Alex Dimakis is a sharp and detail-oriented academic and AI founder who thrives on dissecting complex AI behaviors with precision and curiosity. As a professor at UC Berkeley and founder of Bespoke Labs AI, Alex blends deep theoretical insights with practical innovation to push the boundaries of understanding in machine learning. His tweets reveal a passion for unraveling the nuances of AI models and a commitment to fostering realistic expectations around their capabilities.
Alex probably proofreads his own tweets with a spellchecker set to 'nitpicky professor mode'—so much detail that even robots get overwhelmed and start doubting their own reasoning skills.
Alex has successfully combined an academic career at a top institution with founding an AI startup, while maintaining influential thought leadership through detailed, high-engagement tweets dissecting the nuances of modern AI systems.
To deepen the collective understanding of AI’s capabilities and limitations, bridging theoretical research with real-world applications, while educating and challenging the AI community to think critically about model reasoning and performance.
Alex values scientific rigor, transparency, and intellectual honesty. He believes in thorough empirical analysis, embracing nuance over hype, and the importance of advancing AI responsibly through careful scrutiny. He is skeptical of oversimplifications and champions a nuanced, data-driven approach to AI research.
Alex’s greatest strength lies in his exceptional analytical mind and ability to communicate complex AI research insights clearly. His academic background combined with entrepreneurial experience allows him to critically assess AI models while influencing the field with fresh, practical ideas.
Tending toward deep technical dives and critical scrutiny, Alex sometimes risks coming across as overly cautious or skeptical, potentially limiting his appeal to audiences craving more optimistic or simplified AI narratives.
On X, Alex should leverage his expertise by sharing thread-style deep dives that break down complex AI topics with accessible analogies, paired with engaging visuals or simplified summaries. Regular interactive Q&A sessions could boost engagement and attract followers interested in thoughtful AI discourse.
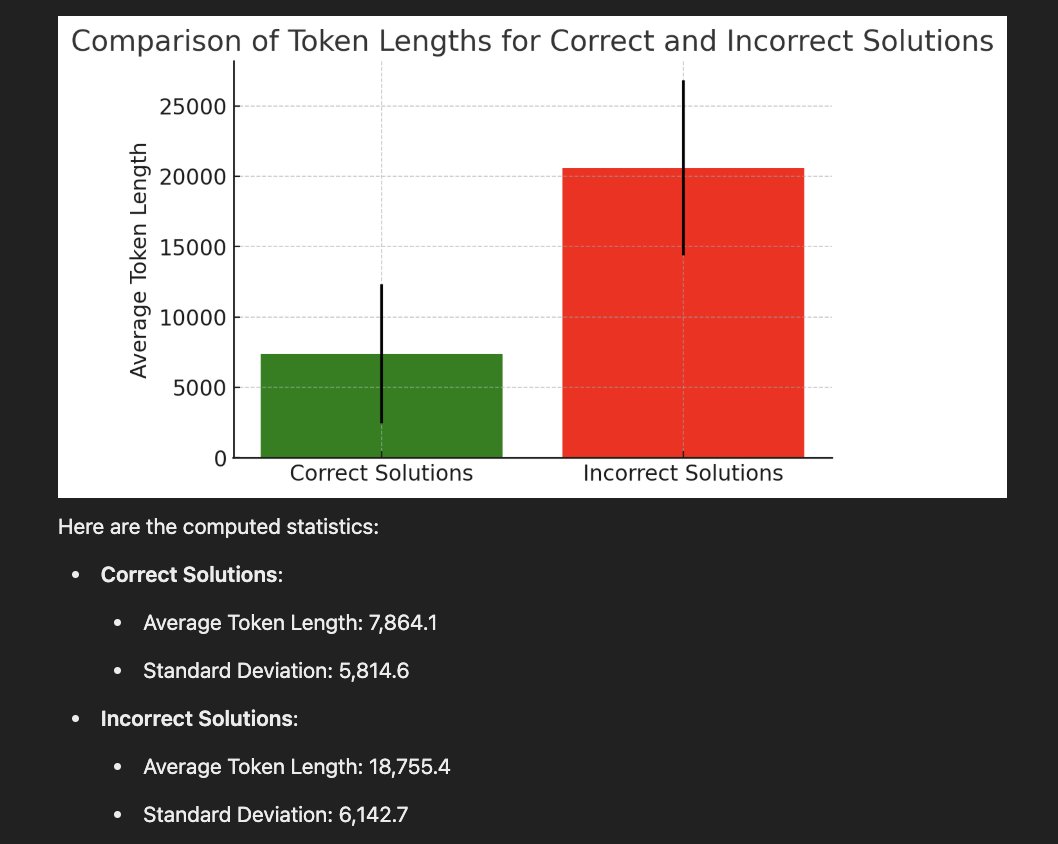
Alex often highlights surprising weaknesses in state-of-the-art models, such as GPT-4’s struggles with basic multiplication and the counterintuitive observation that wrong reasoning model answers tend to be longer than correct ones.
youtube.com/watch?v=zjkBMF…
Probably the best 1h introduction to LLMs that I've seen. And after 20mins its not an introduction, its getting into cutting edge research updates updated up to this month. I had not heard of the data exfiltration by prompt injection or the recent finetuning Poisoning attacks.
github.com/mlfoundations/…
I’m excited to introduce Evalchemy 🧪, a unified platform for evaluating LLMs. If you want to evaluate an LLM, you may want to run popular benchmarks on your model, like MTBench, WildBench, RepoBench, IFEval, AlpacaEval etc as well as standard pre-training metrics like MMLU. This requires you to download and install more than 10 repos, each with different dependencies and issues. This is, as you might expect, an actual nightmare. (1/n)
{"data":{"__meta":{"device":false,"path":"/creators/AlexGDimakis"},"/creators/AlexGDimakis":{"data":{"user":{"id":"29178343","name":"Alex Dimakis","description":"Professor, UC berkeley | Founder @bespokelabsai |","followers_count":21438,"friends_count":2376,"statuses_count":4331,"profile_image_url_https":"https://pbs.twimg.com/profile_images/542926798338543617/KwlwoJRr_normal.jpeg","screen_name":"AlexGDimakis","location":"Berkeley, CA","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"people.eecs.berkeley.edu/~alexdimakis/","expanded_url":"https://people.eecs.berkeley.edu/~alexdimakis/","url":"https://t.co/N8GVYXA2q9","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Alex Dimakis is a sharp and detail-oriented academic and AI founder who thrives on dissecting complex AI behaviors with precision and curiosity. As a professor at UC Berkeley and founder of Bespoke Labs AI, Alex blends deep theoretical insights with practical innovation to push the boundaries of understanding in machine learning. His tweets reveal a passion for unraveling the nuances of AI models and a commitment to fostering realistic expectations around their capabilities.","purpose":"To deepen the collective understanding of AI’s capabilities and limitations, bridging theoretical research with real-world applications, while educating and challenging the AI community to think critically about model reasoning and performance.","beliefs":"Alex values scientific rigor, transparency, and intellectual honesty. He believes in thorough empirical analysis, embracing nuance over hype, and the importance of advancing AI responsibly through careful scrutiny. He is skeptical of oversimplifications and champions a nuanced, data-driven approach to AI research.","facts":"Alex often highlights surprising weaknesses in state-of-the-art models, such as GPT-4’s struggles with basic multiplication and the counterintuitive observation that wrong reasoning model answers tend to be longer than correct ones.","strength":"Alex’s greatest strength lies in his exceptional analytical mind and ability to communicate complex AI research insights clearly. His academic background combined with entrepreneurial experience allows him to critically assess AI models while influencing the field with fresh, practical ideas.","weakness":"Tending toward deep technical dives and critical scrutiny, Alex sometimes risks coming across as overly cautious or skeptical, potentially limiting his appeal to audiences craving more optimistic or simplified AI narratives.","recommendation":"On X, Alex should leverage his expertise by sharing thread-style deep dives that break down complex AI topics with accessible analogies, paired with engaging visuals or simplified summaries. Regular interactive Q&A sessions could boost engagement and attract followers interested in thoughtful AI discourse.","roast":"Alex probably proofreads his own tweets with a spellchecker set to 'nitpicky professor mode'—so much detail that even robots get overwhelmed and start doubting their own reasoning skills.","win":"Alex has successfully combined an academic career at a top institution with founding an AI startup, while maintaining influential thought leadership through detailed, high-engagement tweets dissecting the nuances of modern AI systems."},"tweets":[{"bookmarked":false,"display_text_range":[0,271],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","retweeted":false,"fact_check":null,"id":"1831833630022496515","view_count":929270,"bookmark_count":1295,"created_at":1725578145000,"favorite_count":7892,"quote_count":175,"reply_count":379,"retweet_count":728,"user_id_str":"29178343","conversation_id_str":"1831833630022496515","full_text":"GPT is having a profound effect on how students write. Its verbose style, full of cliches and 'fancy', out of place vocabulary is in every paper and draft I read. A few years back, there were grammar errors and awkwardness -- but at least people had their own voice. Now, scholarship is getting full of robotic triviality.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/kp3TDBaWId","expanded_url":"https://x.com/AlexGDimakis/status/1691600985938858432/photo/1","id_str":"1691600871807741953","indices":[280,303],"media_key":"3_1691600871807741953","media_url_https":"https://pbs.twimg.com/media/F3nGB8nXcAESBLr.png","type":"photo","url":"https://t.co/kp3TDBaWId","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":345,"w":511,"resize":"fit"},"medium":{"h":345,"w":511,"resize":"fit"},"small":{"h":345,"w":511,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":345,"width":511,"focus_rects":[{"x":0,"y":0,"w":511,"h":286},{"x":0,"y":0,"w":345,"h":345},{"x":0,"y":0,"w":303,"h":345},{"x":0,"y":0,"w":173,"h":345},{"x":0,"y":0,"w":511,"h":345}]},"media_results":{"result":{"media_key":"3_1691600871807741953"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/kp3TDBaWId","expanded_url":"https://x.com/AlexGDimakis/status/1691600985938858432/photo/1","id_str":"1691600871807741953","indices":[280,303],"media_key":"3_1691600871807741953","media_url_https":"https://pbs.twimg.com/media/F3nGB8nXcAESBLr.png","type":"photo","url":"https://t.co/kp3TDBaWId","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":345,"w":511,"resize":"fit"},"medium":{"h":345,"w":511,"resize":"fit"},"small":{"h":345,"w":511,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":345,"width":511,"focus_rects":[{"x":0,"y":0,"w":511,"h":286},{"x":0,"y":0,"w":345,"h":345},{"x":0,"y":0,"w":303,"h":345},{"x":0,"y":0,"w":173,"h":345},{"x":0,"y":0,"w":511,"h":345}]},"media_results":{"result":{"media_key":"3_1691600871807741953"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1691600985938858432","view_count":1708209,"bookmark_count":1407,"created_at":1692144078000,"favorite_count":3484,"quote_count":153,"reply_count":247,"retweet_count":530,"user_id_str":"29178343","conversation_id_str":"1691600985938858432","full_text":"I was surprised by a talk Yejin Choi (an NLP expert) gave yesterday in Berkeley, on some surprising weaknesses of GPT4:\nAs many humans know, 237*757=179,409 \nbut GPT4 said 179,289. \n\nFor the easy problem of multiplying two 3 digit numbers, they measured GPT4 accuracy being only 59% accuracy on 3 digit number multiplication. Only 4% on 4 digit number multiplication and zero on 5x5. Adding scratchpad helped GPT4 but only to 92% accuracy on multiplying two 3 digit numbers.\n\nEven more surprisingly, finetuning GPT3 on 1.8m examples of 3 digit multiplication still only gives 55 percent test accuracy (in distribution).\n\n¯\\_(⊙︿⊙)_/¯\n\nSo whats going on? Multiplication is algorithmically very challenging (as are less known algorithmic problems). \nThe authors hypothesize that Transformers have a hard time because they learn linear patterns that they can memorize, maybe compose, but not generally reason with. The paper raises interesting theoretical and practical questions on understanding what Transformers can learn.\n\nThe paper\n\"Faith and Fate: Limits of Transformers on Compositionality\" says:\n\"Our empirical findings suggest that Transformers\nsolve compositional tasks by reducing multi-step compositional reasoning into\nlinearized subgraph matching, without necessarily developing systematic problem solving skills\"","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/IpRWWKdL07","expanded_url":"https://x.com/AlexGDimakis/status/1803293833889042637/photo/1","id_str":"1803293831779287040","indices":[280,303],"media_key":"3_1803293831779287040","media_url_https":"https://pbs.twimg.com/media/GQaWL4zbgAANwp0.png","type":"photo","url":"https://t.co/IpRWWKdL07","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":812,"w":1102,"resize":"fit"},"medium":{"h":812,"w":1102,"resize":"fit"},"small":{"h":501,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":812,"width":1102,"focus_rects":[{"x":0,"y":0,"w":1102,"h":617},{"x":290,"y":0,"w":812,"h":812},{"x":390,"y":0,"w":712,"h":812},{"x":595,"y":0,"w":406,"h":812},{"x":0,"y":0,"w":1102,"h":812}]},"media_results":{"result":{"media_key":"3_1803293831779287040"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/IpRWWKdL07","expanded_url":"https://x.com/AlexGDimakis/status/1803293833889042637/photo/1","id_str":"1803293831779287040","indices":[280,303],"media_key":"3_1803293831779287040","media_url_https":"https://pbs.twimg.com/media/GQaWL4zbgAANwp0.png","type":"photo","url":"https://t.co/IpRWWKdL07","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":812,"w":1102,"resize":"fit"},"medium":{"h":812,"w":1102,"resize":"fit"},"small":{"h":501,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":812,"width":1102,"focus_rects":[{"x":0,"y":0,"w":1102,"h":617},{"x":290,"y":0,"w":812,"h":812},{"x":390,"y":0,"w":712,"h":812},{"x":595,"y":0,"w":406,"h":812},{"x":0,"y":0,"w":1102,"h":812}]},"media_results":{"result":{"media_key":"3_1803293831779287040"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1803293833889042637","view_count":387345,"bookmark_count":1546,"created_at":1718773728000,"favorite_count":2376,"quote_count":78,"reply_count":137,"retweet_count":316,"user_id_str":"29178343","conversation_id_str":"1803293833889042637","full_text":"This paper seems very interesting: say you train an LLM to play chess using only transcripts of games of players up to 1000 elo. Is it possible that the model plays better than 1000 elo? (i.e. \"transcends\" the training data performance?). It seems you get something from nothing, and some information theory arguments that this should be impossible were discussed in conversations I had in the past. But this paper shows this can happen: training on 1000 elo game transcripts and getting an LLM that plays at 1500! Further the authors connect to a clean theoretical framework for why: it's ensembling weak learners, where you get \"something from nothing\" by averaging the independent mistakes of multiple models. The paper argued that you need enough data diversity and careful temperature sampling for the transcendence to occur. I had been thinking along the same lines but didn't think of using chess as a clean measurable way to scientifically measure this. Fantastic work that I'll read I'll more depth.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/27qv9f6QD8","expanded_url":"https://x.com/AlexGDimakis/status/1885447830120362099/photo/1","id_str":"1885447791994167298","indices":[277,300],"media_key":"3_1885447791994167298","media_url_https":"https://pbs.twimg.com/media/Gip0xvxbYAICyR1.jpg","type":"photo","url":"https://t.co/27qv9f6QD8","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":844,"w":1058,"resize":"fit"},"medium":{"h":844,"w":1058,"resize":"fit"},"small":{"h":542,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":844,"width":1058,"focus_rects":[{"x":0,"y":252,"w":1058,"h":592},{"x":0,"y":0,"w":844,"h":844},{"x":0,"y":0,"w":740,"h":844},{"x":0,"y":0,"w":422,"h":844},{"x":0,"y":0,"w":1058,"h":844}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1885447791994167298"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/27qv9f6QD8","expanded_url":"https://x.com/AlexGDimakis/status/1885447830120362099/photo/1","id_str":"1885447791994167298","indices":[277,300],"media_key":"3_1885447791994167298","media_url_https":"https://pbs.twimg.com/media/Gip0xvxbYAICyR1.jpg","type":"photo","url":"https://t.co/27qv9f6QD8","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":844,"w":1058,"resize":"fit"},"medium":{"h":844,"w":1058,"resize":"fit"},"small":{"h":542,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":844,"width":1058,"focus_rects":[{"x":0,"y":252,"w":1058,"h":592},{"x":0,"y":0,"w":844,"h":844},{"x":0,"y":0,"w":740,"h":844},{"x":0,"y":0,"w":422,"h":844},{"x":0,"y":0,"w":1058,"h":844}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1885447791994167298"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1885447830120362099","view_count":218180,"bookmark_count":792,"created_at":1738360767000,"favorite_count":2123,"quote_count":83,"reply_count":145,"retweet_count":218,"user_id_str":"29178343","conversation_id_str":"1885447830120362099","full_text":"Discovered a very interesting thing about DeepSeek-R1 and all reasoning models: The wrong answers are much longer while the correct answers are much shorter. Even on the same question, when we re-run the model, it sometimes produces a short (usually correct) answer or a wrong verbose one. Based on this, I'd like to propose a simple idea called Laconic decoding: Run the model 5 times (in parallel) and pick the answer with the smallest number of tokens. Our preliminary results show that this decoding gives +6-7% on AIME24 with only a few parallel runs. I think this is better (and faster) than consensus decoding.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,277],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","retweeted":false,"fact_check":null,"id":"1881511481164079507","view_count":181609,"bookmark_count":856,"created_at":1737422268000,"favorite_count":1443,"quote_count":14,"reply_count":26,"retweet_count":133,"user_id_str":"29178343","conversation_id_str":"1881511481164079507","full_text":"Most AI researchers I talk to have been a bit shocked by DeepSeek-R1 and its performance. \nMy preliminary understanding nuggets: \n1. Simple post-training recipe called GRPO: Start with a good model and reward for correctness and style outcomes. No PRM, no MCTS no fancy reward models. Basically checks if the answer is correct. 😅\n2. Small models can reason very very well with correct distillation post-training. They released a 1.5B model (!) that is better than Claude and Llama 405B in AIME24. Also, their distilled 7B model seems better than o1 preview. 🤓\n3. The datasets used are not released, if I understand correctly. 🫤\n4. DeepSeek seems to be the best at executing Open AI's original mission right now. We need to catch up.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/jMh8t7o9AS","expanded_url":"https://x.com/AlexGDimakis/status/1921348214525219206/photo/1","id_str":"1921346439831236608","indices":[280,303],"media_key":"3_1921346439831236608","media_url_https":"https://pbs.twimg.com/media/Gqn-aESaMAAMfOy.jpg","type":"photo","url":"https://t.co/jMh8t7o9AS","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1133,"w":2048,"resize":"fit"},"medium":{"h":664,"w":1200,"resize":"fit"},"small":{"h":376,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1307,"width":2362,"focus_rects":[{"x":0,"y":0,"w":2334,"h":1307},{"x":0,"y":0,"w":1307,"h":1307},{"x":0,"y":0,"w":1146,"h":1307},{"x":0,"y":0,"w":654,"h":1307},{"x":0,"y":0,"w":2362,"h":1307}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1921346439831236608"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/jMh8t7o9AS","expanded_url":"https://x.com/AlexGDimakis/status/1921348214525219206/photo/1","id_str":"1921346439831236608","indices":[280,303],"media_key":"3_1921346439831236608","media_url_https":"https://pbs.twimg.com/media/Gqn-aESaMAAMfOy.jpg","type":"photo","url":"https://t.co/jMh8t7o9AS","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1133,"w":2048,"resize":"fit"},"medium":{"h":664,"w":1200,"resize":"fit"},"small":{"h":376,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1307,"width":2362,"focus_rects":[{"x":0,"y":0,"w":2334,"h":1307},{"x":0,"y":0,"w":1307,"h":1307},{"x":0,"y":0,"w":1146,"h":1307},{"x":0,"y":0,"w":654,"h":1307},{"x":0,"y":0,"w":2362,"h":1307}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1921346439831236608"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1921348214525219206","view_count":349239,"bookmark_count":1472,"created_at":1746920085000,"favorite_count":1415,"quote_count":23,"reply_count":38,"retweet_count":196,"user_id_str":"29178343","conversation_id_str":"1921348214525219206","full_text":"\"RL with only one training example\" and \"Test-Time RL\" are two recent papers that I found fascinating. \n\nIn the \"One Training example\" paper \nthe authors find one question and ask the model to solve it again and again. Every time, the model tries 8 times (the Group in GRPO), and a gradient step is performed, to increase the reward which is a very simple verification of the correct answers, repeated thousands of times on the same problem. \n\nThe shocking finding is that the model does not overfit to this one question: RL on one example, makes the model better in MATH500 and other benchmarks. \n(If instead you did SFT repeating one training question-solution finetuning, the model would quickly memorize this answer and overfit). But with RL, the model has to solve the problem itself, since it only sees the question, not the answer. Every time it produces different answers, and this seems to prevent overfitting. The other papers are relying on the same phenomenon: you can have a small number of training questions and re-solve them thousands of times. You can do this for the test set (as test-time RL does) and still not overfit. We also independently saw this by doing RL training on half the test set and seeing benefits in the other half for BFCL agents. \n\nMy thought now is that this shows our RL learning algorithm must be extremely inefficient. When a human is learning by solving a math puzzle, they immediately learn what they can learn by solving it once (or twice). No further benefit would come by assigning the same homework problem to students a tenth time. But in RL, we keep asking the model to re-solve the same question thousands of times, and the model slowly gets better. We should be able to have much better RL learning algorithms since the information is there. (1/2)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1656012895","name":"UC Berkeley EECS","screen_name":"Berkeley_EECS","indices":[486,500]}]},"favorited":false,"lang":"en","retweeted":false,"fact_check":null,"id":"1869124346264043827","view_count":108364,"bookmark_count":76,"created_at":1734468945000,"favorite_count":1359,"quote_count":8,"reply_count":130,"retweet_count":20,"user_id_str":"29178343","conversation_id_str":"1869124346264043827","full_text":"Life update: I am excited to announce that I will be starting as a Professor in UC Berkeley in the EECS Department. I spend 12 wonderful years teaching in UT Austin and I am grateful to all my colleagues and students there and extremely proud of what we have achieved in AI in UT Austin, and I plan to continue my numerous UT close collaborations. I will also continue as Chief Scientist in Bespoke Labs, making it much easier now being in the Bay area. \nI received my Phd in 2008 from @Berkeley_EECS and I am thrilled to be back. I am grateful for this new opportunity.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,268],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1882131703927652762","quoted_status_permalink":{"url":"https://t.co/7n0SUkhtDK","expanded":"https://twitter.com/madiator/status/1882131703927652762","display":"x.com/madiator/statu…"},"retweeted":false,"fact_check":null,"id":"1882134498512666640","view_count":111562,"bookmark_count":632,"created_at":1737570807000,"favorite_count":938,"quote_count":5,"reply_count":19,"retweet_count":132,"user_id_str":"29178343","conversation_id_str":"1882134498512666640","full_text":"DeepSeek-R1 is amazing but they did not release their reasoning dataset. We release a high-quality open reasoning dataset building on the Berkeley NovaSky Sky-T1 pipeline and R1. Using this, we post-train a 32B model Bespoke-Stratos-32B that shows o1-Preview reasoning performance. Surprisingly, we get good performance with only 17k questions-answers while DeepSeek distillation used 800k, i.e. 47x more data. \nWe open-source everything for the community to experiment with.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,132],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1843951197960777760","quoted_status_permalink":{"url":"https://t.co/9iXfdNqX7z","expanded":"https://twitter.com/NobelPrize/status/1843951197960777760","display":"x.com/NobelPrize/sta…"},"retweeted":false,"fact_check":null,"id":"1843995475743228128","view_count":33613,"bookmark_count":30,"created_at":1728477755000,"favorite_count":803,"quote_count":6,"reply_count":11,"retweet_count":54,"user_id_str":"29178343","conversation_id_str":"1843995475743228128","full_text":"For the first (and probably last) time in my life I understand the technical details of both the physics and chemistry Nobel prizes.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,271],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"youtube.com/watch?v=zjkBMF…","expanded_url":"https://www.youtube.com/watch?v=zjkBMFhNj_g&t=2s","url":"https://t.co/9BnP5zuBr9","indices":[0,23]},{"display_url":"youtube.com/watch?v=zjkBMF…","expanded_url":"https://www.youtube.com/watch?v=zjkBMFhNj_g&t=2s","url":"https://t.co/Bb8Zg7dP2D","indices":[0,23]},{"display_url":"youtube.com/watch?v=zjkBMF…","expanded_url":"https://www.youtube.com/watch?v=zjkBMFhNj_g&t=2s","url":"https://t.co/Bb8Zg7dP2D","indices":[0,23]}],"user_mentions":[]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1727595762266026128","view_count":73498,"bookmark_count":483,"created_at":1700725901000,"favorite_count":410,"quote_count":1,"reply_count":2,"retweet_count":50,"user_id_str":"29178343","conversation_id_str":"1727595762266026128","full_text":"https://t.co/Bb8Zg7dP2D\nProbably the best 1h introduction to LLMs that I've seen. And after 20mins its not an introduction, its getting into cutting edge research updates updated up to this month. I had not heard of the data exfiltration by prompt injection or the recent finetuning Poisoning attacks.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,224],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/9peZxgZ2N2","expanded_url":"https://x.com/AlexGDimakis/status/1503807067391418373/photo/1","id_str":"1503803529395376131","indices":[225,248],"media_key":"3_1503803529395376131","media_url_https":"https://pbs.twimg.com/media/FN6VV62XEAMNlnt.jpg","type":"photo","url":"https://t.co/9peZxgZ2N2","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"medium":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"small":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"orig":{"faces":[{"x":121,"y":71,"h":120,"w":120}]}},"sizes":{"large":{"h":394,"w":405,"resize":"fit"},"medium":{"h":394,"w":405,"resize":"fit"},"small":{"h":394,"w":405,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":394,"width":405,"focus_rects":[{"x":0,"y":18,"w":405,"h":227},{"x":0,"y":0,"w":394,"h":394},{"x":0,"y":0,"w":346,"h":394},{"x":74,"y":0,"w":197,"h":394},{"x":0,"y":0,"w":405,"h":394}]},"media_results":{"result":{"media_key":"3_1503803529395376131"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/9peZxgZ2N2","expanded_url":"https://x.com/AlexGDimakis/status/1503807067391418373/photo/1","id_str":"1503803529395376131","indices":[225,248],"media_key":"3_1503803529395376131","media_url_https":"https://pbs.twimg.com/media/FN6VV62XEAMNlnt.jpg","type":"photo","url":"https://t.co/9peZxgZ2N2","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"medium":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"small":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"orig":{"faces":[{"x":121,"y":71,"h":120,"w":120}]}},"sizes":{"large":{"h":394,"w":405,"resize":"fit"},"medium":{"h":394,"w":405,"resize":"fit"},"small":{"h":394,"w":405,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":394,"width":405,"focus_rects":[{"x":0,"y":18,"w":405,"h":227},{"x":0,"y":0,"w":394,"h":394},{"x":0,"y":0,"w":346,"h":394},{"x":74,"y":0,"w":197,"h":394},{"x":0,"y":0,"w":405,"h":394}]},"media_results":{"result":{"media_key":"3_1503803529395376131"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1503807067391418373","view_count":0,"bookmark_count":21,"created_at":1647370518000,"favorite_count":367,"quote_count":2,"reply_count":10,"retweet_count":50,"user_id_str":"29178343","conversation_id_str":"1503807067391418373","full_text":"I was informed that Alexander Vardy, a giant in coding theory passed away. A tragic loss for his family, UCSD and academia. Alex's many discoveries include the Polar decoding algorithm used in the 5G wireless standard, (1/3) https://t.co/9peZxgZ2N2","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,235],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/llz3e2ivd2","expanded_url":"https://twitter.com/i/status/1654559695359860736/video/1","id_str":"1654559027320483840","indices":[212,235],"media_key":"7_1654559027320483840","media_url_https":"https://pbs.twimg.com/ext_tw_video_thumb/1654559027320483840/pu/img/8gpzSYAPueJRQ81h.jpg","source_status_id_str":"1654559695359860736","source_user_id_str":"1573710710852489216","type":"video","url":"https://t.co/LLZ3e2IVd2","additional_media_info":{"monetizable":false,"source_user":{"user_results":{"result":{"__typename":"User","id":"VXNlcjoxNTczNzEwNzEwODUyNDg5MjE2","rest_id":"1573710710852489216","affiliates_highlighted_label":{},"has_graduated_access":true,"is_blue_verified":true,"profile_image_shape":"Circle","legacy":{"following":false,"can_dm":true,"can_media_tag":true,"created_at":"Sat Sep 24 16:27:40 +0000 2022","default_profile":true,"default_profile_image":false,"description":"The latest rumors and developments in the world of artificial intelligence. DM to include your AI project in the newsletter.","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"aibreakfast.beehiiv.com/subscribe","expanded_url":"http://aibreakfast.beehiiv.com/subscribe","url":"https://t.co/BmZGzjW4Bj","indices":[0,23]}]}},"fast_followers_count":0,"favourites_count":4546,"followers_count":180252,"friends_count":259,"has_custom_timelines":true,"is_translator":false,"listed_count":2810,"location":"Join 56,000 on the newsletter→","media_count":695,"name":"AI Breakfast","normal_followers_count":180252,"pinned_tweet_ids_str":["1739023672160002490"],"possibly_sensitive":false,"profile_banner_url":"https://pbs.twimg.com/profile_banners/1573710710852489216/1669597417","profile_image_url_https":"https://pbs.twimg.com/profile_images/1597035080421019649/QnsiETGG_normal.jpg","profile_interstitial_type":"","screen_name":"AiBreakfast","statuses_count":2179,"translator_type":"none","url":"https://t.co/BmZGzjW4Bj","verified":false,"want_retweets":false,"withheld_in_countries":[]},"professional":{"rest_id":"1574062604259139584","professional_type":"Creator","category":[]},"tipjar_settings":{}}}}},"ext_media_availability":{"status":"Available"},"sizes":{"large":{"h":1080,"w":1920,"resize":"fit"},"medium":{"h":675,"w":1200,"resize":"fit"},"small":{"h":383,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1080,"width":1920,"focus_rects":[]},"video_info":{"aspect_ratio":[16,9],"duration_millis":44966,"variants":[{"content_type":"application/x-mpegURL","url":"https://video.twimg.com/ext_tw_video/1654559027320483840/pu/pl/zzKJfYHA14XmJ6Rb.m3u8?tag=12"},{"bitrate":256000,"content_type":"video/mp4","url":"https://video.twimg.com/ext_tw_video/1654559027320483840/pu/vid/480x270/Gn9Me6ORscytEAht.mp4?tag=12"},{"bitrate":832000,"content_type":"video/mp4","url":"https://video.twimg.com/ext_tw_video/1654559027320483840/pu/vid/640x360/uEfG62GBIlMlJuks.mp4?tag=12"},{"bitrate":2176000,"content_type":"video/mp4","url":"https://video.twimg.com/ext_tw_video/1654559027320483840/pu/vid/1280x720/UC85Ciwf9lJWdoDi.mp4?tag=12"}]},"media_results":{"result":{"media_key":"7_1654559027320483840"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/llz3e2ivd2","expanded_url":"https://twitter.com/i/status/1654559695359860736/video/1","id_str":"1654559027320483840","indices":[212,235],"media_key":"7_1654559027320483840","media_url_https":"https://pbs.twimg.com/ext_tw_video_thumb/1654559027320483840/pu/img/8gpzSYAPueJRQ81h.jpg","source_status_id_str":"1654559695359860736","source_user_id_str":"1573710710852489216","type":"video","url":"https://t.co/LLZ3e2IVd2","additional_media_info":{"monetizable":false,"source_user":{"user_results":{"result":{"__typename":"User","id":"VXNlcjoxNTczNzEwNzEwODUyNDg5MjE2","rest_id":"1573710710852489216","affiliates_highlighted_label":{},"has_graduated_access":true,"is_blue_verified":true,"profile_image_shape":"Circle","legacy":{"following":false,"can_dm":true,"can_media_tag":true,"created_at":"Sat Sep 24 16:27:40 +0000 2022","default_profile":true,"default_profile_image":false,"description":"The latest rumors and developments in the world of artificial intelligence. DM to include your AI project in the newsletter.","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"aibreakfast.beehiiv.com/subscribe","expanded_url":"http://aibreakfast.beehiiv.com/subscribe","url":"https://t.co/BmZGzjW4Bj","indices":[0,23]}]}},"fast_followers_count":0,"favourites_count":4546,"followers_count":180252,"friends_count":259,"has_custom_timelines":true,"is_translator":false,"listed_count":2810,"location":"Join 56,000 on the newsletter→","media_count":695,"name":"AI Breakfast","normal_followers_count":180252,"pinned_tweet_ids_str":["1739023672160002490"],"possibly_sensitive":false,"profile_banner_url":"https://pbs.twimg.com/profile_banners/1573710710852489216/1669597417","profile_image_url_https":"https://pbs.twimg.com/profile_images/1597035080421019649/QnsiETGG_normal.jpg","profile_interstitial_type":"","screen_name":"AiBreakfast","statuses_count":2179,"translator_type":"none","url":"https://t.co/BmZGzjW4Bj","verified":false,"want_retweets":false,"withheld_in_countries":[]},"professional":{"rest_id":"1574062604259139584","professional_type":"Creator","category":[]},"tipjar_settings":{}}}}},"ext_media_availability":{"status":"Available"},"sizes":{"large":{"h":1080,"w":1920,"resize":"fit"},"medium":{"h":675,"w":1200,"resize":"fit"},"small":{"h":383,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1080,"width":1920,"focus_rects":[]},"video_info":{"aspect_ratio":[16,9],"duration_millis":44966,"variants":[{"content_type":"application/x-mpegURL","url":"https://video.twimg.com/ext_tw_video/1654559027320483840/pu/pl/zzKJfYHA14XmJ6Rb.m3u8?tag=12"},{"bitrate":256000,"content_type":"video/mp4","url":"https://video.twimg.com/ext_tw_video/1654559027320483840/pu/vid/480x270/Gn9Me6ORscytEAht.mp4?tag=12"},{"bitrate":832000,"content_type":"video/mp4","url":"https://video.twimg.com/ext_tw_video/1654559027320483840/pu/vid/640x360/uEfG62GBIlMlJuks.mp4?tag=12"},{"bitrate":2176000,"content_type":"video/mp4","url":"https://video.twimg.com/ext_tw_video/1654559027320483840/pu/vid/1280x720/UC85Ciwf9lJWdoDi.mp4?tag=12"}]},"media_results":{"result":{"media_key":"7_1654559027320483840"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1655056946150481922","view_count":29005,"bookmark_count":56,"created_at":1683431300000,"favorite_count":323,"quote_count":3,"reply_count":1,"retweet_count":44,"user_id_str":"29178343","conversation_id_str":"1655056946150481922","full_text":"New neural renderer by Nvidia. The model adds fingerprints, smudges and dust and generates renders indistinguishable from real to me. Oh, and its done at *real-time!*. Can't wait to see games using this. (1/2)\n\nhttps://t.co/LLZ3e2IVd2","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,269],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/W9orEsg2v2","expanded_url":"https://x.com/AlexGDimakis/status/1965947230696910935/photo/1","id_str":"1965946699823853568","indices":[270,293],"media_key":"3_1965946699823853568","media_url_https":"https://pbs.twimg.com/media/G0hyG4JaMAACcfP.jpg","type":"photo","url":"https://t.co/W9orEsg2v2","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1224,"w":2048,"resize":"fit"},"medium":{"h":717,"w":1200,"resize":"fit"},"small":{"h":407,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1564,"width":2616,"focus_rects":[{"x":0,"y":0,"w":2616,"h":1465},{"x":0,"y":0,"w":1564,"h":1564},{"x":0,"y":0,"w":1372,"h":1564},{"x":0,"y":0,"w":782,"h":1564},{"x":0,"y":0,"w":2616,"h":1564}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1965946699823853568"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/W9orEsg2v2","expanded_url":"https://x.com/AlexGDimakis/status/1965947230696910935/photo/1","id_str":"1965946699823853568","indices":[270,293],"media_key":"3_1965946699823853568","media_url_https":"https://pbs.twimg.com/media/G0hyG4JaMAACcfP.jpg","type":"photo","url":"https://t.co/W9orEsg2v2","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1224,"w":2048,"resize":"fit"},"medium":{"h":717,"w":1200,"resize":"fit"},"small":{"h":407,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1564,"width":2616,"focus_rects":[{"x":0,"y":0,"w":2616,"h":1465},{"x":0,"y":0,"w":1564,"h":1564},{"x":0,"y":0,"w":1372,"h":1564},{"x":0,"y":0,"w":782,"h":1564},{"x":0,"y":0,"w":2616,"h":1564}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1965946699823853568"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1965947230696910935","view_count":25987,"bookmark_count":328,"created_at":1757553319000,"favorite_count":304,"quote_count":6,"reply_count":4,"retweet_count":30,"user_id_str":"29178343","conversation_id_str":"1965947230696910935","full_text":"What are RL environments? Are they just evals? There is significant confusion in the community, so here is my opinion: My answer is inspired by Terminal-bench, an elegant framework for creating RL environments, evaluating agents and even training agents. \n\nFirst, an RL environment is simply a Docker container. It contains three things: \n1. A snapshot of the state of the world when a problem happened.\n2. A task description and \n3. A reward that verifies if the agent has solved the task. Can be using LLM as a judge or run tests. \n\nFor example, lets take the 'broken-python' environment in Terminal bench. \nThe Dockerfile setups the container: Installs Python and intentionally breaks it by removing critical files \nE.g. install python and \nRUN rm -rf /usr/local/lib/python3.13/site-packages/pip\n\nThe task is \"There's something wrong with my python- I can't install packages with pip.\"\nThe verifier tests if pip works by trying to install a test package. \nNow the agent can try anything it wants to fix pip, by writing bash commands, or using any tools available.\n(1/2)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,277],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qaMYX2DZMI","expanded_url":"https://x.com/AlexGDimakis/status/1950249255127372000/photo/1","id_str":"1950248238004514816","indices":[278,301],"media_key":"3_1950248238004514816","media_url_https":"https://pbs.twimg.com/media/GxCscIoXMAAm4kh.jpg","type":"photo","url":"https://t.co/qaMYX2DZMI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":534,"w":2042,"resize":"fit"},"medium":{"h":314,"w":1200,"resize":"fit"},"small":{"h":178,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":534,"width":2042,"focus_rects":[{"x":896,"y":0,"w":954,"h":534},{"x":1106,"y":0,"w":534,"h":534},{"x":1139,"y":0,"w":468,"h":534},{"x":1240,"y":0,"w":267,"h":534},{"x":0,"y":0,"w":2042,"h":534}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1950248238004514816"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/qaMYX2DZMI","expanded_url":"https://x.com/AlexGDimakis/status/1950249255127372000/photo/1","id_str":"1950248238004514816","indices":[278,301],"media_key":"3_1950248238004514816","media_url_https":"https://pbs.twimg.com/media/GxCscIoXMAAm4kh.jpg","type":"photo","url":"https://t.co/qaMYX2DZMI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":534,"w":2042,"resize":"fit"},"medium":{"h":314,"w":1200,"resize":"fit"},"small":{"h":178,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":534,"width":2042,"focus_rects":[{"x":896,"y":0,"w":954,"h":534},{"x":1106,"y":0,"w":534,"h":534},{"x":1139,"y":0,"w":468,"h":534},{"x":1240,"y":0,"w":267,"h":534},{"x":0,"y":0,"w":2042,"h":534}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1950248238004514816"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1950249255127372000","view_count":26134,"bookmark_count":40,"created_at":1753810630000,"favorite_count":295,"quote_count":2,"reply_count":28,"retweet_count":18,"user_id_str":"29178343","conversation_id_str":"1950249255127372000","full_text":"I am excited to announce that our AI institute (Institute for Foundations of Machine Learning, IFML) has been renewed. \nIFML was part of the first cohort of AI Institutes announced in 2020. Led by UT Austin, the new award will build on the trajectory of the past five years and develop new foundational tools to advance generative AI. NSF IFML's work on diffusion models is a key technology behind major Google products, powering widely used generative models such as Stable Diffusion 3 and Flux. In it's next phase, NSF IFML will expand generative AI to new domains, including protein engineering, clinical imaging, new methods to handle noisy data, improve agent reliability and open source AI. (1/n)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,235],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1930671826159780014","quoted_status_permalink":{"url":"https://t.co/oH6QMUBxGh","expanded":"https://twitter.com/ryanmart3n/status/1930671826159780014","display":"x.com/ryanmart3n/sta…"},"retweeted":false,"fact_check":null,"id":"1930674344126234887","view_count":17420,"bookmark_count":102,"created_at":1749143608000,"favorite_count":252,"quote_count":1,"reply_count":5,"retweet_count":27,"user_id_str":"29178343","conversation_id_str":"1930674344126234887","full_text":"I'm excited to announce what we have been working on for months. Announcing OpenThinker3, the strongest 7B reasoning model with open data. Also more than 1000 experiments on what works and what doesn't for post-training data curation.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1854297515539255671","quoted_status_permalink":{"url":"https://t.co/Vfy8VvlWqM","expanded":"https://twitter.com/rohanpaul_ai/status/1854297515539255671","display":"x.com/rohanpaul_ai/s…"},"retweeted":false,"fact_check":null,"id":"1854428769165123901","view_count":36293,"bookmark_count":315,"created_at":1730965246000,"favorite_count":243,"quote_count":0,"reply_count":4,"retweet_count":35,"user_id_str":"29178343","conversation_id_str":"1854428769165123901","full_text":"Ok this paper seems super interesting and also makes me want to teach graphical models again. The question is, when does chain of thought help, and the answer proposed is “ finding that intermediate steps are only helpful\nwhen the training data is locally structured with respect to dependencies between variables.” So it depends on the training data and they test that by training on different types of synthetic datasets. Also has theory and seems to do the entire formulation using Bayes nets which is very cool, and I’ll try to understand this more. Any insights welcome.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}],"ctweets":[{"bookmarked":false,"display_text_range":[0,271],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","retweeted":false,"fact_check":null,"id":"1831833630022496515","view_count":929270,"bookmark_count":1295,"created_at":1725578145000,"favorite_count":7892,"quote_count":175,"reply_count":379,"retweet_count":728,"user_id_str":"29178343","conversation_id_str":"1831833630022496515","full_text":"GPT is having a profound effect on how students write. Its verbose style, full of cliches and 'fancy', out of place vocabulary is in every paper and draft I read. A few years back, there were grammar errors and awkwardness -- but at least people had their own voice. Now, scholarship is getting full of robotic triviality.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/kp3TDBaWId","expanded_url":"https://x.com/AlexGDimakis/status/1691600985938858432/photo/1","id_str":"1691600871807741953","indices":[280,303],"media_key":"3_1691600871807741953","media_url_https":"https://pbs.twimg.com/media/F3nGB8nXcAESBLr.png","type":"photo","url":"https://t.co/kp3TDBaWId","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":345,"w":511,"resize":"fit"},"medium":{"h":345,"w":511,"resize":"fit"},"small":{"h":345,"w":511,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":345,"width":511,"focus_rects":[{"x":0,"y":0,"w":511,"h":286},{"x":0,"y":0,"w":345,"h":345},{"x":0,"y":0,"w":303,"h":345},{"x":0,"y":0,"w":173,"h":345},{"x":0,"y":0,"w":511,"h":345}]},"media_results":{"result":{"media_key":"3_1691600871807741953"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/kp3TDBaWId","expanded_url":"https://x.com/AlexGDimakis/status/1691600985938858432/photo/1","id_str":"1691600871807741953","indices":[280,303],"media_key":"3_1691600871807741953","media_url_https":"https://pbs.twimg.com/media/F3nGB8nXcAESBLr.png","type":"photo","url":"https://t.co/kp3TDBaWId","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":345,"w":511,"resize":"fit"},"medium":{"h":345,"w":511,"resize":"fit"},"small":{"h":345,"w":511,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":345,"width":511,"focus_rects":[{"x":0,"y":0,"w":511,"h":286},{"x":0,"y":0,"w":345,"h":345},{"x":0,"y":0,"w":303,"h":345},{"x":0,"y":0,"w":173,"h":345},{"x":0,"y":0,"w":511,"h":345}]},"media_results":{"result":{"media_key":"3_1691600871807741953"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1691600985938858432","view_count":1708209,"bookmark_count":1407,"created_at":1692144078000,"favorite_count":3484,"quote_count":153,"reply_count":247,"retweet_count":530,"user_id_str":"29178343","conversation_id_str":"1691600985938858432","full_text":"I was surprised by a talk Yejin Choi (an NLP expert) gave yesterday in Berkeley, on some surprising weaknesses of GPT4:\nAs many humans know, 237*757=179,409 \nbut GPT4 said 179,289. \n\nFor the easy problem of multiplying two 3 digit numbers, they measured GPT4 accuracy being only 59% accuracy on 3 digit number multiplication. Only 4% on 4 digit number multiplication and zero on 5x5. Adding scratchpad helped GPT4 but only to 92% accuracy on multiplying two 3 digit numbers.\n\nEven more surprisingly, finetuning GPT3 on 1.8m examples of 3 digit multiplication still only gives 55 percent test accuracy (in distribution).\n\n¯\\_(⊙︿⊙)_/¯\n\nSo whats going on? Multiplication is algorithmically very challenging (as are less known algorithmic problems). \nThe authors hypothesize that Transformers have a hard time because they learn linear patterns that they can memorize, maybe compose, but not generally reason with. The paper raises interesting theoretical and practical questions on understanding what Transformers can learn.\n\nThe paper\n\"Faith and Fate: Limits of Transformers on Compositionality\" says:\n\"Our empirical findings suggest that Transformers\nsolve compositional tasks by reducing multi-step compositional reasoning into\nlinearized subgraph matching, without necessarily developing systematic problem solving skills\"","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/27qv9f6QD8","expanded_url":"https://x.com/AlexGDimakis/status/1885447830120362099/photo/1","id_str":"1885447791994167298","indices":[277,300],"media_key":"3_1885447791994167298","media_url_https":"https://pbs.twimg.com/media/Gip0xvxbYAICyR1.jpg","type":"photo","url":"https://t.co/27qv9f6QD8","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":844,"w":1058,"resize":"fit"},"medium":{"h":844,"w":1058,"resize":"fit"},"small":{"h":542,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":844,"width":1058,"focus_rects":[{"x":0,"y":252,"w":1058,"h":592},{"x":0,"y":0,"w":844,"h":844},{"x":0,"y":0,"w":740,"h":844},{"x":0,"y":0,"w":422,"h":844},{"x":0,"y":0,"w":1058,"h":844}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1885447791994167298"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/27qv9f6QD8","expanded_url":"https://x.com/AlexGDimakis/status/1885447830120362099/photo/1","id_str":"1885447791994167298","indices":[277,300],"media_key":"3_1885447791994167298","media_url_https":"https://pbs.twimg.com/media/Gip0xvxbYAICyR1.jpg","type":"photo","url":"https://t.co/27qv9f6QD8","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":844,"w":1058,"resize":"fit"},"medium":{"h":844,"w":1058,"resize":"fit"},"small":{"h":542,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":844,"width":1058,"focus_rects":[{"x":0,"y":252,"w":1058,"h":592},{"x":0,"y":0,"w":844,"h":844},{"x":0,"y":0,"w":740,"h":844},{"x":0,"y":0,"w":422,"h":844},{"x":0,"y":0,"w":1058,"h":844}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1885447791994167298"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1885447830120362099","view_count":218180,"bookmark_count":792,"created_at":1738360767000,"favorite_count":2123,"quote_count":83,"reply_count":145,"retweet_count":218,"user_id_str":"29178343","conversation_id_str":"1885447830120362099","full_text":"Discovered a very interesting thing about DeepSeek-R1 and all reasoning models: The wrong answers are much longer while the correct answers are much shorter. Even on the same question, when we re-run the model, it sometimes produces a short (usually correct) answer or a wrong verbose one. Based on this, I'd like to propose a simple idea called Laconic decoding: Run the model 5 times (in parallel) and pick the answer with the smallest number of tokens. Our preliminary results show that this decoding gives +6-7% on AIME24 with only a few parallel runs. I think this is better (and faster) than consensus decoding.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/IpRWWKdL07","expanded_url":"https://x.com/AlexGDimakis/status/1803293833889042637/photo/1","id_str":"1803293831779287040","indices":[280,303],"media_key":"3_1803293831779287040","media_url_https":"https://pbs.twimg.com/media/GQaWL4zbgAANwp0.png","type":"photo","url":"https://t.co/IpRWWKdL07","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":812,"w":1102,"resize":"fit"},"medium":{"h":812,"w":1102,"resize":"fit"},"small":{"h":501,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":812,"width":1102,"focus_rects":[{"x":0,"y":0,"w":1102,"h":617},{"x":290,"y":0,"w":812,"h":812},{"x":390,"y":0,"w":712,"h":812},{"x":595,"y":0,"w":406,"h":812},{"x":0,"y":0,"w":1102,"h":812}]},"media_results":{"result":{"media_key":"3_1803293831779287040"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/IpRWWKdL07","expanded_url":"https://x.com/AlexGDimakis/status/1803293833889042637/photo/1","id_str":"1803293831779287040","indices":[280,303],"media_key":"3_1803293831779287040","media_url_https":"https://pbs.twimg.com/media/GQaWL4zbgAANwp0.png","type":"photo","url":"https://t.co/IpRWWKdL07","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":812,"w":1102,"resize":"fit"},"medium":{"h":812,"w":1102,"resize":"fit"},"small":{"h":501,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":812,"width":1102,"focus_rects":[{"x":0,"y":0,"w":1102,"h":617},{"x":290,"y":0,"w":812,"h":812},{"x":390,"y":0,"w":712,"h":812},{"x":595,"y":0,"w":406,"h":812},{"x":0,"y":0,"w":1102,"h":812}]},"media_results":{"result":{"media_key":"3_1803293831779287040"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1803293833889042637","view_count":387345,"bookmark_count":1546,"created_at":1718773728000,"favorite_count":2376,"quote_count":78,"reply_count":137,"retweet_count":316,"user_id_str":"29178343","conversation_id_str":"1803293833889042637","full_text":"This paper seems very interesting: say you train an LLM to play chess using only transcripts of games of players up to 1000 elo. Is it possible that the model plays better than 1000 elo? (i.e. \"transcends\" the training data performance?). It seems you get something from nothing, and some information theory arguments that this should be impossible were discussed in conversations I had in the past. But this paper shows this can happen: training on 1000 elo game transcripts and getting an LLM that plays at 1500! Further the authors connect to a clean theoretical framework for why: it's ensembling weak learners, where you get \"something from nothing\" by averaging the independent mistakes of multiple models. The paper argued that you need enough data diversity and careful temperature sampling for the transcendence to occur. I had been thinking along the same lines but didn't think of using chess as a clean measurable way to scientifically measure this. Fantastic work that I'll read I'll more depth.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1656012895","name":"UC Berkeley EECS","screen_name":"Berkeley_EECS","indices":[486,500]}]},"favorited":false,"lang":"en","retweeted":false,"fact_check":null,"id":"1869124346264043827","view_count":108364,"bookmark_count":76,"created_at":1734468945000,"favorite_count":1359,"quote_count":8,"reply_count":130,"retweet_count":20,"user_id_str":"29178343","conversation_id_str":"1869124346264043827","full_text":"Life update: I am excited to announce that I will be starting as a Professor in UC Berkeley in the EECS Department. I spend 12 wonderful years teaching in UT Austin and I am grateful to all my colleagues and students there and extremely proud of what we have achieved in AI in UT Austin, and I plan to continue my numerous UT close collaborations. I will also continue as Chief Scientist in Bespoke Labs, making it much easier now being in the Bay area. \nI received my Phd in 2008 from @Berkeley_EECS and I am thrilled to be back. I am grateful for this new opportunity.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/jMh8t7o9AS","expanded_url":"https://x.com/AlexGDimakis/status/1921348214525219206/photo/1","id_str":"1921346439831236608","indices":[280,303],"media_key":"3_1921346439831236608","media_url_https":"https://pbs.twimg.com/media/Gqn-aESaMAAMfOy.jpg","type":"photo","url":"https://t.co/jMh8t7o9AS","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1133,"w":2048,"resize":"fit"},"medium":{"h":664,"w":1200,"resize":"fit"},"small":{"h":376,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1307,"width":2362,"focus_rects":[{"x":0,"y":0,"w":2334,"h":1307},{"x":0,"y":0,"w":1307,"h":1307},{"x":0,"y":0,"w":1146,"h":1307},{"x":0,"y":0,"w":654,"h":1307},{"x":0,"y":0,"w":2362,"h":1307}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1921346439831236608"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/jMh8t7o9AS","expanded_url":"https://x.com/AlexGDimakis/status/1921348214525219206/photo/1","id_str":"1921346439831236608","indices":[280,303],"media_key":"3_1921346439831236608","media_url_https":"https://pbs.twimg.com/media/Gqn-aESaMAAMfOy.jpg","type":"photo","url":"https://t.co/jMh8t7o9AS","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1133,"w":2048,"resize":"fit"},"medium":{"h":664,"w":1200,"resize":"fit"},"small":{"h":376,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1307,"width":2362,"focus_rects":[{"x":0,"y":0,"w":2334,"h":1307},{"x":0,"y":0,"w":1307,"h":1307},{"x":0,"y":0,"w":1146,"h":1307},{"x":0,"y":0,"w":654,"h":1307},{"x":0,"y":0,"w":2362,"h":1307}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1921346439831236608"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1921348214525219206","view_count":349239,"bookmark_count":1472,"created_at":1746920085000,"favorite_count":1415,"quote_count":23,"reply_count":38,"retweet_count":196,"user_id_str":"29178343","conversation_id_str":"1921348214525219206","full_text":"\"RL with only one training example\" and \"Test-Time RL\" are two recent papers that I found fascinating. \n\nIn the \"One Training example\" paper \nthe authors find one question and ask the model to solve it again and again. Every time, the model tries 8 times (the Group in GRPO), and a gradient step is performed, to increase the reward which is a very simple verification of the correct answers, repeated thousands of times on the same problem. \n\nThe shocking finding is that the model does not overfit to this one question: RL on one example, makes the model better in MATH500 and other benchmarks. \n(If instead you did SFT repeating one training question-solution finetuning, the model would quickly memorize this answer and overfit). But with RL, the model has to solve the problem itself, since it only sees the question, not the answer. Every time it produces different answers, and this seems to prevent overfitting. The other papers are relying on the same phenomenon: you can have a small number of training questions and re-solve them thousands of times. You can do this for the test set (as test-time RL does) and still not overfit. We also independently saw this by doing RL training on half the test set and seeing benefits in the other half for BFCL agents. \n\nMy thought now is that this shows our RL learning algorithm must be extremely inefficient. When a human is learning by solving a math puzzle, they immediately learn what they can learn by solving it once (or twice). No further benefit would come by assigning the same homework problem to students a tenth time. But in RL, we keep asking the model to re-solve the same question thousands of times, and the model slowly gets better. We should be able to have much better RL learning algorithms since the information is there. (1/2)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,277],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qaMYX2DZMI","expanded_url":"https://x.com/AlexGDimakis/status/1950249255127372000/photo/1","id_str":"1950248238004514816","indices":[278,301],"media_key":"3_1950248238004514816","media_url_https":"https://pbs.twimg.com/media/GxCscIoXMAAm4kh.jpg","type":"photo","url":"https://t.co/qaMYX2DZMI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":534,"w":2042,"resize":"fit"},"medium":{"h":314,"w":1200,"resize":"fit"},"small":{"h":178,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":534,"width":2042,"focus_rects":[{"x":896,"y":0,"w":954,"h":534},{"x":1106,"y":0,"w":534,"h":534},{"x":1139,"y":0,"w":468,"h":534},{"x":1240,"y":0,"w":267,"h":534},{"x":0,"y":0,"w":2042,"h":534}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1950248238004514816"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/qaMYX2DZMI","expanded_url":"https://x.com/AlexGDimakis/status/1950249255127372000/photo/1","id_str":"1950248238004514816","indices":[278,301],"media_key":"3_1950248238004514816","media_url_https":"https://pbs.twimg.com/media/GxCscIoXMAAm4kh.jpg","type":"photo","url":"https://t.co/qaMYX2DZMI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":534,"w":2042,"resize":"fit"},"medium":{"h":314,"w":1200,"resize":"fit"},"small":{"h":178,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":534,"width":2042,"focus_rects":[{"x":896,"y":0,"w":954,"h":534},{"x":1106,"y":0,"w":534,"h":534},{"x":1139,"y":0,"w":468,"h":534},{"x":1240,"y":0,"w":267,"h":534},{"x":0,"y":0,"w":2042,"h":534}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1950248238004514816"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1950249255127372000","view_count":26134,"bookmark_count":40,"created_at":1753810630000,"favorite_count":295,"quote_count":2,"reply_count":28,"retweet_count":18,"user_id_str":"29178343","conversation_id_str":"1950249255127372000","full_text":"I am excited to announce that our AI institute (Institute for Foundations of Machine Learning, IFML) has been renewed. \nIFML was part of the first cohort of AI Institutes announced in 2020. Led by UT Austin, the new award will build on the trajectory of the past five years and develop new foundational tools to advance generative AI. NSF IFML's work on diffusion models is a key technology behind major Google products, powering widely used generative models such as Stable Diffusion 3 and Flux. In it's next phase, NSF IFML will expand generative AI to new domains, including protein engineering, clinical imaging, new methods to handle noisy data, improve agent reliability and open source AI. (1/n)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,277],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","retweeted":false,"fact_check":null,"id":"1881511481164079507","view_count":181609,"bookmark_count":856,"created_at":1737422268000,"favorite_count":1443,"quote_count":14,"reply_count":26,"retweet_count":133,"user_id_str":"29178343","conversation_id_str":"1881511481164079507","full_text":"Most AI researchers I talk to have been a bit shocked by DeepSeek-R1 and its performance. \nMy preliminary understanding nuggets: \n1. Simple post-training recipe called GRPO: Start with a good model and reward for correctness and style outcomes. No PRM, no MCTS no fancy reward models. Basically checks if the answer is correct. 😅\n2. Small models can reason very very well with correct distillation post-training. They released a 1.5B model (!) that is better than Claude and Llama 405B in AIME24. Also, their distilled 7B model seems better than o1 preview. 🤓\n3. The datasets used are not released, if I understand correctly. 🫤\n4. DeepSeek seems to be the best at executing Open AI's original mission right now. We need to catch up.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,268],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1882131703927652762","quoted_status_permalink":{"url":"https://t.co/7n0SUkhtDK","expanded":"https://twitter.com/madiator/status/1882131703927652762","display":"x.com/madiator/statu…"},"retweeted":false,"fact_check":null,"id":"1882134498512666640","view_count":111562,"bookmark_count":632,"created_at":1737570807000,"favorite_count":938,"quote_count":5,"reply_count":19,"retweet_count":132,"user_id_str":"29178343","conversation_id_str":"1882134498512666640","full_text":"DeepSeek-R1 is amazing but they did not release their reasoning dataset. We release a high-quality open reasoning dataset building on the Berkeley NovaSky Sky-T1 pipeline and R1. Using this, we post-train a 32B model Bespoke-Stratos-32B that shows o1-Preview reasoning performance. Surprisingly, we get good performance with only 17k questions-answers while DeepSeek distillation used 800k, i.e. 47x more data. \nWe open-source everything for the community to experiment with.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,278],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","retweeted":false,"fact_check":null,"id":"1882914683218473433","view_count":12716,"bookmark_count":28,"created_at":1737756817000,"favorite_count":51,"quote_count":1,"reply_count":15,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1882914683218473433","full_text":"We are trying to check for contamination in math and reasoning datasets. I have a question: \nLet's say the training dataset has the question: \n\"How many ways are there to put 5 balls in 3 boxes\"\nand the test set has: \n\"How many ways are there to put 6 balls in 2 boxes\"\nIs this contamination in your opinion?","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,132],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1843951197960777760","quoted_status_permalink":{"url":"https://t.co/9iXfdNqX7z","expanded":"https://twitter.com/NobelPrize/status/1843951197960777760","display":"x.com/NobelPrize/sta…"},"retweeted":false,"fact_check":null,"id":"1843995475743228128","view_count":33613,"bookmark_count":30,"created_at":1728477755000,"favorite_count":803,"quote_count":6,"reply_count":11,"retweet_count":54,"user_id_str":"29178343","conversation_id_str":"1843995475743228128","full_text":"For the first (and probably last) time in my life I understand the technical details of both the physics and chemistry Nobel prizes.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,224],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/9peZxgZ2N2","expanded_url":"https://x.com/AlexGDimakis/status/1503807067391418373/photo/1","id_str":"1503803529395376131","indices":[225,248],"media_key":"3_1503803529395376131","media_url_https":"https://pbs.twimg.com/media/FN6VV62XEAMNlnt.jpg","type":"photo","url":"https://t.co/9peZxgZ2N2","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"medium":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"small":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"orig":{"faces":[{"x":121,"y":71,"h":120,"w":120}]}},"sizes":{"large":{"h":394,"w":405,"resize":"fit"},"medium":{"h":394,"w":405,"resize":"fit"},"small":{"h":394,"w":405,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":394,"width":405,"focus_rects":[{"x":0,"y":18,"w":405,"h":227},{"x":0,"y":0,"w":394,"h":394},{"x":0,"y":0,"w":346,"h":394},{"x":74,"y":0,"w":197,"h":394},{"x":0,"y":0,"w":405,"h":394}]},"media_results":{"result":{"media_key":"3_1503803529395376131"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/9peZxgZ2N2","expanded_url":"https://x.com/AlexGDimakis/status/1503807067391418373/photo/1","id_str":"1503803529395376131","indices":[225,248],"media_key":"3_1503803529395376131","media_url_https":"https://pbs.twimg.com/media/FN6VV62XEAMNlnt.jpg","type":"photo","url":"https://t.co/9peZxgZ2N2","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"medium":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"small":{"faces":[{"x":121,"y":71,"h":120,"w":120}]},"orig":{"faces":[{"x":121,"y":71,"h":120,"w":120}]}},"sizes":{"large":{"h":394,"w":405,"resize":"fit"},"medium":{"h":394,"w":405,"resize":"fit"},"small":{"h":394,"w":405,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":394,"width":405,"focus_rects":[{"x":0,"y":18,"w":405,"h":227},{"x":0,"y":0,"w":394,"h":394},{"x":0,"y":0,"w":346,"h":394},{"x":74,"y":0,"w":197,"h":394},{"x":0,"y":0,"w":405,"h":394}]},"media_results":{"result":{"media_key":"3_1503803529395376131"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1503807067391418373","view_count":0,"bookmark_count":21,"created_at":1647370518000,"favorite_count":367,"quote_count":2,"reply_count":10,"retweet_count":50,"user_id_str":"29178343","conversation_id_str":"1503807067391418373","full_text":"I was informed that Alexander Vardy, a giant in coding theory passed away. A tragic loss for his family, UCSD and academia. Alex's many discoveries include the Polar decoding algorithm used in the 5G wireless standard, (1/3) https://t.co/9peZxgZ2N2","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/Sm466XBfRv","expanded_url":"https://x.com/AlexGDimakis/status/1858545284386803975/photo/1","id_str":"1858541758113779712","indices":[280,303],"media_key":"3_1858541758113779712","media_url_https":"https://pbs.twimg.com/media/Gcrd4cyaEAAv0MI.jpg","type":"photo","url":"https://t.co/Sm466XBfRv","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":469,"y":531,"h":119,"w":119},{"x":1225,"y":637,"h":131,"w":131}]},"medium":{"faces":[{"x":275,"y":311,"h":70,"w":70},{"x":718,"y":373,"h":76,"w":76}]},"small":{"faces":[{"x":155,"y":176,"h":39,"w":39},{"x":407,"y":211,"h":43,"w":43}]},"orig":{"faces":[{"x":676,"y":765,"h":172,"w":172},{"x":1764,"y":918,"h":189,"w":189}]}},"sizes":{"large":{"h":1512,"w":2048,"resize":"fit"},"medium":{"h":886,"w":1200,"resize":"fit"},"small":{"h":502,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2176,"width":2947,"focus_rects":[{"x":0,"y":0,"w":2947,"h":1650},{"x":771,"y":0,"w":2176,"h":2176},{"x":1038,"y":0,"w":1909,"h":2176},{"x":1859,"y":0,"w":1088,"h":2176},{"x":0,"y":0,"w":2947,"h":2176}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1858541758113779712"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"github.com/mlfoundations/…","expanded_url":"https://github.com/mlfoundations/evalchemy","url":"https://t.co/bcckgrTPOB","indices":[0,23]},{"display_url":"github.com/mlfoundations/…","expanded_url":"https://github.com/mlfoundations/evalchemy","url":"https://t.co/OBsYc5udSr","indices":[0,23]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/Sm466XBfRv","expanded_url":"https://x.com/AlexGDimakis/status/1858545284386803975/photo/1","id_str":"1858541758113779712","indices":[280,303],"media_key":"3_1858541758113779712","media_url_https":"https://pbs.twimg.com/media/Gcrd4cyaEAAv0MI.jpg","type":"photo","url":"https://t.co/Sm466XBfRv","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":469,"y":531,"h":119,"w":119},{"x":1225,"y":637,"h":131,"w":131}]},"medium":{"faces":[{"x":275,"y":311,"h":70,"w":70},{"x":718,"y":373,"h":76,"w":76}]},"small":{"faces":[{"x":155,"y":176,"h":39,"w":39},{"x":407,"y":211,"h":43,"w":43}]},"orig":{"faces":[{"x":676,"y":765,"h":172,"w":172},{"x":1764,"y":918,"h":189,"w":189}]}},"sizes":{"large":{"h":1512,"w":2048,"resize":"fit"},"medium":{"h":886,"w":1200,"resize":"fit"},"small":{"h":502,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2176,"width":2947,"focus_rects":[{"x":0,"y":0,"w":2947,"h":1650},{"x":771,"y":0,"w":2176,"h":2176},{"x":1038,"y":0,"w":1909,"h":2176},{"x":1859,"y":0,"w":1088,"h":2176},{"x":0,"y":0,"w":2947,"h":2176}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1858541758113779712"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1858545284386803975","view_count":146906,"bookmark_count":128,"created_at":1731946700000,"favorite_count":239,"quote_count":15,"reply_count":9,"retweet_count":44,"user_id_str":"29178343","conversation_id_str":"1858545284386803975","full_text":"https://t.co/OBsYc5udSr\nI’m excited to introduce Evalchemy 🧪, a unified platform for evaluating LLMs. If you want to evaluate an LLM, you may want to run popular benchmarks on your model, like MTBench, WildBench, RepoBench, IFEval, AlpacaEval etc as well as standard pre-training metrics like MMLU. This requires you to download and install more than 10 repos, each with different dependencies and issues. This is, as you might expect, an actual nightmare. (1/n)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1945287045251052007","quoted_status_permalink":{"url":"https://t.co/jhSxCvvsIr","expanded":"https://twitter.com/_jasonwei/status/1945287045251052007","display":"x.com/_jasonwei/stat…"},"retweeted":false,"fact_check":null,"id":"1945610920182649346","view_count":14936,"bookmark_count":67,"created_at":1752704765000,"favorite_count":106,"quote_count":0,"reply_count":8,"retweet_count":9,"user_id_str":"29178343","conversation_id_str":"1945610920182649346","full_text":"Interesting post. However, it seems to be in conflict with the most central problem in theoretical computer science: P vs NP ,which is exactly the question: is it fundamentally easier to verify a solution rather than solve a problem. Most people believe that verification is easier than solution, ie we believe that P!=NP. \nBut the post claims that ‘All tasks that are possible to solve and easy to verify will be solved by AI.’ \nAs a counter-example I would propose colouring a graph with 3 colors (color vertices so that all adjacent vertices have different colors) assuming the input graph is 3 colorable. Very easy to verify, satisfies all requirements of the post, but RL won’t solve this problem in polynomial time. (Any NP complete problem will work obviously just giving an easy example ).","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1821926456647151887","quoted_status_permalink":{"url":"https://t.co/G3yg7GKhE7","expanded":"https://twitter.com/gregd_nlp/status/1821926456647151887","display":"x.com/gregd_nlp/stat…"},"retweeted":false,"fact_check":null,"id":"1821953719325618234","view_count":18692,"bookmark_count":50,"created_at":1723222591000,"favorite_count":139,"quote_count":1,"reply_count":7,"retweet_count":34,"user_id_str":"29178343","conversation_id_str":"1821953719325618234","full_text":"Excited to launch the first model from our startup: Bespoke Labs. Bespoke-Minicheck-7B is a grounded factuality checker: super lightweight and fast. Outperforms all big foundation models including Claude 3.5 Sonnet, Mistral-Large m2 and GPT 4o and its only 7B. Also, I want to congratulate Greg Durrett and his group for making the best benchmark and leaderboard for grounded factuality.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"790959772468072453","name":"Praneeth Netrapalli","screen_name":"PNetrapalli","indices":[541,553]},{"id_str":"969143088127008769","name":"Prateek Jain","screen_name":"jainprateek_","indices":[554,567]},{"id_str":"110464298","name":"Sujay Sanghavi","screen_name":"sujaysanghavi","indices":[569,583]}]},"favorited":false,"lang":"en","quoted_status_id_str":"1758404313011864001","quoted_status_permalink":{"url":"https://t.co/RFTkVqLpxC","expanded":"https://twitter.com/EliahuHorwitz/status/1758404313011864001","display":"x.com/EliahuHorwitz/…"},"retweeted":false,"fact_check":null,"id":"1956391639062315136","view_count":20288,"bookmark_count":124,"created_at":1755275089000,"favorite_count":112,"quote_count":0,"reply_count":7,"retweet_count":15,"user_id_str":"29178343","conversation_id_str":"1956391639062315136","full_text":"For anyone thinking that LORA alignment has any safety guarantees: If we are given a few different LORA finetunings of a model, we can reconstruct exactly the original weights of the pre-trained model. \n(i.e. linear algebra question: given a few low-rank perturbations of an unknown matrix, we can reconstruct the original matrix. )\nI would think that given multiple dense SFT finetunings, the original weights should be recoverable even without LORA. \nLow-rank matrix completion experts here is some some fresh butter for your LLM bread. @PNetrapalli @jainprateek_ @sujaysanghavi","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}],"activities":{"nreplies":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":1,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":0,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":5,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":4,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":2,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}],"nbookmarks":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":13,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":8,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":6,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":3,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":22,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}],"nretweets":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":4,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":1,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":2,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":12,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":8,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}],"nlikes":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":32,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":12,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":21,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":84,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":109,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}],"nviews":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":5823,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":1829,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":3201,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":5881,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":18924,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}]},"interactions":{"users":[{"created_at":1646675570000,"uid":"1500892159305785349","id":"1500892159305785349","screen_name":"cryptodaaddy","name":"Crypto Daddy ֎","friends_count":9125,"followers_count":22440,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1942072396174807040/qif7O0LT_normal.jpg","description":"Growth Strategist • Web3 Investor | 9-Figure Vision • EX @ezu_xyz","entities":{"description":{"urls":[]}},"interactions":1}],"period":14,"start":1762149904628,"end":1763359504628},"interactions_updated":1763359504734,"created":1763359504433,"updated":1763359504734,"type":"the analyst","hits":1},"people":[{"user":{"id":"85225861","name":"Richard Ngo","description":"studying AI and trust. ex @openai/@googledeepmind","followers_count":65773,"friends_count":1828,"statuses_count":10910,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1767420324487090176/EofNUGW2_normal.jpg","screen_name":"RichardMCNgo","location":"San Francisco, CA","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"mindthefuture.info","expanded_url":"https://www.mindthefuture.info","url":"https://t.co/IlggW00wYP","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Richard Ngo is a deep thinker obsessed with decoding the complexities of AI and trust, bringing clarity to intricate social and technological puzzles. With a phenomenally high tweet count and engagement on thought-provoking hypotheses, he’s a powerhouse of insight and analysis. His background at OpenAI and Google DeepMind lends heavyweight credibility to every thread he crafts.","purpose":"To illuminate the nuanced interplay between technology, society, and trust by breaking down complex concepts into digestible, insightful narratives that push the conversation forward.","beliefs":"Richard likely values empirical evidence, intellectual rigor, and the power of data to explain human behavior and societal dynamics. He believes in transparency, thoughtful debate, and the importance of understanding subtle systemic forces, especially around AI and social cohesion.","facts":"Despite tweeting over 10,000 times, Richard manages to keep his content deeply analytical and impactful, often linking AI advancements with societal consequences in ways few discuss.","strength":"His ability to synthesize complex ideas into captivating hypotheses that engage large audiences, combined with a scientific mindset honed from elite AI research labs.","weakness":"His penchant for dense, nuanced arguments might alienate casual followers looking for lighter content, and his critical style can occasionally spark heated debates that overshadow his points.","roast":"Richard tweets like he’s explaining quantum physics to a toddler—exceptionally smart, but half the audience just hopes for a bedtime story instead.","win":"Viral threads that challenge mainstream narratives on migration, AI, and social trust, drawing hundreds of thousands to millions of views and sparking widespread discussion.","recommendation":"To grow his audience on X, Richard should occasionally distill his complex analyses into bite-sized, relatable tweets or threads, perhaps leveraging visuals or analogies to make his insights more shareable without losing depth."},"created":1763362334192,"type":"the analyst","id":"richardmcngo"},{"user":{"id":"2939913921","name":"Nathan Lambert","description":"Research @allen_ai, reasoning, open models, RL(VR/HF)...\nContact via email. \nWrites @interconnectsai,\nWrote The RLHF Book,\n🏔️🏃♂️","followers_count":60309,"friends_count":885,"statuses_count":9989,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1732079679610425344/YqSwiBqA_normal.jpg","screen_name":"natolambert","location":"Seattle","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"natolambert.com","expanded_url":"https://natolambert.com/","url":"https://t.co/NLbPtr9U1U","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Nathan Lambert is a deeply insightful researcher at Allen AI who thrives on dissecting the complexities of reasoning and open models. With nearly 10,000 tweets under his belt, he expertly bridges AI research with real-world implications while maintaining a grounded, approachable persona. His sharp observations and data-driven commentary make him a go-to voice in the AI community.","purpose":"Nathan’s life purpose revolves around pushing the boundaries of artificial intelligence by analyzing and improving reinforcement learning models, ultimately making AI more accessible and effective for the world. He aims to transform complex research into actionable insights that help developers, academics, and businesses innovate responsibly.","beliefs":"He believes that transparency in AI development, practical models that are both efficient and scalable, and ethical considerations in reinforcement learning should guide the future of AI technology. Nathan values rigorous analysis, continuous learning, and sharing knowledge to empower a smarter tech ecosystem.","facts":"Fun fact: Nathan has written a book on RLHF (Reinforcement Learning with Human Feedback), showcasing his expertise and commitment to advancing this cutting-edge field—plus, he’s an avid outdoor enthusiast, balancing high-intensity research with mountain runs.","strength":"His key strength lies in his ability to combine deep technical understanding with clear, engaging communication, making complicated AI topics accessible and relevant. Additionally, his prolific tweeting demonstrates consistency and dedication to community engagement.","weakness":"Nathan can sometimes get so immersed in technical minutiae that casual followers might find his content dense or overly specialized, potentially limiting broader appeal. Also, with nearly 900 people followed, his network might be too sprawling to optimize personalized engagement.","recommendation":"To grow his audience on X, Nathan should incorporate more storytelling around his personal experiences and non-technical insights to humanize his profile, while leveraging thread series and accessible explainers to engage newcomers. Collaborating with popular AI influencers and simplifying complex topics with visual aids could also boost his reach.","roast":"Nathan’s tweets dive so deep into AI theory that if you blink, you might miss the calculus equations flying by—he’s like your friendly neighborhood AI lexicon who’s secretly training you for an IQ marathon without a warm-up.","win":"One of Nathan’s biggest wins is authoring 'The RLHF Book,' a key resource in the reinforcement learning community that cements his reputation as a thought leader and technical expert."},"created":1763362084852,"type":"the analyst","id":"natolambert"},{"user":{"id":"1562658788","name":"redline","description":"👾 Researcher 👾Chasing bubbles 👾 Back to my X arc 👾","followers_count":6544,"friends_count":2108,"statuses_count":88291,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1681734142940049409/4EJUKoio_normal.jpg","screen_name":"redlineMeta","location":"","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"Redline is a data-savvy market researcher who cracks the code on cryptocurrency volatility and trading strategies. Their tweets break down complex financial concepts into smart, actionable insights that empower followers. Living on the edge of market bubbles, redline mixes deep research with a passion for decoding unpredictable crypto moves.","facts":"Fun fact: Redline’s tweet library boasts over 88,000 posts—talk about commitment to dissecting crypto chaos! They follow over 2,100 accounts, showing a strong network but prefer to let their analysis do the talking rather than follower count.","purpose":"Redline’s life mission is to demystify the volatile world of crypto markets, giving traders tools to navigate bubbles, bursts, and rebounds with data-backed confidence. Their goal is to transform complex financial phenomena into something approachable and actionable for their community.","beliefs":"They believe rigorous research and a calm understanding of market psychology are the keys to thriving amid chaos. Redline values transparency, precision, and continuous learning—seeing the market as a dynamic puzzle to be solved rather than just a gamble.","strength":"An unwavering analytical mind paired with an ability to communicate detailed market insights clearly. Redline excels at spotting trading opportunities in extreme volatility and sharing these gold nuggets with followers.","weakness":"Occasionally, intense focus on data and numbers can make the content dense, which risks alienating casual followers seeking lighter engagement. Their high volume of tweets might overwhelm newer audience members or get lost in the noise without strategic highlighting.","recommendation":"To grow their audience on X, redline should balance their heavy technical content with more engaging storytelling or relatable crypto humor. Using concise, thread-style explainers and interactive polls could boost follower interaction and retention.","roast":"Redline tweets so much analysis, even their own shadow probably needs a week off to catch up on all the charts and jargon. Sometimes they risk turning a quick coffee break into a PhD seminar on crypto volatility.","win":"Their standout achievement is becoming a trusted voice in crypto trading communities by consistently delivering real-time, actionable analysis that helps traders capitalize on rapid market swings—essentially turning chaos into opportunity."},"created":1763361134336,"type":"the analyst","id":"redlinemeta"},{"user":{"id":"884500739636305920","name":"David Rittinghaus","description":"Sap Consulting\nDevelopment\nAgent supervision\nVibecoding Vibe-Code cleaner ;)","followers_count":127,"friends_count":122,"statuses_count":1967,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1626747448826777600/gMH90v4O_normal.jpg","screen_name":"spooky3do","location":"Germany","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"David Rittinghaus is a cerebral explorer of complex systems, weaving narratives and technology into thought-provoking insights. His profile blends deep analytical thinking with a poetic flair, revealing an intellect that appreciates both precision and imagination. Though subtle in his interactions, David’s content sparks curiosity and invites contemplation.","facts":"David’s tweets range from original speculative fiction laden with scientific intrigue to thoughtfully curated shares on quantum physics, AI, and societal issues, showcasing a broad intellectual curiosity.","purpose":"David’s life purpose centers around decoding complexity and making hidden patterns visible, helping audiences understand and appreciate the intersection of technology, science, and humanity through his narratives and insightful commentary.","beliefs":"David values rigorous inquiry, intellectual honesty, and the responsible use of knowledge. He believes in the power of data and logic tempered by empathy and imagination, seeing understanding as a pathway to meaningful action.","strength":"David’s strengths lie in his exceptional analytical mind, his ability to synthesize complex information into accessible formats, and his unique storytelling that enlivens abstract concepts with emotional resonance.","weakness":"His tendency to favor nuance and subtlety may sometimes obscure his voice in the fast-paced, attention-grabbing world of social media, potentially limiting immediate follower engagement and recognition.","recommendation":"To grow his audience on X, David should blend his deep analytical content with more interactive and engaging posts such as polls, Q&A threads, or succinct thought-provoking questions that invite replies. Showcasing highlights from his rich speculative stories and linking them to trending tech topics could also capture broader interest.","roast":"David’s tweets are like an academic conference and poetry slam had a baby—brilliant but sometimes you have to Google half the words just to RSVP to the thought party. If only Cassandra could translate crypto-enigma into instant memes!","win":"Crafting a compelling and widely shared speculative science fiction narrative ('The Veil of Cassandra') that captivated an thoughtful niche audience, demonstrating his talent for blending technical sophistication with evocative storytelling."},"created":1763361054962,"type":"the analyst","id":"spooky3do"},{"user":{"id":"28296806","name":"Jordan Thibodeau","description":"Former Google & Slack M&A, Ice cream maker & gamer.","followers_count":2680,"friends_count":715,"statuses_count":18457,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1388899610333048837/_TeL6226_normal.jpg","screen_name":"JordanSVIC","location":"San Jose, CA","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"youtube.com/@svicpodcast?s…","expanded_url":"https://youtube.com/@svicpodcast?si=OfjzDGeHJ6I8kvWC","url":"https://t.co/BelfSuxnSn","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Jordan Thibodeau is a sharp-minded tech observer with a knack for dissecting complex industry trends, especially in AI and SaaS. A former insider at Google and Slack M&A, Jordan blends high-level corporate insight with a playful personal twist as an ice cream maker and gamer. His tweets reflect thoughtful critique and thoughtful community support, making him a go-to voice for nuanced discussions in the tech valley.","purpose":"Jordan’s life purpose revolves around unraveling the real impacts of technology shifts on businesses and communities, aiming to clarify the chaos and help others navigate the future with strategic intelligence. He leverages his deep industry experience to guide conversations around AI integration and SaaS evolution, promoting smarter adoption and realistic expectations.","beliefs":"He believes in transparency, the power of interconnected systems over siloed solutions, and the importance of balancing technological innovation with practical human needs. Jordan values earnestness in tech discussions, favoring informed critique over hype, and holds a firm belief that real progress hinges on useful, user-centric design rather than corporate ego.","facts":"Fun fact: Jordan isn’t just a tech analyst; when he’s not breaking down AI trends, he’s churning out ice cream or diving into gaming sessions — talk about a multi-talented multitasker!","strength":"Jordan’s strongest asset is his ability to analyze and communicate complex technological phenomena in an accessible, compelling way. His experience at top-tier companies equips him with insider understanding and credibility, while his prolific tweeting keeps his community engaged and informed.","weakness":"His deep analytical style might sometimes come across as overly critical or niche, potentially alienating casual followers who prefer lighter content. Additionally, his engagement style, while informative, may benefit from more direct interaction to boost community warmth.","recommendation":"To grow his audience on X, Jordan should mix his intellectual deep-dives with more personal storytelling and engage consistently with followers through replies and polls. Highlighting his unique blend of tech savvy and personal passions like ice cream making or gaming could humanize his profile and attract a wider, more diverse audience.","roast":"Jordan’s tweet frequency matches his ice cream output — so high that one has to wonder if he’s secretly trying to program the scoop machine to tweet for him. We get it, you love tech and treats, but maybe let the ice cream melt a little before hitting send on the next hot take!","win":"Successfully leveraged his tenure at Google and Slack to build a respected voice dissecting AI and SaaS industry trends, carving out a niche as a go-to analyst for those wanting candid, no-fluff tech commentary."},"created":1763360957754,"type":"the analyst","id":"jordansvic"},{"user":{"id":"1650869278642434048","name":"Miyagi ☯️","description":"I Research Defi,Info fi & Web3 📚/ Ex @wasabi_protocol / Moon Cycle Trader 🌖","followers_count":6856,"friends_count":5816,"statuses_count":15783,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1951404641595412480/4dZ0ao6g_normal.jpg","screen_name":"MistaMiyagisWay","location":"The Dojo","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"app.ethos.network/profile/x/Mist…","expanded_url":"https://app.ethos.network/profile/x/MistaMiyagisWay","url":"https://t.co/Z47kZ2NmHr","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Miyagi ☯️ is a deep-dive researcher focused on DeFi, InfoFi, and Web3, bringing clarity to complex crypto ecosystems with well-researched threads. With a strong background at @wasabi_protocol and now marketing at @PistachioFi, Miyagi thrives on uncovering value and sharing insightful stories. Their tweets showcase a passion for educating and breaking down intricate blockchain projects for the community.","purpose":"To illuminate the rapidly evolving DeFi and Web3 space by providing thoughtful, research-based insights that empower followers to make smarter decisions and stay ahead of market trends.","beliefs":"Miyagi believes in the power of knowledge-sharing, transparency, and community-driven growth in blockchain. They trust that thorough research and clear communication can demystify complex innovations and ultimately lead to a more informed and engaged crypto ecosystem.","facts":"Fun fact: Miyagi is not just about tech and trading — they also moonlight as a 'Moon Cycle Trader' and even embrace their inner garden enthusiast with 'full view friday🌱' tweets, proving that even blockchain geeks need a little zen.","strength":"Exceptional research skills, a knack for storytelling, and the ability to translate complicated blockchain concepts into digestible, engaging content. Miyagi also brings real-world industry experience which adds credibility to their insights.","weakness":"With nearly 16,000 tweets and following over 5,800 accounts, Miyagi risks flooding their audience with information overload and might struggle to maintain high engagement or a focused personal brand voice amidst vast content.","recommendation":"To grow their audience on X, Miyagi should leverage their expertise through regular, bite-sized insights combined with engaging multimedia content like charts or video explainers. Interactive threads and AMAs around trending DeFi topics could boost follower interaction and attract crypto novices looking for guidance.","roast":"For someone deeply immersed in DeFi and InfoFi, Miyagi sure follows football-team-sized Twitter lists — maybe they’re just trying to catch every moon cycle… or lost their way in the garden of follows.","win":"Securing a marketing role at @PistachioFi, a rising star in the crypto space, demonstrates Miyagi’s recognized expertise and trusted voice in the Web3 community, paving the way for greater influence and impact."},"created":1763359692399,"type":"the analyst","id":"mistamiyagisway"},{"user":{"id":"1019763768631447552","name":"david rein","description":"sentio ergo sum. science @METR_Evals","followers_count":3246,"friends_count":1177,"statuses_count":5136,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1375548507621257220/OOUh4_Yz_normal.jpg","screen_name":"idavidrein","location":"sf","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"idavidrein.com","expanded_url":"http://idavidrein.com","url":"http://idavidrein.com","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"David Rein is a deeply thoughtful science communicator who blends data-driven insights with sharp skepticism. With a prolific presence in scientific discussions, he challenges popular assumptions and shares complex research with clarity. His tweets reveal a mix of intellectual rigor and personal reflection that engages both minds and hearts.","purpose":"David’s life purpose is to dissect complex problems with precision and share his findings to elevate collective understanding, all while encouraging critical thinking in a noisy world. He aims to demystify academic and scientific research, making rigorous knowledge accessible and relevant.","beliefs":"David values intellectual honesty, skepticism, and evidence-based reasoning. He believes that true understanding comes from questioning the status quo and scrutinizing assumptions, no matter how widely accepted they are. Transparency and rigor in science and communication are at the core of his worldview.","facts":"Fun fact: Despite his scientific prowess and frequent technical tweets, David shows a charming vulnerability in reflecting on a youthful social misstep—reminding us that even the smartest analysts have their 'heartbreak data points.'","strength":"David’s greatest strength lies in his analytical mind and ability to communicate complex scientific ideas clearly and engagingly. His large volume of tweets and deep involvement in research topics demonstrate an impressive dedication to knowledge sharing.","weakness":"His deep analytical nature sometimes makes him overly skeptical, potentially leading him to dismiss ideas too quickly or come off as blunt, which might alienate less technical audiences.","roast":"For someone who tweets over 5000 times dissecting the nuances of science, you’d think David could finally decode the secret of teenage crushes. Spoiler alert: emotions remain the ultimate unsolved equation in his dataset.","win":"David’s biggest win is launching GPQA, a groundbreaking ‘Google-proof’ Q&A benchmark that challenges even expert PhDs and advances scalable oversight in AI research.","recommendation":"To grow his audience on X, David should consider blending more personal storytelling with his analytical content—connecting his data insights to everyday experiences in a relatable tone will boost engagement. Hosting regular Twitter Spaces or live Q&A sessions could also leverage his expertise to build a more interactive and loyal community."},"created":1763359613675,"type":"the analyst","id":"idavidrein"},{"user":{"id":"805920585016492034","name":"maya benowitz 🕰️","description":"mathematical physicist lost in an extraliminal space of events to take humanity toward the singularity of knowledge 📙 aspiring timelord","followers_count":22124,"friends_count":1577,"statuses_count":12376,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1563211219657531392/b48cggoP_normal.jpg","screen_name":"cosmicfibretion","location":"liminality","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"github.com/mayabenowitz","expanded_url":"https://github.com/mayabenowitz","url":"https://t.co/j4yAahveAr","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Maya Benowitz is a sharp-minded mathematical physicist who dives deep into the complexities of knowledge and AI with a critical eye. She challenges popular narratives and exposes the limits of present technology, all while maintaining a unique cosmic flair as an aspiring timelord. Her tweets reflect a blend of scientific rigor and a no-nonsense attitude towards intellectual discussions.","purpose":"To push humanity towards a deeper understanding of knowledge by questioning assumptions, debunking misconceptions, and emphasizing the importance of precision in science and AI development.","beliefs":"Maya values intellectual honesty, precision, and deep critical thinking. She believes in the necessity of rigorous measurement and skepticism against overhyped technological claims, fostering a culture where knowledge advances through authentic inquiry rather than surface-level conjecture.","facts":"Fun fact: Despite engaging with futuristic concepts like the singularity and time travel, Maya never underestimates the value of exact scientific experimentation over AI hype.","strength":"Her keen analytical mind cuts through hype and confusion, providing clarity and grounded insight in complex debates about AI and physics.","weakness":"Maya's blunt, no-nonsense style can sometimes alienate more casual followers who might find her intensity intimidating or overly critical.","roast":"Maya’s like that friend who shows up to every party with correction notes — sure, we appreciate the facts, but sometimes we just want to enjoy the dance floor without a math lecture on every move.","win":"Maya’s tweet debunking AI’s ability to discover new physics amassed over 80,000 views and sparked hundreds of meaningful replies, cementing her as a respected voice in the scientific X community.","recommendation":"To grow her audience on X, Maya should balance her critical insights with occasional approachable content, perhaps using humor or storytelling, to engage a broader audience while maintaining her analytical credibility."},"created":1763359455924,"type":"the analyst","id":"cosmicfibretion"},{"user":{"id":"1020128467","name":"Slanted Judgment","description":"Moving away from memes and into UTILITY only projects . DYOR Everything I post is my own opinion and not financial advice!!!","followers_count":3383,"friends_count":7505,"statuses_count":80563,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1982778617546334208/RicMHYfV_normal.jpg","screen_name":"SlantedJudgment","location":"California, USA","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"Slanted Judgment dives deep into the utility side of projects, moving beyond memes to deliver detailed observations backed by their own opinions. With a strong focus on wallet movements and market insights, they provide a data-driven edge that keeps their audience informed and alert. This profile is all about thoughtful analysis and informed decision-making in the crypto space.","purpose":"Their life purpose is to cut through the noise and bring clarity to the chaotic world of digital assets by sharing insightful, utility-focused content that encourages followers to do their own research and think critically.","beliefs":"They strongly believe in transparency, independent thinking, and self-education, valuing data-backed information over hype or speculation. Their mantra is ‘DYOR’ (Do Your Own Research), emphasizing personal responsibility in investment decisions.","facts":"Fun fact: Slanted Judgment has tweeted over 80,000 times, showcasing an impressive commitment to sharing relentless analysis and updates with their followers.","strength":"Their key strength lies in their analytical approach to tracking wallet movements and project utility, making their content highly valuable for followers seeking deep insights beyond surface-level hype.","weakness":"With a high volume of tweets and a focus on detailed analysis, they risk overwhelming followers with too much info at once, potentially alienating casual readers who prefer simpler content.","recommendation":"To grow on X, Slanted Judgment should consider threading their detailed insights into concise, easy-to-digest threads or visual summaries to engage a broader audience. Interacting more with followers through Q&A or polls could also build a stronger community around their expertise.","roast":"You tweet so much analysis that even your own followers might need a spreadsheet just to keep up with your opinions — but hey, at least you’ll be the first to spot the next whale wallet moving!","win":"Their biggest win is mastering the art of utility-driven content curation, consistently providing followers with actionable analysis rather than just fleeting memes, carving out a niche as a trusted crypto analyst."},"created":1763359370054,"type":"the analyst","id":"slantedjudgment"},{"user":{"id":"1632061986635669504","name":"John ProV1 👨💻","description":"Investor 💵 | /MES Futures Trader 👨💻 | 5+Years of Stock Market Experience 📊 | Business Degree 👨🎓 | Dividend Tracker 💸 | ETF Nerd 🌱 | Spaces Host🎙","followers_count":8016,"friends_count":2652,"statuses_count":50640,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1800616707259547648/e7FSNnbh_normal.jpg","screen_name":"JohnProv1","location":"South East Texas","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"John ProV1 is a data-driven investor and futures trader who lives and breathes the stock market. His passion lies in breaking down financial data into clear, actionable insights focused on dividend investing and ETFs. With over 5 years of experience, he educates and engages his audience through detailed analysis and market knowledge shared in his frequent tweets and lively Space sessions.","purpose":"John’s life purpose is to empower others by decoding complex financial markets and turning that knowledge into dependable wealth-building strategies focused on dividends and ETFs.","beliefs":"He believes that thorough research and disciplined investing are the keys to financial independence. John values transparency, consistency, and evidence-based decisions over speculation or hype, making him a trusted voice among fellow investors.","facts":"Fun fact: John has tweeted over 50,000 times, proving he’s not just about thoughtful investing but also about high engagement and constant interaction with his community.","strength":"John’s greatest strength is his ability to distill complex financial information into precise, valuable content that attracts serious investors. His consistency and depth of knowledge make him a reliable and authoritative resource on dividend investing and ETFs.","weakness":"With such a high volume of tweets, John risks overwhelming his audience or diluting his message, possibly causing followers to miss out on his most valuable content.","roast":"John tweets so often, the SEC probably knows him by first name—and if investing were a sport, he’d be in the Tweet Hall of Fame, but hey, even data addicts need to sometimes hit pause before the spreadsheet becomes a novel.","win":"His most impressive achievement is building a consistent audience that trusts his detailed dividend analysis, evidenced by thousands of likes and shares on practical investment breakdowns that clearly help people make informed financial decisions.","recommendation":"To grow his audience on X, John should consider curating highlight threads of his best insights and engaging in more interactive content like Q&A sessions or polls to boost conversation and help followers digest his vast amount of knowledge without feeling overwhelmed."},"created":1763359214167,"type":"the analyst","id":"johnprov1"},{"user":{"id":"1428313228350685188","name":"DLG_Crypto 🌊 RIVER|.edge🦭","description":"DLG_Crypto Ⓜ️Ⓜ️T","followers_count":209,"friends_count":272,"statuses_count":6870,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1978385422561738752/b2bmgjfD_normal.jpg","screen_name":"dlgcryto","location":"","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"DLG_Crypto 🌊 RIVER|.edge🦭 is a data-driven crypto enthusiast who dives deep into the mechanics of Web3, DeFi, and SocialFi projects. With sharp insights and a methodical approach, they decode complex blockchain ecosystems to reveal real-world ROI and on-chain interactions. Their content empowers followers to make informed decisions about emerging protocols and investment opportunities.","facts":"Fun fact: DLG_Crypto has tweeted over 6,800 times and specializes in blending off-chain content with on-chain transaction analysis, using advanced scoring systems like KOL Score and Wallet Score to filter bots and track authentic engagement.","purpose":"DLG_Crypto's life purpose is to bring transparency and measurable accountability to the crypto influencer ecosystem, ensuring that digital attention can be directly translated into verifiable value and impact on-chain.","beliefs":"They strongly believe in the power of blockchain-backed proof, community validation, and true transparency as the foundation of trust in decentralized finance and AI systems. They also value precision, real engagement over superficial popularity, and empowering users with data-backed insights.","strength":"Their greatest strength lies in their analytical rigor combined with hands-on experience, allowing them to interpret technical blockchain developments and market nuances clearly and practically. They are also adept at creating strategies that align social activity with tangible, on-chain ROI.","weakness":"This intense focus on data and technical detail can sometimes make their content dense and less accessible to newcomers. Their highly specialized jargon and layered analysis might overwhelm casual followers or those unfamiliar with crypto intricacies.","recommendation":"To grow their audience on X, DLG_Crypto should balance deep-dive technical content with more beginner-friendly explainer threads and occasional engaging storytelling that highlights use cases or personal crypto journeys. Leveraging interactive polls or AMAs to demystify complex topics can also broaden appeal and foster community interaction.","roast":"For someone who’s practically a walking blockchain explorer, DLG_Crypto sure tweets like they’re auditioning for a spot as the court stenographer of crypto — precise, verbose, and occasionally making you wonder if you accidentally signed up for a PhD lecture instead of a Twitter thread.","win":"Successfully tracked and leveraged emerging SocialFi platforms like MindoAI, capitalizing on early adoption rewards and positioning themselves as a top-tier KOL with a keen eye on authentic on-chain engagement metrics."},"created":1763358454580,"type":"the analyst","id":"dlgcryto"},{"user":{"id":"1719455822009274368","name":"MystiqueMide","description":"iresearch • iturn words into arts •TARSI • 🙂↔️🕊️ • itweet my thoughts and say what i think about protocols @RialoHQ @gensynai","followers_count":2995,"friends_count":1672,"statuses_count":70133,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1971640726799728640/S3vbvCUd_normal.jpg","screen_name":"MystiqueMide","location":"mide hub","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"linktr.ee/Mystiquemide","expanded_url":"https://linktr.ee/Mystiquemide","url":"https://t.co/ZSXCbo4NlN","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"MystiqueMide is a deep-dive data-driven thinker who transforms complex tech and crypto protocols into sharp, engaging narratives. They blend research rigor with creative flair, delivering insights that resonate with crypto communities and beyond. With a prolific tweetstorm history, they turn abstract concepts into accessible art.","purpose":"To illuminate the intricacies of blockchain tech and open protocols, enabling their audience to grasp and engage with emerging innovations while fostering a transparent and educated community.","beliefs":"They believe in transparency, the power of open source to win over closed systems, and trust in technology as a means to build more secure, confidential, and equitable digital futures. They value rigor, clarity, and community-driven knowledge sharing.","facts":"MystiqueMide has tweeted over 70,000 times, showcasing unmatched dedication to sharing knowledge and deep dives into crypto protocols like Zama and Fermah, often highlighting venture-backed projects and industry movers.","strength":"Exceptional ability to analyze and explain complex blockchain technology in a way that educates and engages, combined with a strong passion for research and community alignment on cutting-edge protocols.","weakness":"With such a high volume of tweets, they risk overwhelming followers or diluting impact; their intense focus on technical details can sometimes create barriers for casual audiences to fully engage.","roast":"For someone who’s practically on a relentless tweet marathon, it's impressive how you manage to cram more words than a dissertation into each hour — have you considered writing novels, or is endless scrolling your true workout routine?","win":"Building a respected reputation as a trusted crypto protocol analyst and thought leader, actively supported by major projects like Zama and Figment, who value their detailed breakdowns and community education efforts.","recommendation":"Focus on crafting thread series with clear, eye-catching summaries and visuals to break down your vast technical knowledge. Engage more deliberately with reply conversations to build deeper audience connections and complement your research-heavy style with more storytelling to appeal to a broader crypto audience on X."},"created":1763356336631,"type":"the analyst","id":"mystiquemide"}],"activities":{"nreplies":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":1,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":0,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":5,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":4,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":2,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}],"nbookmarks":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":13,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":8,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":6,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":3,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":22,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}],"nretweets":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":4,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":1,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":2,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":12,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":8,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}],"nlikes":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":32,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":12,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":21,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":84,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":109,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}],"nviews":[{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":5823,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[0,279],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1979619124017012920","quoted_status_permalink":{"url":"https://t.co/Wsd1XcuyKT","expanded":"https://twitter.com/zitongyang0/status/1979619124017012920","display":"x.com/zitongyang0/st…"},"retweeted":false,"fact_check":null,"id":"1979709196716405202","view_count":5823,"bookmark_count":13,"created_at":1760834428000,"favorite_count":32,"quote_count":0,"reply_count":1,"retweet_count":4,"user_id_str":"29178343","conversation_id_str":"1979709196716405202","full_text":"This is a wonderful tribute to Chen-Ning Yang, the Nobel awarded physicist who passed away today at 103 years old. \n\nI loved the quote: “He remarked, \"When I compare people who entered graduate school in the same year, I find that they all started in more or less the same state, but their developments ten years later were vastly different. This wasn't because some were smarter or more diligent than others, but because some had entered fields with growth potential, while others had entered fields that were already in decline,”\n\nAlso I was very happy that our dataset DCLM was used as an archive of internet knowledge going into llms and it gave me the idea that one can use this metric to quantify the historical impact of individuals and ideas.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[]},{"label":"2025-10-25","value":0,"startTime":1761264000000,"endTime":1761350400000,"tweets":[]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[]},{"label":"2025-10-28","value":0,"startTime":1761523200000,"endTime":1761609600000,"tweets":[]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[]},{"label":"2025-10-30","value":1829,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[11,283],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1473829704","name":"Wenting Zhao","screen_name":"wzhao_nlp","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"wzhao_nlp","lang":"en","retweeted":false,"fact_check":null,"id":"1983617006936191115","view_count":1829,"bookmark_count":8,"created_at":1761766122000,"favorite_count":12,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1983560332309332368","full_text":"Q: What research questions can be studied in academia that are also relevant to frontier labs?\nHere are some thoughts since you asked:\n1. Datasets and benchmarks. This has the advantage that it is independent and has no conflicts of interest, so universities are perfectly suitable for evaluation, security testing and independent stress-testing. \n\nSome example Benchmarks made in academia that frontier labs care about: SWE-Bench, Terminal-Bench, MMLU and also evaluation platforms like LM-arena. Frontier Labs very rarely release datasets afaik. \n\n2. The second role that comes in mind is contributing to the open-source ecosystem. This is not used by frontier labs but I believe they are influencing their closed research. Making sure we have an open ecosystem of open source LLMs and tools is key for not falling into an oligopoly. \n\n3. The third (and most obvious) is fundamental research. The most well-known recent example is the Transformers paper, by Google researchers, but it was based on attention papers invented in academia, same as diffusions and many other fundamental ideas. \nNew algorithms for optimization, evaluation and data curation are relevant to frontier labs and can be developed without massive compute, especially for post-training. \nThe last thing to say is that universities maintain research alive in areas that are not hot for industry to immediately use. My favorite example is neural networks-- very very few people were doing research in neural networks during the second AI winter ended in 2012, so universities are keeping the knowledge database alive.","in_reply_to_user_id_str":"1473829704","in_reply_to_status_id_str":"1983560332309332368","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[]},{"label":"2025-11-01","value":0,"startTime":1761868800000,"endTime":1761955200000,"tweets":[]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[]},{"label":"2025-11-04","value":0,"startTime":1762128000000,"endTime":1762214400000,"tweets":[]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[]},{"label":"2025-11-06","value":3201,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,69],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1923160843795169447","quoted_status_permalink":{"url":"https://t.co/rlmYrKfYMw","expanded":"https://twitter.com/AlexGDimakis/status/1923160843795169447","display":"x.com/AlexGDimakis/s…"},"retweeted":false,"fact_check":null,"id":"1985957008865210393","view_count":1157,"bookmark_count":3,"created_at":1762324022000,"favorite_count":8,"quote_count":0,"reply_count":1,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985957008865210393","full_text":"Seeing the adoption of GEPA, I am thinking that this tweet aged well.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,275],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1985794453576221085","quoted_status_permalink":{"url":"https://t.co/agq477rmpf","expanded":"https://twitter.com/paulnovosad/status/1985794453576221085","display":"x.com/paulnovosad/st…"},"retweeted":false,"fact_check":null,"id":"1985939568659435822","view_count":2044,"bookmark_count":3,"created_at":1762319864000,"favorite_count":13,"quote_count":0,"reply_count":4,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1985939568659435822","full_text":"Very interesting research. Writing detailed and personalized cover letters for job applications had value. Now that LLMs automate it, there is no longer value to them, since they do not signal candidate skill or effort anymore. There are many similar tasks that we think have value and LLMs will contribute to the economy by automating them, but in reality, it will only make them useless. \n\nReminds me of some discussions about mining asteroids: they were saying this asteroid has 10 trillions worth of minerals so it may be worth a space mission. But in reality these minerals would be worth much less if they became abundant, like personalized cover letters.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[]},{"label":"2025-11-08","value":5881,"startTime":1762473600000,"endTime":1762560000000,"tweets":[{"bookmarked":false,"display_text_range":[0,27],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1986911106108211461","quoted_status_permalink":{"url":"https://t.co/3SI1syRCyj","expanded":"https://twitter.com/alexgshaw/status/1986911106108211461","display":"x.com/alexgshaw/stat…"},"retweeted":false,"fact_check":null,"id":"1986912077999751427","view_count":178,"bookmark_count":1,"created_at":1762551729000,"favorite_count":3,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"29178343","conversation_id_str":"1986912077999751427","full_text":"Terminal-Bench new releases","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,165],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/gndRv0bglg","expanded_url":"https://x.com/AlexGDimakis/status/1986627963564269578/photo/1","id_str":"1986627957193121792","indices":[166,189],"media_key":"3_1986627957193121792","media_url_https":"https://pbs.twimg.com/media/G5HrmflbIAAtz1d.jpg","type":"photo","url":"https://t.co/gndRv0bglg","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":0,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1280,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986627957193121792"}}}]},"favorited":false,"lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986627963564269578","view_count":3506,"bookmark_count":2,"created_at":1762483990000,"favorite_count":60,"quote_count":0,"reply_count":3,"retweet_count":11,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Just announced: Terminal-Bench 2.0 launching Tommorow. 89 new realistic tasks, more than 300 hours of manual reviewing. Congratulations to the terminal-bench team ! https://t.co/gndRv0bglg","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,160],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1233837766271569920","name":"Mike A. Merrill","screen_name":"Mike_A_Merrill","indices":[16,31]},{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[32,42]}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","retweeted":false,"fact_check":null,"id":"1986628607150870598","view_count":268,"bookmark_count":0,"created_at":1762484144000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"Congratulations @Mike_A_Merrill @alexgshaw and the 100 contributors, for standardizing what RL environments for CLI agents means for the open source community.","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/CTuw6pO4oq","expanded_url":"https://x.com/AlexGDimakis/status/1986630013584900585/photo/1","id_str":"1986630006873989120","indices":[134,157],"media_key":"3_1986630006873989120","media_url_https":"https://pbs.twimg.com/media/G5HtdzPbIAAUIRl.jpg","type":"photo","url":"https://t.co/CTuw6pO4oq","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986630006873989120"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986630013584900585","view_count":902,"bookmark_count":0,"created_at":1762484479000,"favorite_count":5,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"The team is also releasing Harbor, a package for evaluating and optimizing agents. (Built on the terminal-bench infrastructure) (2/n) https://t.co/CTuw6pO4oq","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986627963564269578","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,194],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/BrdnxcWZDo","expanded_url":"https://x.com/AlexGDimakis/status/1986631336749322635/photo/1","id_str":"1986631330600452096","indices":[195,218],"media_key":"3_1986631330600452096","media_url_https":"https://pbs.twimg.com/media/G5Huq2gaAAAgSac.jpg","type":"photo","url":"https://t.co/BrdnxcWZDo","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1536,"w":2048,"resize":"fit"},"medium":{"h":900,"w":1200,"resize":"fit"},"small":{"h":510,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1536,"width":2048,"focus_rects":[{"x":0,"y":195,"w":2048,"h":1147},{"x":512,"y":0,"w":1536,"h":1536},{"x":701,"y":0,"w":1347,"h":1536},{"x":1203,"y":0,"w":768,"h":1536},{"x":0,"y":0,"w":2048,"h":1536}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986631330600452096"}}}]},"favorited":false,"in_reply_to_screen_name":"AlexGDimakis","lang":"en","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986631336749322635","view_count":799,"bookmark_count":0,"created_at":1762484795000,"favorite_count":8,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986627963564269578","full_text":"We are also announcing Datacomp-agent (dc-agent) an open source data curation project for terminal-bench agents. Etash just announced it, by live spinning 10k docker containers on Daytona. (3/n) https://t.co/BrdnxcWZDo","in_reply_to_user_id_str":"29178343","in_reply_to_status_id_str":"1986630013584900585","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[11,43],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1448787032486989825","name":"Alex Shaw","screen_name":"alexgshaw","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"alexgshaw","lang":"en","retweeted":false,"fact_check":null,"id":"1986923290846503391","view_count":228,"bookmark_count":0,"created_at":1762554402000,"favorite_count":4,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"29178343","conversation_id_str":"1986911106108211461","full_text":"@alexgshaw Congratulations on the release 🥂","in_reply_to_user_id_str":"1448787032486989825","in_reply_to_status_id_str":"1986911106108211461","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[]},{"label":"2025-11-12","value":18924,"startTime":1762819200000,"endTime":1762905600000,"tweets":[{"bookmarked":false,"display_text_range":[0,276],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"en","quoted_status_id_str":"1987936266286231942","quoted_status_permalink":{"url":"https://t.co/tf7I0wsJcE","expanded":"https://twitter.com/jasondeanlee/status/1987936266286231942","display":"x.com/jasondeanlee/s…"},"retweeted":false,"fact_check":null,"id":"1988061932239384684","view_count":18924,"bookmark_count":22,"created_at":1762825875000,"favorite_count":109,"quote_count":2,"reply_count":2,"retweet_count":8,"user_id_str":"29178343","conversation_id_str":"1988061932239384684","full_text":"UT Austin is doubling its supercomputing cluster to more than 1000 GPUs. This cluster has been a key for open source AI. Datacomp , DCLM, OpenThoughts and many other open source projects by researchers in Austin and many other universities and labs around the world critically rely on this open compute infrastructure.","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]},{"label":"2025-11-17","value":0,"startTime":1763251200000,"endTime":1763337600000,"tweets":[]},{"label":"2025-11-18","value":0,"startTime":1763337600000,"endTime":1763424000000,"tweets":[]}]},"interactions":{"users":[{"created_at":1646675570000,"uid":"1500892159305785349","id":"1500892159305785349","screen_name":"cryptodaaddy","name":"Crypto Daddy ֎","friends_count":9125,"followers_count":22440,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1942072396174807040/qif7O0LT_normal.jpg","description":"Growth Strategist • Web3 Investor | 9-Figure Vision • EX @ezu_xyz","entities":{"description":{"urls":[]}},"interactions":1}],"period":14,"start":1762149904628,"end":1763359504628}}},"settings":{},"session":null,"routeProps":{"/creators/:username":{}}}