the gap between complex AI technologies and accessible knowledge, empowering the broader tech community to innovate and implement cutting-edge solutions confidently. He strives to foster an informed and skilled data ecosystem by sharing clear, practical insights and nurturing a community of learners and innovators.
Aurimas believes in the transformative power of knowledge sharing, interdisciplinary learning, and systems thinking as foundational pillars for technological progress. He values clarity, precision, and practical application of data science and AI, championing continuous learning to keep pace with rapidly evolving fields. Collaboration and openness in developing standards, like protocols in AI agent communication, reflect his belief in community-driven innovation.
Aurimas’s greatest strengths lie in his authoritative expertise, ability to simplify complex AI and data topics, and his engaging, data-backed communication style that drives meaningful discourse. His deep understanding of AI agents and protocols positions him as a forward-thinking influencer who inspires trust and learning.
Sometimes, his deep technical focus might drift toward verbosity that can overwhelm newcomers, and his strong analytical style may hall pass the more casual or entertainment-driven audience on fast-moving platforms like X.
To grow his audience on X, Aurimas should weave in more storytelling elements and bite-sized 'tech snack' threads that spark curiosity while maintaining depth. Engaging more interactively — like running polls, Q&A sessions, or relatable real-world AI use cases — can broaden appeal beyond hardcore experts while retaining his loyal followers.
Fun fact: Aurimas is not just a theorist but a hands-on builder, actively developing agentic AI systems from scratch and sharing every step to help others do the same—no magic frameworks required!
Top tweets of Aurimas Griciūnas

𝗠𝗖𝗣 𝘃𝘀. 𝗔𝟮𝗔 Two days ago Google announced an open A2A (Agent2Agent) protocol in an attempt to normalise how we implement multi-Agent system communication. As always, social media is going crazy about it, but why? Let’s review the differences and how both protocols complement each other (read till the end). 𝘔𝘰𝘷𝘪𝘯𝘨 𝘱𝘪𝘦𝘤𝘦𝘴 𝘪𝘯 𝘔𝘊𝘗: 𝟭. MCP Host - Programs using LLMs at the core that want to access data through MCP. ❗️ When combined with A2A, an Agent becomes MCP Host. 𝟮. MCP Client - Clients that maintain 1:1 connections with servers. 𝟯. MCP Server - Lightweight programs that each expose specific capabilities through the standardized Model Context Protocol. 𝟰. Local Data Sources - Your computer’s files, databases, and services that MCP servers can securely access. 𝟱. Remote Data Sources - External systems available over the internet (e.g., through APIs) that MCP servers can connect to. 𝘌𝘯𝘵𝘦𝘳 𝘈2𝘈: Where MCP falls short, A2A tries to help. In multi-Agent applications where state is not necessarily shared 𝟲. Agents (MCP Hosts) would implement and communicate via A2A protocol, that enables: ➡️ Secure Collaboration - MCP lacks authentication. ➡️ Task and State Management. ➡️ User Experience Negotiation. ➡️ Capability discovery - similar to MCP tools. 𝗛𝗼𝗻𝗲𝘀𝘁 𝘁𝗵𝗼𝘂𝗴𝗵𝘁𝘀: ❗️ I believe creators of MCP were planning to implement similar capabilities to A2A and expose agents via tools in long term. ❗️ We might just see a fight around who will win and become the standard protocol long term as both protocols might be expanding. Let me know your thoughts in the comments. 👇 #LLM #AI #MachineLearning
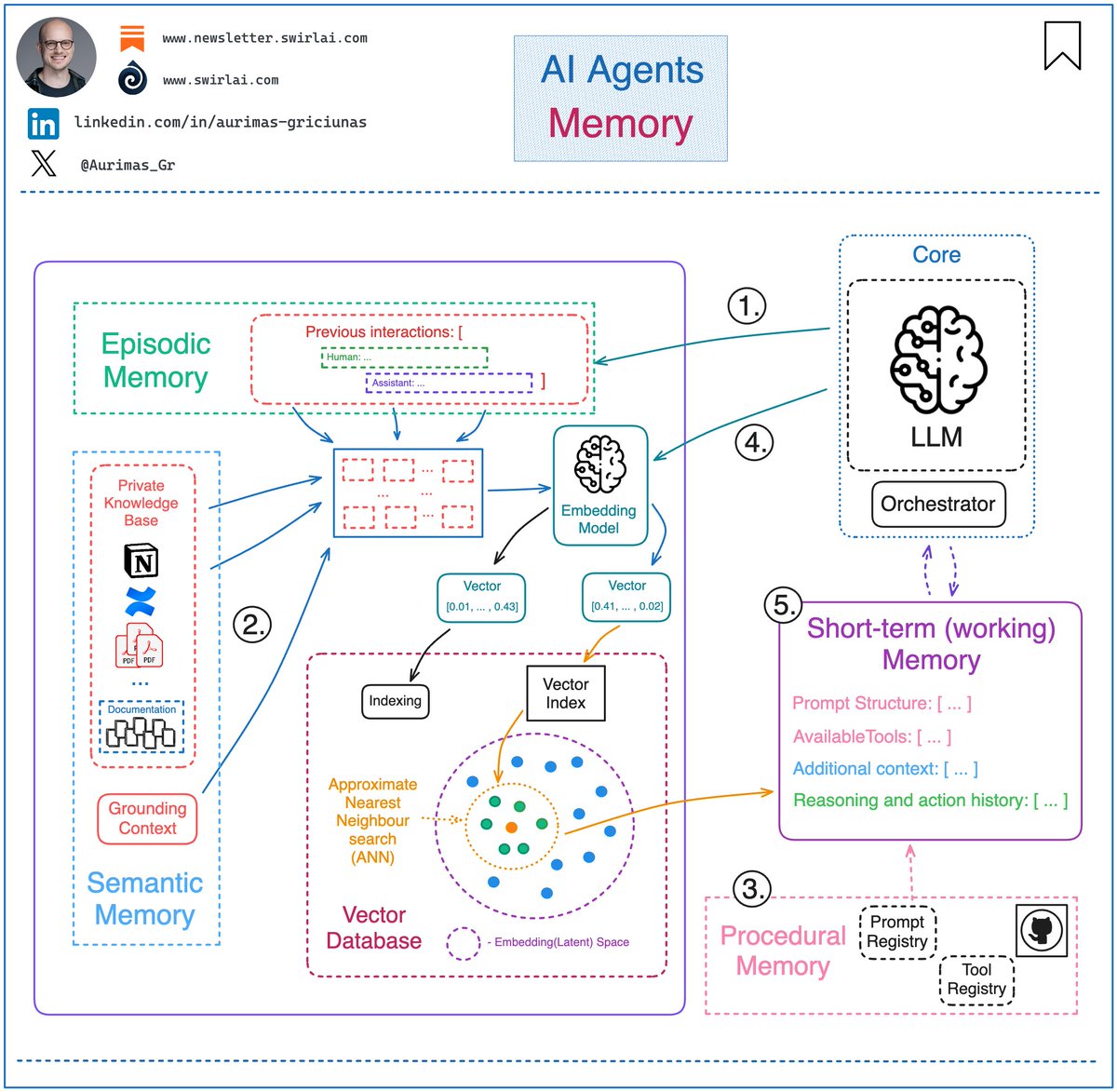
AI Agents 101: 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆. In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available. It is useful to group the memory into four types: 𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions. 𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers. 𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries. 𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand. 𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system. We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory. A visual explanation of potential implementation details 👇 And that is it! The rest is all about how you architect the topology of your Agentic Systems. What do you think about memory in AI Agents? #LLM #AI #MachineLearning
A simple way to explain 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆. In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available. It is useful to group the memory into four types: 𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions. 𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers. 𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries. 𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand. 𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system. We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory. A visual explanation of potential implementation details 👇 And that is it! The rest is all about how you architect the flow of your Agentic systems. What do you think about memory in AI Agents? #LLM #AI #MachineLearning Want to learn how to build an Agent from scratch without any LLM orchestration framework? Follow my journey here: newsletter.swirlai.com/p/building-ai-…
Here are the 𝟱 𝗯𝗼𝗼𝗸𝘀 𝘆𝗼𝘂 𝗺𝘂𝘀𝘁 𝗶𝗻𝗰𝗹𝘂𝗱𝗲 𝗶𝗻 𝘆𝗼𝘂𝗿 𝗿𝗲𝗮𝗱𝗶𝗻𝗴 𝗹𝗶𝘀𝘁 𝘁𝗼 𝗴𝗲𝘁 𝘂𝗽 𝘁𝗼 𝘀𝗽𝗲𝗲𝗱 𝘄𝗶𝘁𝗵 𝘁𝗵𝗲 𝗲𝗻𝗱-𝘁𝗼-𝗲𝗻𝗱 𝗗𝗮𝘁𝗮 𝗟𝗶𝗳𝗲𝗰𝘆𝗰𝗹𝗲. I am a strong believer that you should strive to understand the entire end-to-end Data System if you want to achieve the best results in your career progression. This means having high level knowledge of both Data Engineering and Machine Learning Systems supplemented by a dose of Systems Thinking. So here is the list of books that will help you grow in these areas. 1️⃣ ”𝗙𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹𝘀 𝗼𝗳 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴” - A book that I wish I had 6 years ago. After reading it you will understand the entire Data Engineering workflow and it will prepare you for further deep dives. 2️⃣ ”𝗗𝗲𝘀𝗶𝗴𝗻𝗶𝗻𝗴 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺𝘀” - A gem of 2022 in Machine Learning System Design. It will introduce you to the entire Machine Learning Lifecycle and give you tools to reason about more complicated ML Systems. 3️⃣ “𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗗𝗲𝘀𝗶𝗴𝗻 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀” - The book introduces you to 30 Design Patterns for Machine Learning. You will find 30 recurring real life problems in ML Systems, how a given pattern tries to solve them and what are the alternatives. Always have this book by your side and refer to it once you run into described problems - the book is gold. 4️⃣ “𝗗𝗲𝘀𝗶𝗴𝗻𝗶𝗻𝗴 𝗗𝗮𝘁𝗮-𝗜𝗻𝘁𝗲𝗻𝘀𝗶𝘃𝗲 𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻𝘀” - Delve deeper into Data Engineering Fundamentals. After reading the book you will understand Storage Formats, Distributed Technologies, Distributed Consensus algorithms and more. 5️⃣ “𝗦𝘆𝘀𝘁𝗲𝗺 𝗗𝗲𝘀𝗶𝗴𝗻 𝗜𝗻𝘁𝗲𝗿𝘃𝗶𝗲𝘄: 𝗔𝗻 𝗜𝗻𝘀𝗶𝗱𝗲𝗿’𝘀 𝗚𝘂𝗶𝗱𝗲” (𝘃𝗼𝗹𝘂𝗺𝗲 𝟭 𝗮𝗻𝗱 𝟮) - While these books are not focusing on Data Systems specifically they are non-questionable “must reads” to grow your systems thinking. It covers multiple IT systems that you would find in the real world and explains how to reason about scaling them as the user count increases. [𝗡𝗢𝗧𝗘]: All of the books above are talking about Fundamental concepts, even if you read all of them and decide that Data Field is not for you - you will be able to reuse the knowledge in any other Tech Role. Would you swap any books if you had only 5 slots? Let me know in the comment section 👇 -------- Follow me to upskill in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space. Also hit 🔔to stay notified about new content. 𝗗𝗼𝗻’𝘁 𝗳𝗼𝗿𝗴𝗲𝘁 𝘁𝗼 𝗹𝗶𝗸𝗲 💙, 𝘀𝗵𝗮𝗿𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗺𝗲𝗻𝘁! Join a growing community of Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com

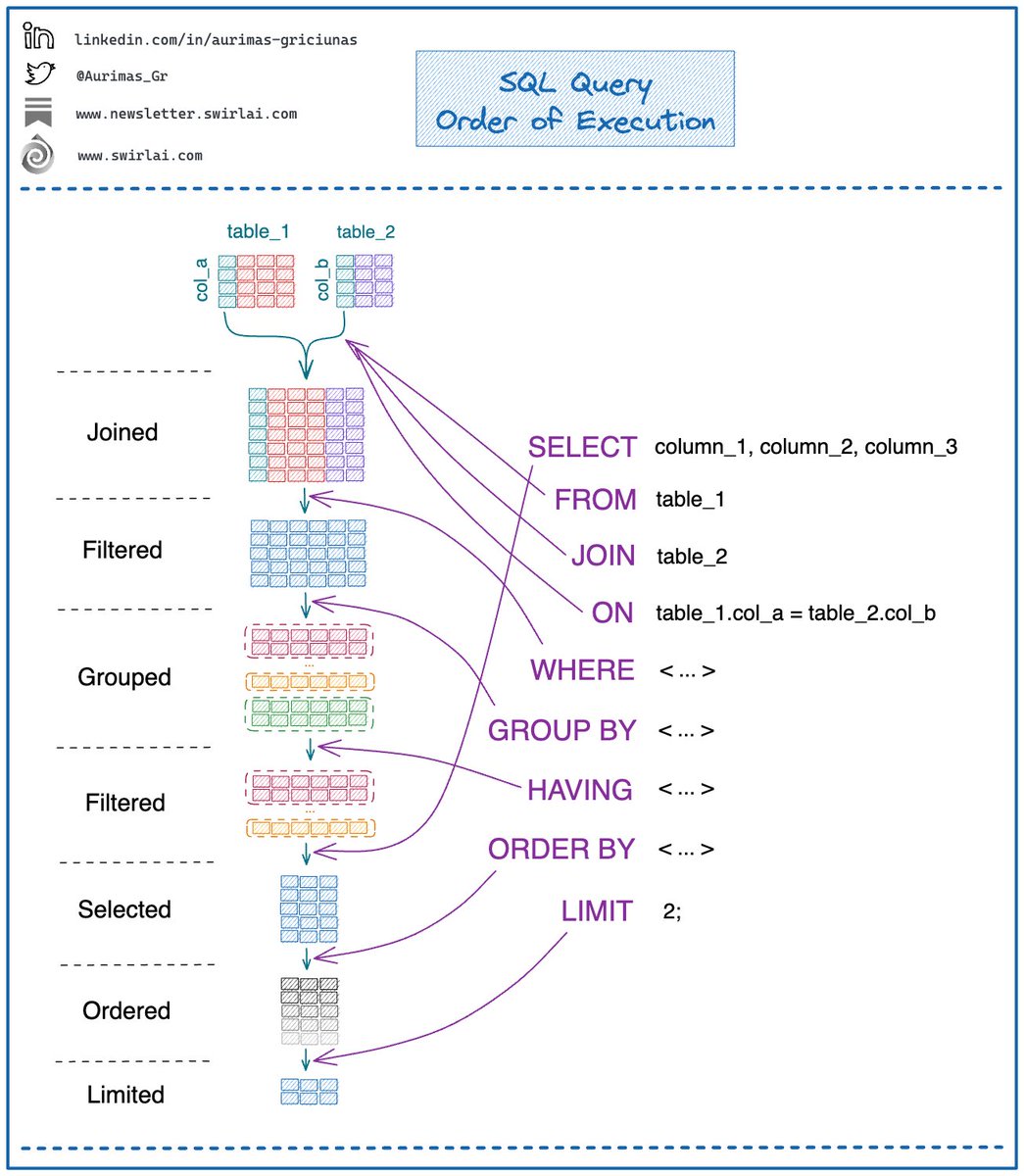
What is the 𝗦𝗤𝗟 𝗤𝘂𝗲𝗿𝘆 𝗼𝗿𝗱𝗲𝗿 𝗼𝗳 𝗘𝘅𝗲𝗰𝘂𝘁𝗶𝗼𝗻? There are many steps involved in optimising your SQL Queries. It is helpful to understand the order of SQL Query Execution as we might have constructed a different picture mentally. The actual order is as follows: 𝟭. 𝗙𝗥𝗢𝗠 𝗮𝗻𝗱 𝗝𝗢𝗜𝗡: determine the base data of interest. 𝟮. 𝗪𝗛𝗘𝗥𝗘: filter base data of interest to retain only the data that meets the where clause. 𝟯. 𝗚𝗥𝗢𝗨𝗣 𝗕𝗬: group the filtered data by a specific column or multiple columns. Groups are used to calculate aggregates for selected columns. 𝟰. 𝗛𝗔𝗩𝗜𝗡𝗚: filter data again by defining constraints on the columns that we grouped by. 𝟱. 𝗦𝗘𝗟𝗘𝗖𝗧: select a subset of columns from the filtered grouped result. This is also where 𝗪𝗜𝗡𝗗𝗢𝗪 𝗳𝘂𝗻𝗰𝘁𝗶𝗼𝗻 𝗮𝗴𝗴𝗿𝗲𝗴𝗮𝘁𝗶𝗼𝗻𝘀 happen. 𝟲. 𝗢𝗥𝗗𝗘𝗥 𝗕𝗬: order the result by one or multiple columns. 𝟳. 𝗟𝗜𝗠𝗜𝗧: only retain the top n rows from the ordered result. Below is a nice way to visualise it. What are your thoughts? Let me know in the comment section 👇 -------- Follow me to upskill in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space. Also hit 🔔to stay notified about new content. 𝗗𝗼𝗻’𝘁 𝗳𝗼𝗿𝗴𝗲𝘁 𝘁𝗼 𝗹𝗶𝗸𝗲 💙, 𝘀𝗵𝗮𝗿𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗺𝗲𝗻𝘁! Join a growing community of Data Professionals by subscribing to my 𝗡𝗲𝘄𝘀𝗹𝗲𝘁𝘁𝗲𝗿: newsletter.swirlai.com
TOON (Token-Oriented Object Notation) is out for some days now and it aims to make communication with LLMs more accurate and token-efficient. The TOON topic is now one of the hottest news on the LLM market and it might actually matter. 𝗪𝗵𝘆 𝗜 𝘁𝗵𝗶𝗻𝗸 𝘀𝗼: I was initially hesitant to cover this, potentially being another hype to quickly fade, but: ✅ The format has been shown to increase the accuracy of models while decreasing the token count. I was not sure if there were any accuracy retention studies made, it seems there were. ✅ Token efficiency is extremely important when working with Agentic Systems that require a lot of structured context inside of their reasoning chains. And we are moving towards a post-PoC world where there is a lot of emphasis placed on optimisation of the workflows. 𝗔 𝘀𝗵𝗼𝗿𝘁 𝘀𝘂𝗺𝗺𝗮𝗿𝘆: - Token-efficient: typically 30-60% fewer tokens on large uniform arrays vs formatted JSON. - LLM-friendly guardrails: explicit lengths and fields enable validation. - Minimal syntax: removes redundant punctuation (braces, brackets, most quotes). - Indentation-based structure: like YAML, uses whitespace instead of braces. - Tabular arrays: declare keys once, stream data as rows. An example: 𝘑𝘚𝘖𝘕 𝘧𝘰𝘳𝘮𝘢𝘵: "shopping_cart": [ { "id": "GDKVEG984", "name": "iPhone 15 Pro Max", "quantity": 2, "price": 1499.99, "category": "Electronics" }, { "id": "GDKVEG985", "name": "Samsung Galaxy S24 Ultra", "quantity": 1, "price": 1299.99, "category": "Electronics" }, { "id": "GDKVEG986", "name": "Apple Watch Series 9", "quantity": 1, "price": 199.99, "category": "Electronics" }, { "id": "GDKVEG987", "name": "MacBook Pro 16-inch", "quantity": 1, "price": 2499.99, "category": "Electronics" } ] } 𝘞𝘩𝘦𝘯 𝘦𝘯𝘤𝘰𝘥𝘦𝘥 𝘪𝘯𝘵𝘰 𝘛𝘖𝘖𝘕 𝘧𝘰𝘳𝘮𝘢𝘵: shopping_cart: items[4]{id,name,quantity,price,category}: GDKVEG984,iPhone 15 Pro Max,2,1499.99,Electronics GDKVEG985,Samsung Galaxy S24 Ultra,1,1299.99,Electronics GDKVEG986,Apple Watch Series 9,1,199.99,Electronics GDKVEG987,MacBook Pro 16-inch,1,2499.99,Electronics 𝗥𝗲𝘀𝘂𝗹𝘁: ✅ 43% savings in token amount. ✅ Directly translates to 43% savings in token cost for this LLM input. ❗️ Be sure to know when NOT to use the format (and always test it for your application specifically): - Deeply nested or non-uniform structures. - Semi-uniform arrays. - Pure tabular data. ℹ️ I will be testing it in the upcoming weeks. Let me know if you have already tested TOON and what are your takeaways! 👇 #LLM #AI #MachineLearning

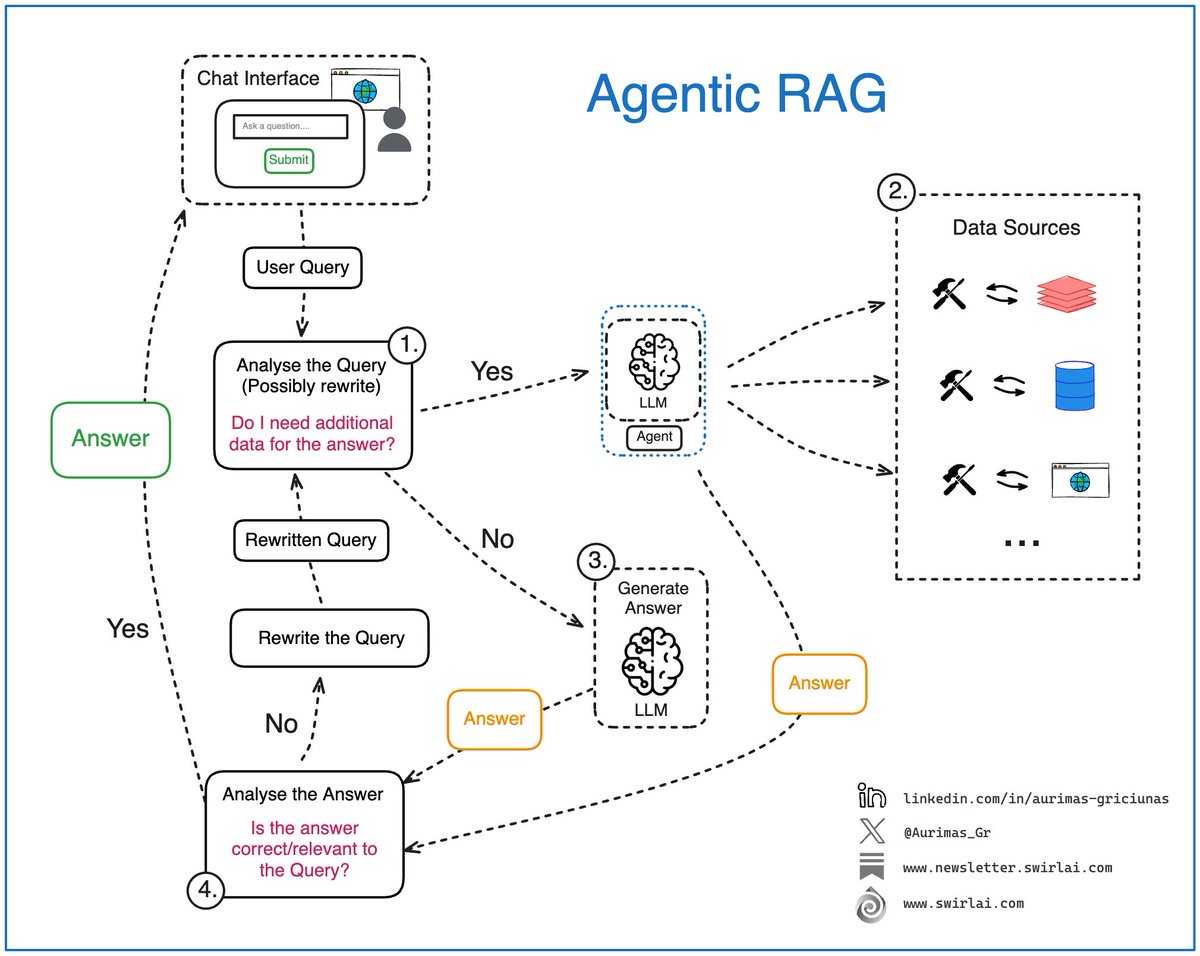
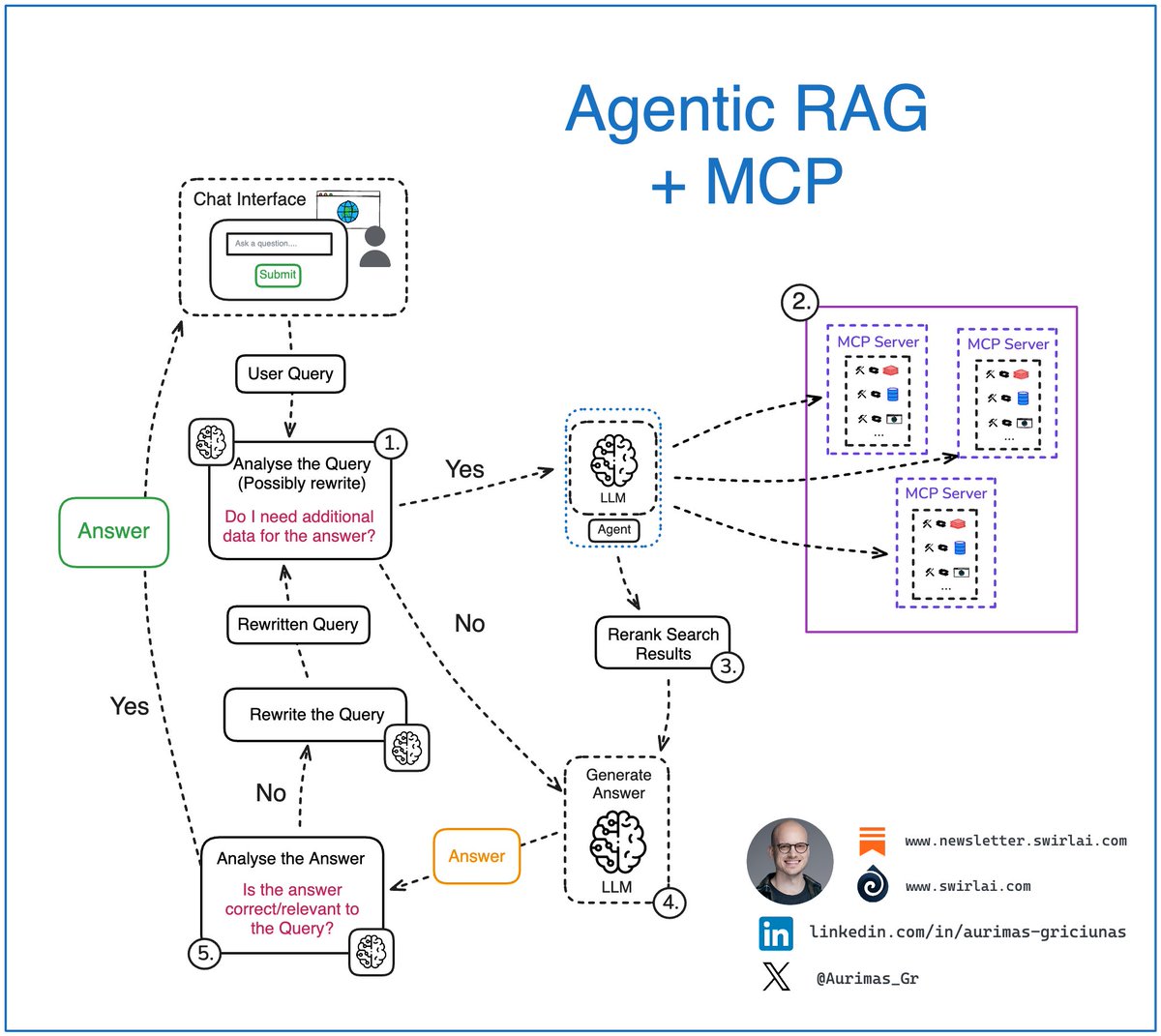
The power of 𝗠𝗖𝗣 in 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚 Systems. To make it clear, most of the RAG systems running in production today are to some extent Agentic. How the agentic topology is implemented depends on the use case. If you are packing many data sources, most likely there is some agency present at least at the data source selection for retrieval stage. This is how MCP enriches the evolution of your Agentic RAG systems in such case (𝘱𝘰𝘪𝘯𝘵 2.): 𝟭. Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where: ➡️ The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline. ➡️ The agent decides if additional data sources are required to answer the query. 𝟮. If additional data is required, the Retrieval step is triggered. We could tap into variety of data types, few examples: ➡️ Real time user data. ➡️ Internal documents that a user might be interested in. ➡️ Data available on the web. ➡️ … 𝗧𝗵𝗶𝘀 𝗶𝘀 𝘄𝗵𝗲𝗿𝗲 𝗠𝗖𝗣 𝗰𝗼𝗺𝗲𝘀 𝗶𝗻: ✅ Each data domain can manage their own MCP Servers. Exposing specific rules of how the data should be used. ✅ Security and compliance can be ensured on the Servel level for each domain. ✅ New data domains can be easily added to the MCP server pool in a standardised way with no Agent rewrite needed enabling decoupled evolution of the system in terms of 𝗣𝗿𝗼𝗰𝗲𝗱𝘂𝗿𝗮𝗹, 𝗘𝗽𝗶𝘀𝗼𝗱𝗶𝗰 𝗮𝗻𝗱 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗠𝗲𝗺𝗼𝗿𝘆. ✅ Platform builders can expose their data in a standardised way to external consumers. Enabling easy access to data on the web. ✅ AI Engineers can continue to focus on the topology of the Agent. 𝟯. If there is no need for additional data, we try to compose the answer (or multiple answers or a set of actions) straight via an LLM. 𝟰. The answer gets analyzed, summarized and evaluated for correctness and relevance: ➡️ If the Agent decides that the answer is good enough, it gets returned to the user. ➡️ If the Agent decides that the answer needs improvement, we try to rewrite the user query and repeat the generation loop. Are you using MCP in your Agentic RAG systems? Let me know about your experience in the comment section 👇 #LLM #AI #MachineLearning
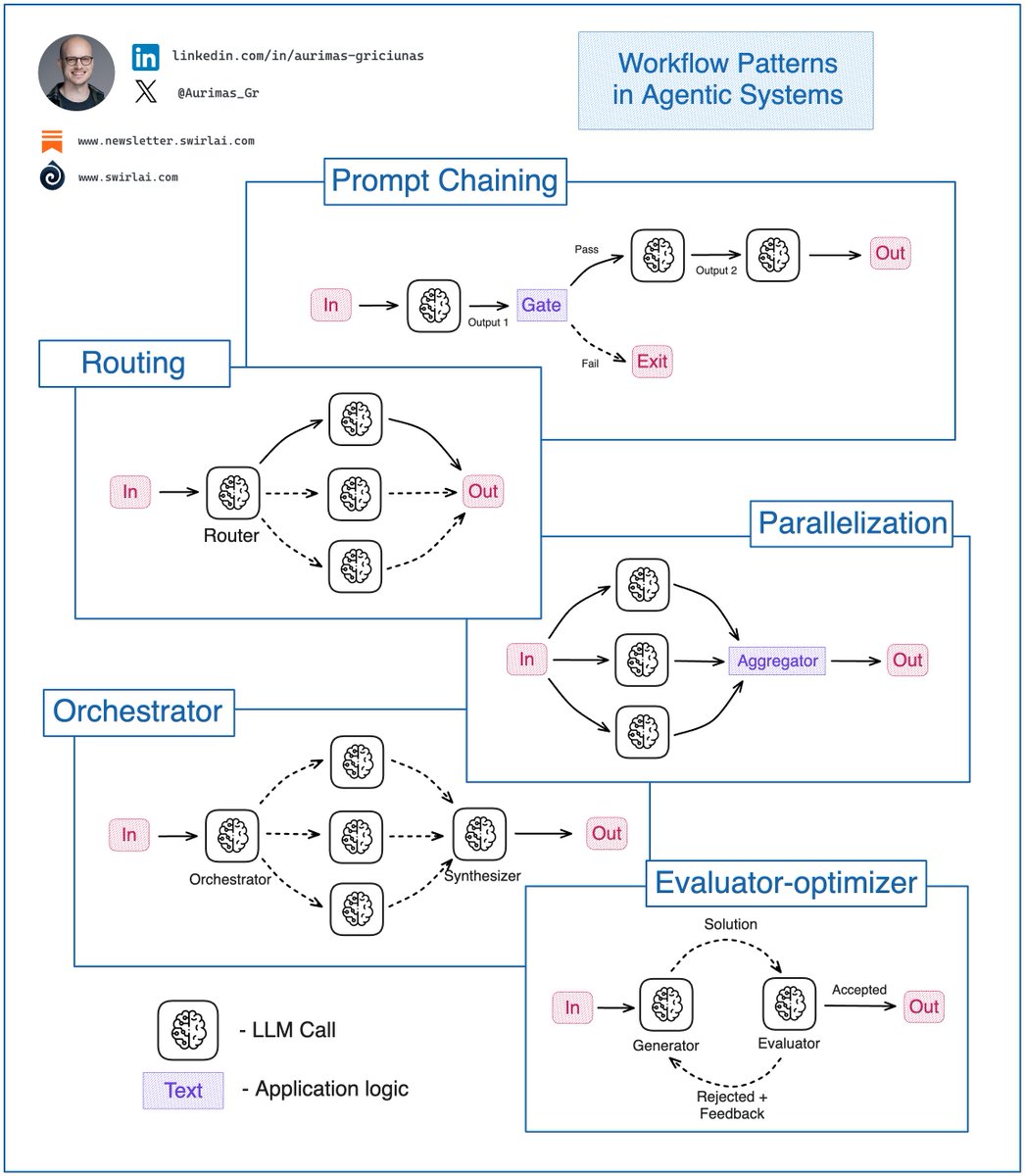
You must know these 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗦𝘆𝘀𝘁𝗲𝗺 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀 as an 𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿. If you are building Agentic Systems in an Enterprise setting you will soon discover that the simplest workflow patterns work the best and bring the most business value. At the end of last year Anthropic did a great job summarising the top patterns for these workflows and they still hold strong. Let’s explore what they are and where each can be useful: 𝟭. 𝗣𝗿𝗼𝗺𝗽𝘁 𝗖𝗵𝗮𝗶𝗻𝗶𝗻𝗴: This pattern decomposes a complex task and tries to solve it in manageable pieces by chaining them together. Output of one LLM call becomes an output to another. ✅ In most cases such decomposition results in higher accuracy with sacrifice for latency. ℹ️ In heavy production use cases Prompt Chaining would be combined with following patterns, a pattern replace an LLM Call node in Prompt Chaining pattern. 𝟮. 𝗥𝗼𝘂𝘁𝗶𝗻𝗴: In this pattern, the input is classified into multiple potential paths and the appropriate is taken. ✅ Useful when the workflow is complex and specific topology paths could be more efficiently solved by a specialized workflow. ℹ️ Example: Agentic Chatbot - should I answer the question with RAG or should I perform some actions that a user has prompted for? 𝟯. 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Initial input is split into multiple queries to be passed to the LLM, then the answers are aggregated to produce the final answer. ✅ Useful when speed is important and multiple inputs can be processed in parallel without needing to wait for other outputs. Also, when additional accuracy is required. ℹ️ Example 1: Query rewrite in Agentic RAG to produce multiple different queries for majority voting. Improves accuracy. ℹ️ Example 2: Multiple items are extracted from an invoice, all of them can be processed further in parallel for better speed. 𝟰. 𝗢𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗼𝗿: An orchestrator LLM dynamically breaks down tasks and delegates to other LLMs or sub-workflows. ✅ Useful when the system is complex and there is no clear hardcoded topology path to achieve the final result. ℹ️ Example: Choice of datasets to be used in Agentic RAG. 𝟱. 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗼𝗿-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿: Generator LLM produces a result then Evaluator LLM evaluates it and provides feedback for further improvement if necessary. ✅ Useful for tasks that require continuous refinement. ℹ️ Example: Deep Research Agent workflow when refinement of a report paragraph via continuous web search is required. 𝗧𝗶𝗽𝘀: ❗️ Before going for full fledged Agents you should always try to solve a problem with simpler Workflows described in the article. What are the most complex workflows you have deployed to production? Let me know in the comments 👇 #LLM #AI #MachineLearning
This is how 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆 works. In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available. It is useful to group the memory into four types: 𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions. 𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers. 𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries. 𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand. 𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system. We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory. A visual explanation of potential implementation details 👇 And that is it! The rest is all about how you architect the topology of your Agentic Systems. What do you think about memory in AI Agents? #GenAI #AI #MachineLearning
You must know these 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗦𝘆𝘀𝘁𝗲𝗺 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀 as an 𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿. If you are building Agentic Systems in an Enterprise setting you will soon discover that the simplest workflow patterns work the best and bring the most business value. At the end of last year Anthropic did a great job summarising the top patterns for these workflows and they still hold strong. Let’s explore what they are and where each can be useful: 𝟭. 𝗣𝗿𝗼𝗺𝗽𝘁 𝗖𝗵𝗮𝗶𝗻𝗶𝗻𝗴: This pattern decomposes a complex task and tries to solve it in manageable pieces by chaining them together. Output of one LLM call becomes an output to another. ✅ In most cases such decomposition results in higher accuracy with sacrifice for latency. ℹ️ In heavy production use cases Prompt Chaining would be combined with following patterns, a pattern replace an LLM Call node in Prompt Chaining pattern. 𝟮. 𝗥𝗼𝘂𝘁𝗶𝗻𝗴: In this pattern, the input is classified into multiple potential paths and the appropriate is taken. ✅ Useful when the workflow is complex and specific topology paths could be more efficiently solved by a specialized workflow. ℹ️ Example: Agentic Chatbot - should I answer the question with RAG or should I perform some actions that a user has prompted for? 𝟯. 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Initial input is split into multiple queries to be passed to the LLM, then the answers are aggregated to produce the final answer. ✅ Useful when speed is important and multiple inputs can be processed in parallel without needing to wait for other outputs. Also, when additional accuracy is required. ℹ️ Example 1: Query rewrite in Agentic RAG to produce multiple different queries for majority voting. Improves accuracy. ℹ️ Example 2: Multiple items are extracted from an invoice, all of them can be processed further in parallel for better speed. 𝟰. 𝗢𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗼𝗿: An orchestrator LLM dynamically breaks down tasks and delegates to other LLMs or sub-workflows. ✅ Useful when the system is complex and there is no clear hardcoded topology path to achieve the final result. ℹ️ Example: Choice of datasets to be used in Agentic RAG. 𝟱. 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗼𝗿-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿: Generator LLM produces a result then Evaluator LLM evaluates it and provides feedback for further improvement if necessary. ✅ Useful for tasks that require continuous refinement. ℹ️ Example: Deep Research Agent workflow when refinement of a report paragraph via continuous web search is required. 𝗧𝗶𝗽𝘀: ❗️ Before going for full fledged Agents you should always try to solve a problem with simpler Workflows described in the article. What are the most complex workflows you have deployed to production? Let me know in the comments 👇 #LLM #AI #MachineLearning
𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗥𝗼𝗮𝗱𝗺𝗮𝗽. 👇 It is created with beginners in mind but can be easily adapted if you are proficient in some of the areas already. 𝘖𝘯 𝘢 𝘩𝘪𝘨𝘩 𝘭𝘦𝘷𝘦𝘭: 𝗙𝗼𝗰𝘂𝘀 𝗼𝗻 𝗙𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹𝘀 throughout the journey, but don't focus on mastering them early - start building first. - Software Engineering Fundamentals: REST APIs, Testing, Async Programming. - ML Fundamentals: Statistics (extremely useful for evals as well), Types of ML Models. - Observability and Evaluation: Instrumentation, Observability Platforms, Evaluation Techniques, AI Agent Evaluation. ✅ Different Agentic Systems require different fundamental knowledge to implement. Learn in order. 𝗟𝗟𝗠 𝗔𝗣𝗜𝘀: - Types of LLMs. - Structured Outputs. - Prompt Caching. - Multi-modal models. 𝗠𝗼𝗱𝗲𝗹 𝗔𝗱𝗮𝗽𝘁𝗮𝘁𝗶𝗼𝗻: - Prompt Engineering. - Tool Use. - Finetuning. 𝗦𝘁𝗼𝗿𝗮𝗴𝗲 𝗳𝗼𝗿 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹: - Vector Databases. - Graph Databases. - Hybrid retrieval. 𝗥𝗔𝗚 𝗮𝗻𝗱 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚: - Data preparation. - Data retrieval and generation. - Reranking. - MCP. - LLM Orchestration Frameworks. 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀: - AI Agent Design Patterns. - Multi-Agent systems. - Memory. - Human in or on the loop. - A2A, ACP etc. - Agent Orchestration Frameworks. 𝗜𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲: - Kubernetes. - Cloud Services. - CI/CD. - Model Routing. - LLM deployment. 𝗦𝗲𝗰𝘂𝗿𝗶𝘁𝘆: - Guardrails. - Testing LLM based applications. - Ethical considerations. 𝗙𝗼𝗿𝘄𝗮𝗿𝗱 𝗹𝗼𝗼𝗸𝗶𝗻𝗴 𝗲𝗹𝗲𝗺𝗲𝗻𝘁𝘀: - Voice and Vision Agents. - Robotics Agents. - Computer use. - CLI Agents. - Automated Prompt Engineering. I teach all of this, hands-on in my bootcamp (10% off with code LastChance): maven.com/swirl-ai/end-t… Next cohort kicking off next week! Did I miss anything? Let me know in the comments! #LLM #AI #MachineLearning

𝗠𝗖𝗣 and 𝗔𝟮𝗔: Friends or Foes? In my latest Newsletter episode I talk about both protocols. Could A2A eat up MCP in the long term? I have been asked multiple times why I think the two protocols could become competitive in the future. I tried to outline my thoughts in this Newsletter episode. After reading through you will get answers to the following questions: ➡️ What is A2A? ➡️ What is MCP? ➡️ How is A2A complimentary to MCP and vice versa? ➡️ Could A2A eat up MCP long term? You can find the episode here: lnkd.in/drzD92Qw Happy reading! Let me know your thoughts in the comments. 👇 hashtag#LLM hashtag#AI hashtag#MachineLearning I have been asked multiple times why I think the two protocols could become competitive in the future. I tried to outline my thoughts in this Newsletter episode. After reading through you will get answers to the following questions: ➡️ What is A2A? ➡️ What is MCP? ➡️ How is A2A complimentary to MCP and vice versa? ➡️ Could A2A eat up MCP long term? You can find the episode here: newsletter.swirlai.com/p/mcp-vs-a2a-f… Happy reading! Let me know your thoughts in the comments. 👇 #LLM #AI #MachineLearning
Here is why you need to understand 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚 as an AI Engineer. Simple naive RAG systems are rarely used in real world applications. To provide correct actions to solve the user intent, we are always adding some agency to the RAG system - it is usually just a bit of it. It is important to 𝗻𝗼𝘁 𝗴𝗲𝘁 𝗹𝗼𝘀𝘁 𝗶𝗻 𝘁𝗵𝗲 𝗯𝘂𝘇𝘇 𝗮𝗻𝗱 𝘁𝗲𝗿𝗺𝗶𝗻𝗼𝗹𝗼𝗴𝘆 and understand that there is 𝗻𝗼 𝘀𝗶𝗻𝗴𝗹𝗲 𝗯𝗹𝘂𝗲𝗽𝗿𝗶𝗻𝘁 to add this agency to your RAG system and you should adapt to your use case. My advice is to think in systems and engineering flows. Let’s explore some of the moving pieces in Agentic RAG: 𝟭. Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where: ➡️ The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline. ➡️ The agent decides if additional data sources are required to answer the query. 𝟮. If additional data is required, the Retrieval step is triggered. In Agentic RAG case, we could have a single or multiple agents responsible for figuring out what data sources should be tapped into, few examples: ➡️ Real time user data. This is a pretty cool concept as we might have some real time information like current location available for the user. ➡️ Internal documents that a user might be interested in. ➡️ Data available on the web. ➡️ … 𝟯. If there is no need for additional data, we try to compose the answer (or multiple answers or a set of actions) straight via an LLM. 𝟰. The answer gets analyzed, summarized and evaluated for correctness and relevance: ➡️ If the Agent decides that the answer is good enough, it gets returned to the user. ➡️ If the Agent decides that the answer needs improvement, we try to rewrite the user query and repeat the generation loop. ✅ Remember the Reflection pattern from my last Newsletter article? This is exactly that. 👆 The real power of Agentic RAG lies in its ability to perform additional routing pre and post generation, handle multiple distinct data sources for retrieval if it is needed and recover from failures while generating correct answers. What are your thoughts on Agentic RAG? Let me know in the comments! 👇 #RAG #LLM #AI
𝗔𝗜 𝗔𝗴𝗲𝗻𝘁’𝘀 𝗠𝗲𝗺𝗼𝗿𝘆 is the most important piece of 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴, this is how we define it 👇 In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available. It is useful to group the memory into four types: 𝟭. 𝗘𝗽𝗶𝘀𝗼𝗱𝗶𝗰 - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions. 𝟮. 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers. 𝟯. 𝗣𝗿𝗼𝗰𝗲𝗱𝘂𝗿𝗮𝗹 - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries. 𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand. 𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system. We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory. And that is it! The rest is all about how you architect the topology of your Agentic Systems. Any war stories you have while managing Agent’s memory? Let me know in the comments 👇 #LLM #AI #ContextEngineering
What is 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚? In real world applications, simple naive RAG systems are rarely used nowadays. To provide correct answers to a user query, we are always adding some agency to the RAG system. However, it is important to 𝗻𝗼𝘁 𝗴𝗲𝘁 𝗹𝗼𝘀𝘁 𝗶𝗻 𝘁𝗵𝗲 𝗯𝘂𝘇𝘇 𝗮𝗻𝗱 𝘁𝗲𝗿𝗺𝗶𝗻𝗼𝗹𝗼𝗴𝘆 and understand that there is 𝗻𝗼 𝘀𝗶𝗻𝗴𝗹𝗲 𝗯𝗹𝘂𝗲𝗽𝗿𝗶𝗻𝘁 to add the mentioned agency to your RAG system and you should adapt to your use case. My advice is to not get stuck on terminology and think about engineering flows. Let’s explore some of the moving pieces in Agentic RAG: 𝟭. Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where: ➡️ The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline. ➡️ The agent decides if additional data sources are required to answer the query. 𝟮. If additional data is required, the Retrieval step is triggered. In Agentic RAG case, we could have a single or multiple agents responsible for figuring out what data sources should be tapped into, few examples: ➡️ Real time user data. This is a pretty cool concept as we might have some real time information like current location available for the user. ➡️ Internal documents that a user might be interested in. ➡️ Data available on the web. ➡️ … 𝟯. If there is no need for additional data, we try to compose the answer (or multiple answers) straight via an LLM. 𝟰. The answer (or answers) get analyzed, summarized and evaluated for correctness and relevance: ➡️ If the Agent decides that the answer is good enough, it gets returned to the user. ➡️ If the Agent decides that the answer needs improvement, we try to rewrite the usr query and repeat the generation loop. The real power of Agentic RAG lies in its ability to perform additional routing pre and post generation, handle multiple distinct data sources for retrieval if it is needed and recover from failures in generating correct answers. What are your thoughts on Agentic RAG? Let me know in the comments! 👇 #RAG #LLM #AI
Last week I released the first article in my hands-on 𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀 𝗙𝗿𝗼𝗺 𝗦𝗰𝗿𝗮𝘁𝗰𝗵 series. It covers the tool use element of an Agent. I wanted to do this for quite some time now and finally the time has arrived! If you are using any orchestration frameworks for agentic applications, you might be abstracted away from what using a tool really means. I believe that understanding applications from the base building blocks is really important so we are implementing all of the abstractions from scratch. After finishing the project you will learn: ➡️ What AI Agents are. ➡️ How the Tool usage in AI Agents actually works. ➡️ How to build a decorator wrapper that extracts relevant details from a Python function to be passed to the LLM via system prompt. ➡️ How to think about constructing effective system prompts that can be used for Agents. ➡️ How to build an Agent class that is able to plan and execute actions using provided Tools. You can find the article here: newsletter.swirlai.com/p/building-ai-… You can also find a Jupyter notebook and python scripts that complement the article in a GitHub repo (links in the article). Youtube videos coming soon! If you’re looking for something to dig your hands into between holidays be sure to take a look! Second part of the series is coming in a few weeks. Let me know if there are any issues following the project. Feel free to DM me or leave comments here or under the article 👇 #AI #LLM #MachineLearning
Most engaged tweets of Aurimas Griciūnas
TOON (Token-Oriented Object Notation) is out for some days now and it aims to make communication with LLMs more accurate and token-efficient. The TOON topic is now one of the hottest news on the LLM market and it might actually matter. 𝗪𝗵𝘆 𝗜 𝘁𝗵𝗶𝗻𝗸 𝘀𝗼: I was initially hesitant to cover this, potentially being another hype to quickly fade, but: ✅ The format has been shown to increase the accuracy of models while decreasing the token count. I was not sure if there were any accuracy retention studies made, it seems there were. ✅ Token efficiency is extremely important when working with Agentic Systems that require a lot of structured context inside of their reasoning chains. And we are moving towards a post-PoC world where there is a lot of emphasis placed on optimisation of the workflows. 𝗔 𝘀𝗵𝗼𝗿𝘁 𝘀𝘂𝗺𝗺𝗮𝗿𝘆: - Token-efficient: typically 30-60% fewer tokens on large uniform arrays vs formatted JSON. - LLM-friendly guardrails: explicit lengths and fields enable validation. - Minimal syntax: removes redundant punctuation (braces, brackets, most quotes). - Indentation-based structure: like YAML, uses whitespace instead of braces. - Tabular arrays: declare keys once, stream data as rows. An example: 𝘑𝘚𝘖𝘕 𝘧𝘰𝘳𝘮𝘢𝘵: "shopping_cart": [ { "id": "GDKVEG984", "name": "iPhone 15 Pro Max", "quantity": 2, "price": 1499.99, "category": "Electronics" }, { "id": "GDKVEG985", "name": "Samsung Galaxy S24 Ultra", "quantity": 1, "price": 1299.99, "category": "Electronics" }, { "id": "GDKVEG986", "name": "Apple Watch Series 9", "quantity": 1, "price": 199.99, "category": "Electronics" }, { "id": "GDKVEG987", "name": "MacBook Pro 16-inch", "quantity": 1, "price": 2499.99, "category": "Electronics" } ] } 𝘞𝘩𝘦𝘯 𝘦𝘯𝘤𝘰𝘥𝘦𝘥 𝘪𝘯𝘵𝘰 𝘛𝘖𝘖𝘕 𝘧𝘰𝘳𝘮𝘢𝘵: shopping_cart: items[4]{id,name,quantity,price,category}: GDKVEG984,iPhone 15 Pro Max,2,1499.99,Electronics GDKVEG985,Samsung Galaxy S24 Ultra,1,1299.99,Electronics GDKVEG986,Apple Watch Series 9,1,199.99,Electronics GDKVEG987,MacBook Pro 16-inch,1,2499.99,Electronics 𝗥𝗲𝘀𝘂𝗹𝘁: ✅ 43% savings in token amount. ✅ Directly translates to 43% savings in token cost for this LLM input. ❗️ Be sure to know when NOT to use the format (and always test it for your application specifically): - Deeply nested or non-uniform structures. - Semi-uniform arrays. - Pure tabular data. ℹ️ I will be testing it in the upcoming weeks. Let me know if you have already tested TOON and what are your takeaways! 👇 #LLM #AI #MachineLearning
AI Agents 101: 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆. In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available. It is useful to group the memory into four types: 𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions. 𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers. 𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries. 𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand. 𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system. We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory. A visual explanation of potential implementation details 👇 And that is it! The rest is all about how you architect the topology of your Agentic Systems. What do you think about memory in AI Agents? #LLM #AI #MachineLearning
A simple way to explain 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆. In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available. It is useful to group the memory into four types: 𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions. 𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers. 𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries. 𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand. 𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system. We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory. A visual explanation of potential implementation details 👇 And that is it! The rest is all about how you architect the flow of your Agentic systems. What do you think about memory in AI Agents? #LLM #AI #MachineLearning Want to learn how to build an Agent from scratch without any LLM orchestration framework? Follow my journey here: newsletter.swirlai.com/p/building-ai-…
𝗔𝗜 𝗔𝗴𝗲𝗻𝘁’𝘀 𝗠𝗲𝗺𝗼𝗿𝘆 is the most important piece of 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴, this is how we define it 👇 In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available. It is useful to group the memory into four types: 𝟭. 𝗘𝗽𝗶𝘀𝗼𝗱𝗶𝗰 - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions. 𝟮. 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers. 𝟯. 𝗣𝗿𝗼𝗰𝗲𝗱𝘂𝗿𝗮𝗹 - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries. 𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand. 𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system. We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory. And that is it! The rest is all about how you architect the topology of your Agentic Systems. Any war stories you have while managing Agent’s memory? Let me know in the comments 👇 #AI #LLM #MachineLearning

𝗠𝗖𝗣 𝘃𝘀. 𝗔𝟮𝗔 Two days ago Google announced an open A2A (Agent2Agent) protocol in an attempt to normalise how we implement multi-Agent system communication. As always, social media is going crazy about it, but why? Let’s review the differences and how both protocols complement each other (read till the end). 𝘔𝘰𝘷𝘪𝘯𝘨 𝘱𝘪𝘦𝘤𝘦𝘴 𝘪𝘯 𝘔𝘊𝘗: 𝟭. MCP Host - Programs using LLMs at the core that want to access data through MCP. ❗️ When combined with A2A, an Agent becomes MCP Host. 𝟮. MCP Client - Clients that maintain 1:1 connections with servers. 𝟯. MCP Server - Lightweight programs that each expose specific capabilities through the standardized Model Context Protocol. 𝟰. Local Data Sources - Your computer’s files, databases, and services that MCP servers can securely access. 𝟱. Remote Data Sources - External systems available over the internet (e.g., through APIs) that MCP servers can connect to. 𝘌𝘯𝘵𝘦𝘳 𝘈2𝘈: Where MCP falls short, A2A tries to help. In multi-Agent applications where state is not necessarily shared 𝟲. Agents (MCP Hosts) would implement and communicate via A2A protocol, that enables: ➡️ Secure Collaboration - MCP lacks authentication. ➡️ Task and State Management. ➡️ User Experience Negotiation. ➡️ Capability discovery - similar to MCP tools. 𝗛𝗼𝗻𝗲𝘀𝘁 𝘁𝗵𝗼𝘂𝗴𝗵𝘁𝘀: ❗️ I believe creators of MCP were planning to implement similar capabilities to A2A and expose agents via tools in long term. ❗️ We might just see a fight around who will win and become the standard protocol long term as both protocols might be expanding. Let me know your thoughts in the comments. 👇 #LLM #AI #MachineLearning
𝗠𝗖𝗣 and 𝗔𝟮𝗔: Friends or Foes? In my latest Newsletter episode I talk about both protocols. Could A2A eat up MCP in the long term? I have been asked multiple times why I think the two protocols could become competitive in the future. I tried to outline my thoughts in this Newsletter episode. After reading through you will get answers to the following questions: ➡️ What is A2A? ➡️ What is MCP? ➡️ How is A2A complimentary to MCP and vice versa? ➡️ Could A2A eat up MCP long term? You can find the episode here: lnkd.in/drzD92Qw Happy reading! Let me know your thoughts in the comments. 👇 hashtag#LLM hashtag#AI hashtag#MachineLearning I have been asked multiple times why I think the two protocols could become competitive in the future. I tried to outline my thoughts in this Newsletter episode. After reading through you will get answers to the following questions: ➡️ What is A2A? ➡️ What is MCP? ➡️ How is A2A complimentary to MCP and vice versa? ➡️ Could A2A eat up MCP long term? You can find the episode here: newsletter.swirlai.com/p/mcp-vs-a2a-f… Happy reading! Let me know your thoughts in the comments. 👇 #LLM #AI #MachineLearning
Here is why you need to understand 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚 as an AI Engineer. Simple naive RAG systems are rarely used in real world applications. To provide correct actions to solve the user intent, we are always adding some agency to the RAG system - it is usually just a bit of it. It is important to 𝗻𝗼𝘁 𝗴𝗲𝘁 𝗹𝗼𝘀𝘁 𝗶𝗻 𝘁𝗵𝗲 𝗯𝘂𝘇𝘇 𝗮𝗻𝗱 𝘁𝗲𝗿𝗺𝗶𝗻𝗼𝗹𝗼𝗴𝘆 and understand that there is 𝗻𝗼 𝘀𝗶𝗻𝗴𝗹𝗲 𝗯𝗹𝘂𝗲𝗽𝗿𝗶𝗻𝘁 to add this agency to your RAG system and you should adapt to your use case. My advice is to think in systems and engineering flows. Let’s explore some of the moving pieces in Agentic RAG: 𝟭. Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where: ➡️ The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline. ➡️ The agent decides if additional data sources are required to answer the query. 𝟮. If additional data is required, the Retrieval step is triggered. In Agentic RAG case, we could have a single or multiple agents responsible for figuring out what data sources should be tapped into, few examples: ➡️ Real time user data. This is a pretty cool concept as we might have some real time information like current location available for the user. ➡️ Internal documents that a user might be interested in. ➡️ Data available on the web. ➡️ … 𝟯. If there is no need for additional data, we try to compose the answer (or multiple answers or a set of actions) straight via an LLM. 𝟰. The answer gets analyzed, summarized and evaluated for correctness and relevance: ➡️ If the Agent decides that the answer is good enough, it gets returned to the user. ➡️ If the Agent decides that the answer needs improvement, we try to rewrite the user query and repeat the generation loop. ✅ Remember the Reflection pattern from my last Newsletter article? This is exactly that. 👆 The real power of Agentic RAG lies in its ability to perform additional routing pre and post generation, handle multiple distinct data sources for retrieval if it is needed and recover from failures while generating correct answers. What are your thoughts on Agentic RAG? Let me know in the comments! 👇 #RAG #LLM #AI
This is how 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆 works. In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available. It is useful to group the memory into four types: 𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions. 𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers. 𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries. 𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand. 𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system. We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory. A visual explanation of potential implementation details 👇 And that is it! The rest is all about how you architect the topology of your Agentic Systems. What do you think about memory in AI Agents? #GenAI #AI #MachineLearning
Integrating 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚 Systems via 𝗠𝗖𝗣 👇 If you are building RAG systems and packing many data sources for retrieval, most likely there is some agency present at least at the data source selection for retrieval stage. This is how MCP enriches the evolution of your Agentic RAG systems in such case (𝘱𝘰𝘪𝘯𝘵 2.): 𝟭. Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where: ➡️ The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline. ➡️ The agent decides if additional data sources are required to answer the query. 𝟮. If additional data is required, the Retrieval step is triggered. We could tap into variety of data types, few examples: ➡️ Real time user data. ➡️ Internal documents that a user might be interested in. ➡️ Data available on the web. ➡️ … 𝗧𝗵𝗶𝘀 𝗶𝘀 𝘄𝗵𝗲𝗿𝗲 𝗠𝗖𝗣 𝗰𝗼𝗺𝗲𝘀 𝗶𝗻: ✅ Each data domain can manage their own MCP Servers. Exposing specific rules of how the data should be used. ✅ Security and compliance can be ensured on the Servel level for each domain. ✅ New data domains can be easily added to the MCP server pool in a standardised way with no Agent rewrite needed enabling decoupled evolution of the system in terms of 𝗣𝗿𝗼𝗰𝗲𝗱𝘂𝗿𝗮𝗹, 𝗘𝗽𝗶𝘀𝗼𝗱𝗶𝗰 𝗮𝗻𝗱 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗠𝗲𝗺𝗼𝗿𝘆. ✅ Platform builders can expose their data in a standardised way to external consumers. Enabling easy access to data on the web. ✅ AI Engineers can continue to focus on the topology of the Agent. 𝟯. Retrieved data is consolidated and Reranked by a more powerful model compared to regular embedder. Data points are significantly narrowed down. 𝟰. If there is no need for additional data, we try to compose the answer (or multiple answers or a set of actions) straight via an LLM. 𝟱. The answer gets analyzed, summarized and evaluated for correctness and relevance: ➡️ If the Agent decides that the answer is good enough, it gets returned to the user. ➡️ If the Agent decides that the answer needs improvement, we try to rewrite the user query and repeat the generation loop. Are you using MCP in your Agentic RAG systems? Let me know about your experience in the comment section 👇 #LLM #AI #MachineLearning
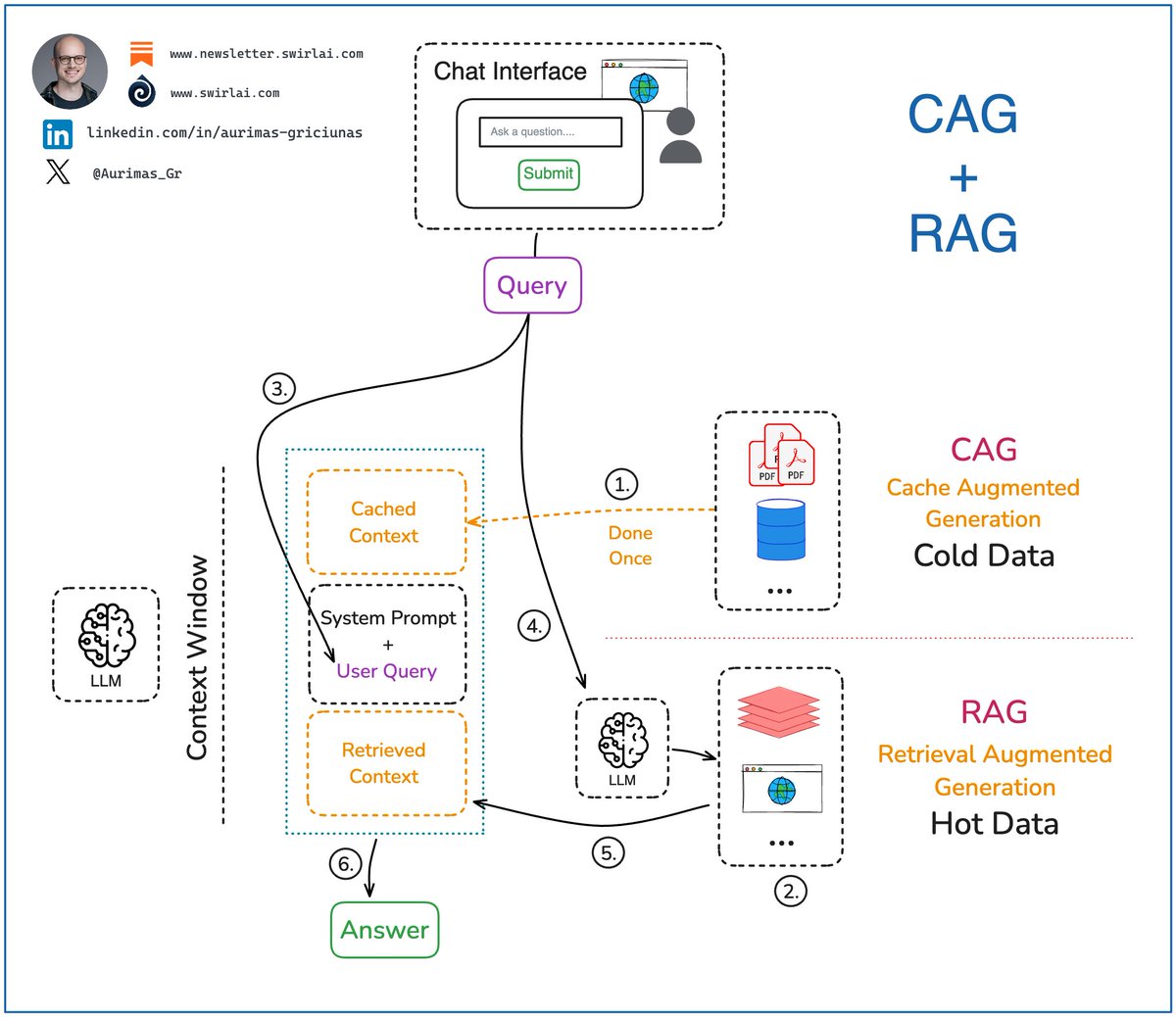
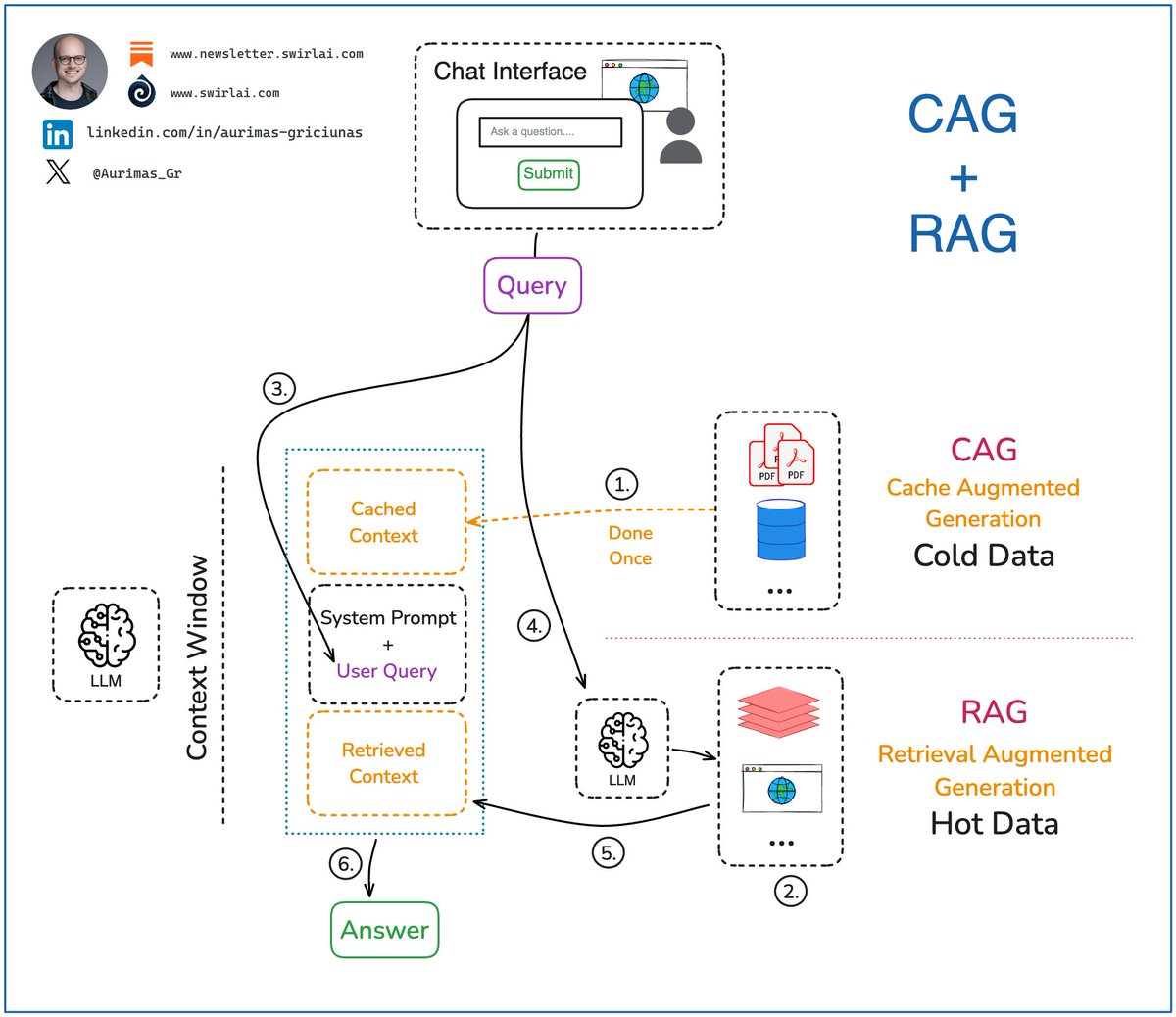
𝗥𝗔𝗚 (Retrieval Augmented Generation) vs. 𝗖𝗔𝗚 (Cache Augmented Generation). There has been a lot of buzz surrounding CAG lately. Let’s see what the differences are betweenRAG and CAG: 𝘙𝘈𝘎 These are the steps for implementing generation for naive RAG: 𝟭. Embed a user query to be used for contextual search via vector DBs or move straight to the step 2 if no contextual search is required. 𝟮. If Contextual search is required, query the context store to retrieve relevant context. If it is not required, use other means to search for relevant data 𝟯. Combine original user query with the system prompt that instructs the final answer construction. 𝟰. Enrich the final prompt with external context retrieved in step 2. 𝟱. Return the final answer to the user. 𝘊𝘈𝘎 𝟭. Pre-compute all of the external context into a KV Cache of the LLM. Cache it in memory. This only needs to be done once, the following steps can be run multiple times without recomputing the initial cache. 𝟮. Pass the system prompt including user query and the system prompt with instructions on how cached context should be used by the LLM. 𝟯. Return the generated answer to the user. After this, clear any generations from the cache and keep only the initially cached context. This makes the LLM ready for next generations. 𝘔𝘺 𝘵𝘩𝘰𝘶𝘨𝘩𝘵𝘴: ➡️ While it has only been described in a white paper for the first time, it is not a novel concept. We have been using different variations of CAG since Anthropic and OpenAI introduced Prompt Caching. ❌ While it might sound strong on paper, LLMs continue to suffer in accuracy while working with extensively long context. ❌ In real use cases, especially enterprise, CAG would cause a lot of security issues due to inability to isolate data. ❌ CAG does not work with constantly changing data as KV Cache would need to be continuously recomputed. ✅ CAG is strong when you need to cache reasonable amount of static data that is not sensitive. ✅ Real magic happens when you combine RAG and CAG into a single system. More on it in future posts, stay tuned in! Have you played with CAG already? Let me know in the comments 👇 #LLM #AI #MachineLearning Want to learn how to build an Agent from scratch without using any LLM Orchestration framework? Check out my article here: newsletter.swirlai.com/p/building-ai-…
Last week I released the first article in my hands-on 𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀 𝗙𝗿𝗼𝗺 𝗦𝗰𝗿𝗮𝘁𝗰𝗵 series. It covers the tool use element of an Agent. I wanted to do this for quite some time now and finally the time has arrived! If you are using any orchestration frameworks for agentic applications, you might be abstracted away from what using a tool really means. I believe that understanding applications from the base building blocks is really important so we are implementing all of the abstractions from scratch. After finishing the project you will learn: ➡️ What AI Agents are. ➡️ How the Tool usage in AI Agents actually works. ➡️ How to build a decorator wrapper that extracts relevant details from a Python function to be passed to the LLM via system prompt. ➡️ How to think about constructing effective system prompts that can be used for Agents. ➡️ How to build an Agent class that is able to plan and execute actions using provided Tools. You can find the article here: newsletter.swirlai.com/p/building-ai-… You can also find a Jupyter notebook and python scripts that complement the article in a GitHub repo (links in the article). Youtube videos coming soon! If you’re looking for something to dig your hands into between holidays be sure to take a look! Second part of the series is coming in a few weeks. Let me know if there are any issues following the project. Feel free to DM me or leave comments here or under the article 👇 #AI #LLM #MachineLearning
𝗔𝗜 𝗔𝗴𝗲𝗻𝘁’𝘀 𝗠𝗲𝗺𝗼𝗿𝘆 is the most important piece of 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴, this is how we define it 👇 In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available. It is useful to group the memory into four types: 𝟭. 𝗘𝗽𝗶𝘀𝗼𝗱𝗶𝗰 - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions. 𝟮. 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers. 𝟯. 𝗣𝗿𝗼𝗰𝗲𝗱𝘂𝗿𝗮𝗹 - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries. 𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand. 𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system. We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory. And that is it! The rest is all about how you architect the topology of your Agentic Systems. Any war stories you have while managing Agent’s memory? Let me know in the comments 👇 #LLM #AI #MachineLearning

Fusion of 𝗥𝗔𝗚 (Retrieval Augmented Generation) and 𝗖𝗔𝗚 (Cache Augmented Generation). How can you benefit from it as AI Engineer? Few months ago there was a lot of hype around a technique called CAG. While it is powerful to its own extent, the real magic happens when you combine CAG with regular RAG. Let’s see what it would look like and what additional considerations should be taken into account. Here are example steps to implement CAG + RAG architecture: 𝘋𝘢𝘵𝘢 𝘗𝘳𝘦𝘱𝘳𝘰𝘤𝘦𝘴𝘴𝘪𝘯𝘨: 𝟭. We use only rarely changing data sources for Cache Augmented Generation. On top of the requirement of data changing rarely we should also think about which of the sources are often hit by relevant queries. Once we have this information, only then we pre-compute all of this selected data into a KV Cache of the LLM. Cache it in memory. This only needs to be done once, the following steps can be run multiple times without recomputing the initial cache. 𝟮. For RAG, if necessary, precompute and store vector embeddings in a compatible database to be searched later in step 4. Sometimes simpler data types are enough for RAG, a regular database might suffice. 𝘘𝘶𝘦𝘳𝘺 𝘗𝘢𝘵𝘩: We can now utilise the preprocessed data. 𝟯. Compose a prompt including user query and the system prompt with instructions on how cached context and retrieved external context should be used by the LLM. 𝟰. Embed a user query to be used for semantic search via vector DBs and query the context store to retrieve relevant data. If semantic search is not required, query other sources, like real time databases or web. 𝟱. Enrich the final prompt with external context retrieved in step 4. 𝟲. Return the final answer to the user. 𝘚𝘰𝘮𝘦 𝘊𝘰𝘯𝘴𝘪𝘥𝘦𝘳𝘢𝘵𝘪𝘰𝘯𝘴: ➡️ Context window is not infinite and even while some models boast enormous context window sizes, the needle in the haystack problem has not yet been solved so use available context wisely and cache only the data you really need. ✅ For some business cases, specific datasets are extremely valuable to be passed to the model as cache. Think about an assistant that has to always comply with a lengthy set of internal rules stored in multiple documents. ✅ While CAG has been popularised for Open Source just recently, it is already viable for some time via Prompt Caching features in OpenAI and Anthropic APIs. It is really easy to start prototyping there. ✅ You should always separate hot and cold data sources, only use cold (data that changes rarely) in your cache, otherwise the data will go stale and the application will go out of sync. ❌ Be very careful about what you cache as the data will be available for all users to query. ❌ It is very hard to ensure RBAC for cached data unless you have a separate model with its own cache per role. Have you used the fusion of CAG and RAG already? Let me know about your results in the comments 👇 #LLM #AI #MachineLearning
How do we implement 𝗧𝗼𝗼𝗹 𝗖𝗮𝗹𝗹𝗶𝗻𝗴 𝘃𝗶𝗮 𝗠𝗖𝗣? Let’s unpack the difference between using MCP to implement Tool Calling and baking the Tools directly into your Agents. I’ve recently seen many MCP vs. Function Calling articles floating around, some misleading. Let’s simplify. ❗️ 𝗖𝗹𝗮𝗿𝗶𝗳𝘆𝗶𝗻𝗴 𝗼𝗻𝗲 𝗱𝗲𝘁𝗮𝗶𝗹: Function Calling and Tool Use in Agentic Systems are almost the same thing. You can implement tools via functions, the only difference is that functions are usually used to enforce stricter structure to the input and output schema. 𝘜𝘴𝘪𝘯𝘨 𝘔𝘊𝘗 𝘵𝘰 𝘦𝘹𝘱𝘰𝘴𝘦 𝘵𝘰𝘰𝘭𝘴 𝘵𝘰 𝘺𝘰𝘶𝘳 𝘈𝘨𝘦𝘯𝘵𝘴: ℹ️ In this case your Agent becomes an MCP Host and implements one or more MCP Clients to communicate with MCP Servers. 𝟭. User Query is passed to the Agent (usually a Python application). 𝟮. The application implements MCP Client and via it retrieves all available tools from the MCP servers. 𝟯. The list of available Tools is passed together with the User Query to a LLM via a prompt. The LLM figures out which tools need to be invoked and with what parameters. 𝟰. The Agent application communicates with the MCP server (via MCP Client) again and sends the tool execution request. After execution completes the Agent receives the required data. 𝟱. User Query is sent to the LLM together with the data retrieved by the Tool calls. 𝟲. The answer is constructed and returned to the user via the Agent. 𝘜𝘴𝘪𝘯𝘨 𝘕𝘢𝘵𝘪𝘷𝘦 𝘍𝘶𝘯𝘤𝘵𝘪𝘰𝘯 𝘊𝘢𝘭𝘭𝘪𝘯𝘨: 𝟭. User Query is passed to the Agent (usually a Python application). 𝟮. All of the available Functions/Tools are defined as part of the Agent code (procedural memory). 𝟯. The list of available Tools is passed together with the User Query to a LLM via a prompt. The LLM figures out which functions need to be invoked and with what parameters. 𝟰. The Agent application directly executes the functions. 𝟱. User Query is sent to the LLM together with the data retrieved after function execution. 𝟲. The answer is constructed and returned to the user via the Agent. 𝗠𝘆 𝘁𝗵𝗼𝘂𝗴𝗵𝘁𝘀: ❗️ Will MCP eat up the practice of Native Function Calling? If we adopt the standard then I believe so. ❗️ Will MCP compete with LLM Orchestration frameworks? I believe MCP will replace the Tool use abstractions as they are used today and frameworks will be responsible mostly for managing the topology and state of the Agentic systems long term. Are you using MCP already to expose Tools to your Agents? Let me know in the comments. #LLM #AI #MachineLearning
Fusion of 𝗥𝗔𝗚 (Retrieval Augmented Generation) and 𝗖𝗔𝗚 (Cache Augmented Generation). How can you benefit from it as AI Engineer? Few months ago there was a lot of hype around a technique called CAG. While it is powerful to its own extent, the real magic happens when you combine CAG with regular RAG. Let’s see what it would look like and what additional considerations should be taken into account. Here are example steps to implement CAG + RAG architecture: 𝘋𝘢𝘵𝘢 𝘗𝘳𝘦𝘱𝘳𝘰𝘤𝘦𝘴𝘴𝘪𝘯𝘨: 𝟭. We use only rarely changing data sources for Cache Augmented Generation. On top of the requirement of data changing rarely we should also think about which of the sources are often hit by relevant queries. Once we have this information, only then we pre-compute all of this selected data into a KV Cache of the LLM. Cache it in memory. This only needs to be done once, the following steps can be run multiple times without recomputing the initial cache. 𝟮. For RAG, if necessary, precompute and store vector embeddings in a compatible database to be searched later in step 4. Sometimes simpler data types are enough for RAG, a regular database might suffice. 𝘘𝘶𝘦𝘳𝘺 𝘗𝘢𝘵𝘩: We can now utilise the preprocessed data. 𝟯. Compose a prompt including user query and the system prompt with instructions on how cached context and retrieved external context should be used by the LLM. 𝟰. Embed a user query to be used for semantic search via vector DBs and query the context store to retrieve relevant data. If semantic search is not required, query other sources, like real time databases or web. 𝟱. Enrich the final prompt with external context retrieved in step 4. 𝟲. Return the final answer to the user. 𝘚𝘰𝘮𝘦 𝘊𝘰𝘯𝘴𝘪𝘥𝘦𝘳𝘢𝘵𝘪𝘰𝘯𝘴: ➡️ Context window is not infinite and even while some models boast enormous context window sizes, the needle in the haystack problem has not yet been solved so use available context wisely and cache only the data you really need. ✅ For some business cases, specific datasets are extremely valuable to be passed to the model as cache. Think about an assistant that has to always comply with a lengthy set of internal rules stored in multiple documents. ✅ While CAG has been popularised for Open Source just recently, it is already viable for some time via Prompt Caching features in OpenAI and Anthropic APIs. It is really easy to start prototyping there. ✅ You should always separate hot and cold data sources, only use cold (data that changes rarely) in your cache, otherwise the data will go stale and the application will go out of sync. ❌ Be very careful about what you cache as the data will be available for all users to query. ❌ It is very hard to ensure RBAC for cached data unless you have a separate model with its own cache per role. Have you used the fusion of CAG and RAG already? Let me know about your results in the comments 👇 #LLM #AI #MachineLearning
You must know these 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗦𝘆𝘀𝘁𝗲𝗺 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀 as an 𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿. If you are building Agentic Systems in an Enterprise setting you will soon discover that the simplest workflow patterns work the best and bring the most business value. At the end of last year Anthropic did a great job summarising the top patterns for these workflows and they still hold strong. Let’s explore what they are and where each can be useful: 𝟭. 𝗣𝗿𝗼𝗺𝗽𝘁 𝗖𝗵𝗮𝗶𝗻𝗶𝗻𝗴: This pattern decomposes a complex task and tries to solve it in manageable pieces by chaining them together. Output of one LLM call becomes an output to another. ✅ In most cases such decomposition results in higher accuracy with sacrifice for latency. ℹ️ In heavy production use cases Prompt Chaining would be combined with following patterns, a pattern replace an LLM Call node in Prompt Chaining pattern. 𝟮. 𝗥𝗼𝘂𝘁𝗶𝗻𝗴: In this pattern, the input is classified into multiple potential paths and the appropriate is taken. ✅ Useful when the workflow is complex and specific topology paths could be more efficiently solved by a specialized workflow. ℹ️ Example: Agentic Chatbot - should I answer the question with RAG or should I perform some actions that a user has prompted for? 𝟯. 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Initial input is split into multiple queries to be passed to the LLM, then the answers are aggregated to produce the final answer. ✅ Useful when speed is important and multiple inputs can be processed in parallel without needing to wait for other outputs. Also, when additional accuracy is required. ℹ️ Example 1: Query rewrite in Agentic RAG to produce multiple different queries for majority voting. Improves accuracy. ℹ️ Example 2: Multiple items are extracted from an invoice, all of them can be processed further in parallel for better speed. 𝟰. 𝗢𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗼𝗿: An orchestrator LLM dynamically breaks down tasks and delegates to other LLMs or sub-workflows. ✅ Useful when the system is complex and there is no clear hardcoded topology path to achieve the final result. ℹ️ Example: Choice of datasets to be used in Agentic RAG. 𝟱. 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗼𝗿-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿: Generator LLM produces a result then Evaluator LLM evaluates it and provides feedback for further improvement if necessary. ✅ Useful for tasks that require continuous refinement. ℹ️ Example: Deep Research Agent workflow when refinement of a report paragraph via continuous web search is required. 𝗧𝗶𝗽𝘀: ❗️ Before going for full fledged Agents you should always try to solve a problem with simpler Workflows described in the article. What are the most complex workflows you have deployed to production? Let me know in the comments 👇 #LLM #AI #MachineLearning
People with Thought Leader archetype
Checking out cool stuff & Catalyzing the singularity 💕💕
Husband, dad, grandad. I’m a Culture-Shaping, People-Encouraging, Team-Building, Thought-Provoking, High-Energy kind of leader.
I ghostwrite thought leadership articles and social media content for busy executives and professionals | 13 years as a Blogger | 7 books published (One banned)
unpack
living vicariously through myself
Je transforme les ambitieux en orateurs magnétiques.
Thoughts on the go…
Become the Leader You’d Follow | Founder @ MGMT | CEO Coach | Advisor | Speaker | Trusted by 300K+ leaders. | Work with us: davekline.com
Your potential hides in the questions you avoid. I ask them.
B2B marketing with taste @_antidotemedia | Follower of Jesus • Morehouse
Psalms 12:1 || @DexariDotCom affiliate || Writer x Clipper
Explore Related Archetypes
If you enjoy the thought leader profiles, you might also like these personality types: