0xMomo🕊️ | MemeMax⚡️ is a detail-oriented tech enthusiast and DeFi arbitrage explorer, who dives deep into on-chain data with a scholar's rigor. Their journey is marked by sharing intricate trading path algorithms and contract optimizations with a touch of humility and community spirit. They resist superficial growth hacks, focusing instead on genuine learning and meaningful contributions.
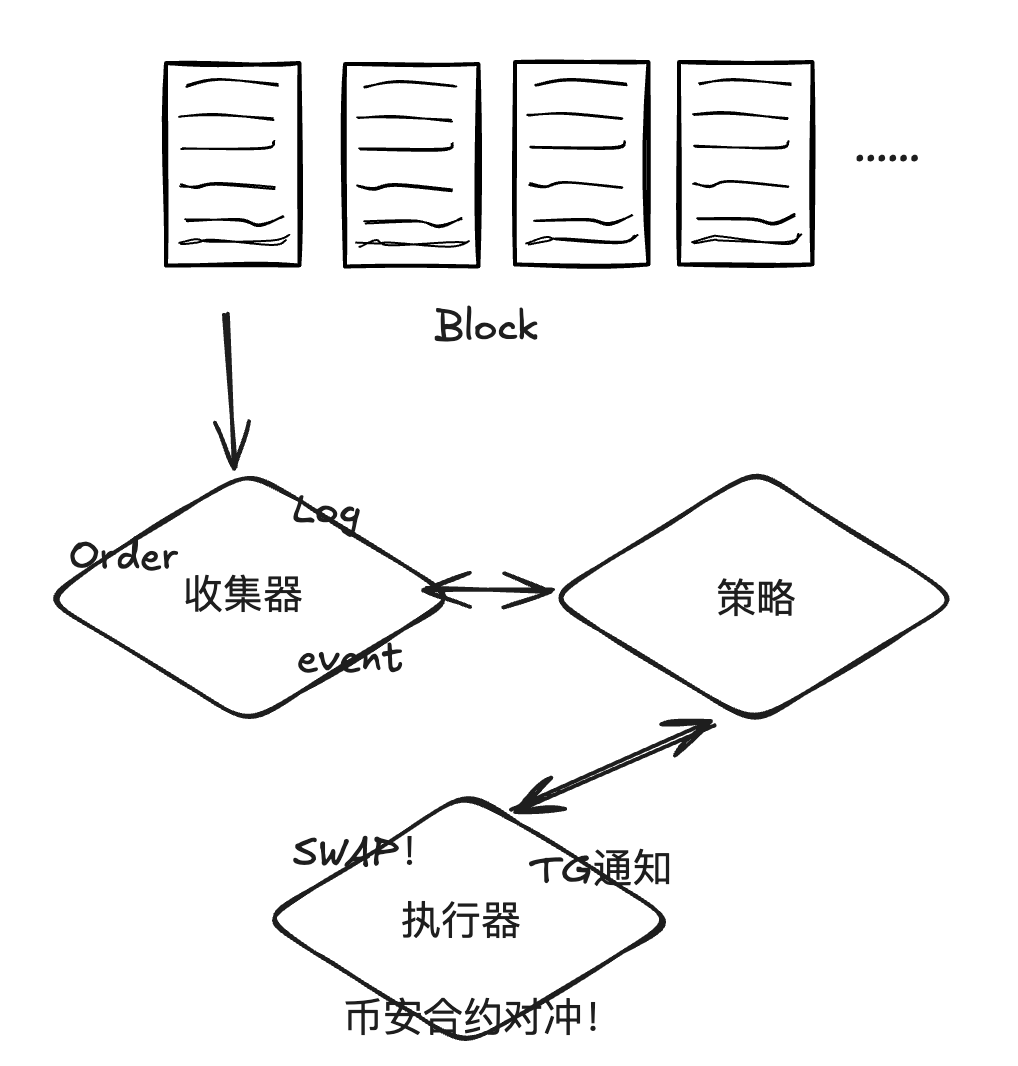
For someone obsessed with arbitrage optimizations and swap path graphs, 0xMomo probably dreams in DFS and BFS algorithms—just don't ask them to explain their weekend plans without a flowchart handy!
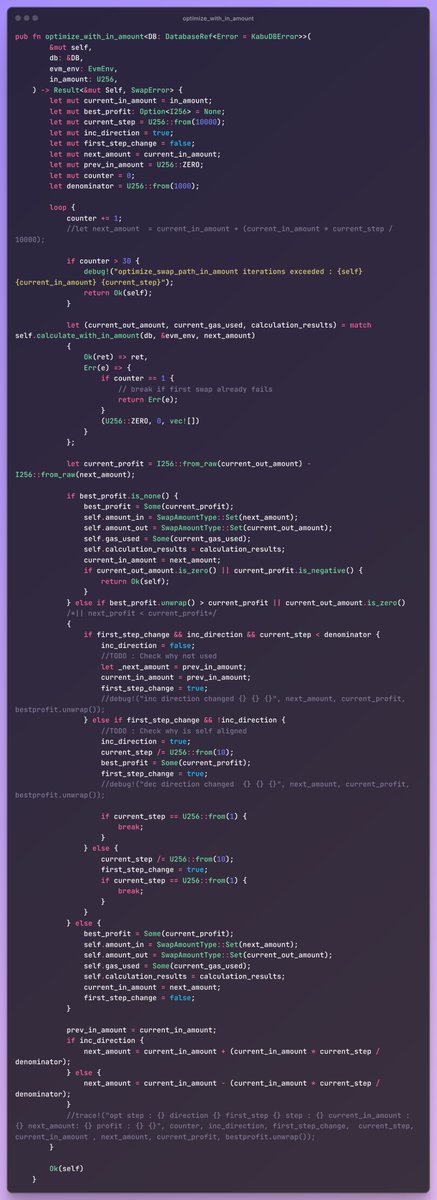
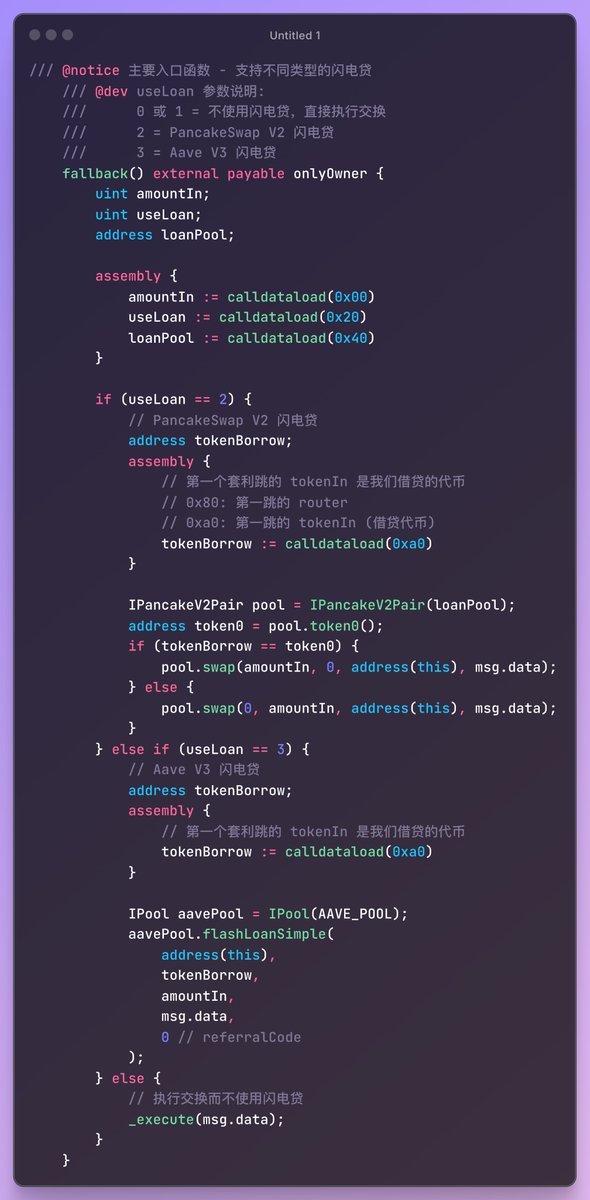
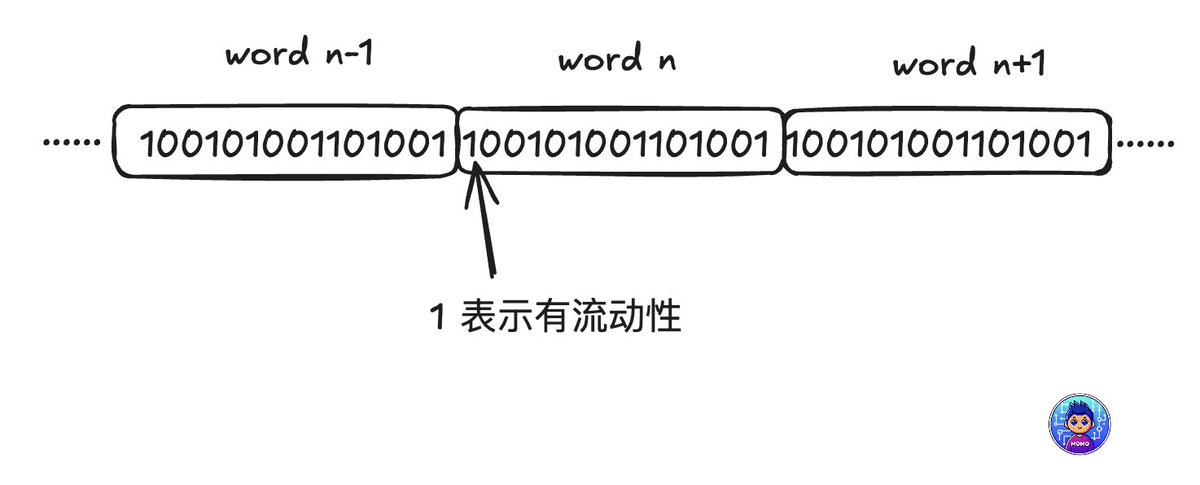
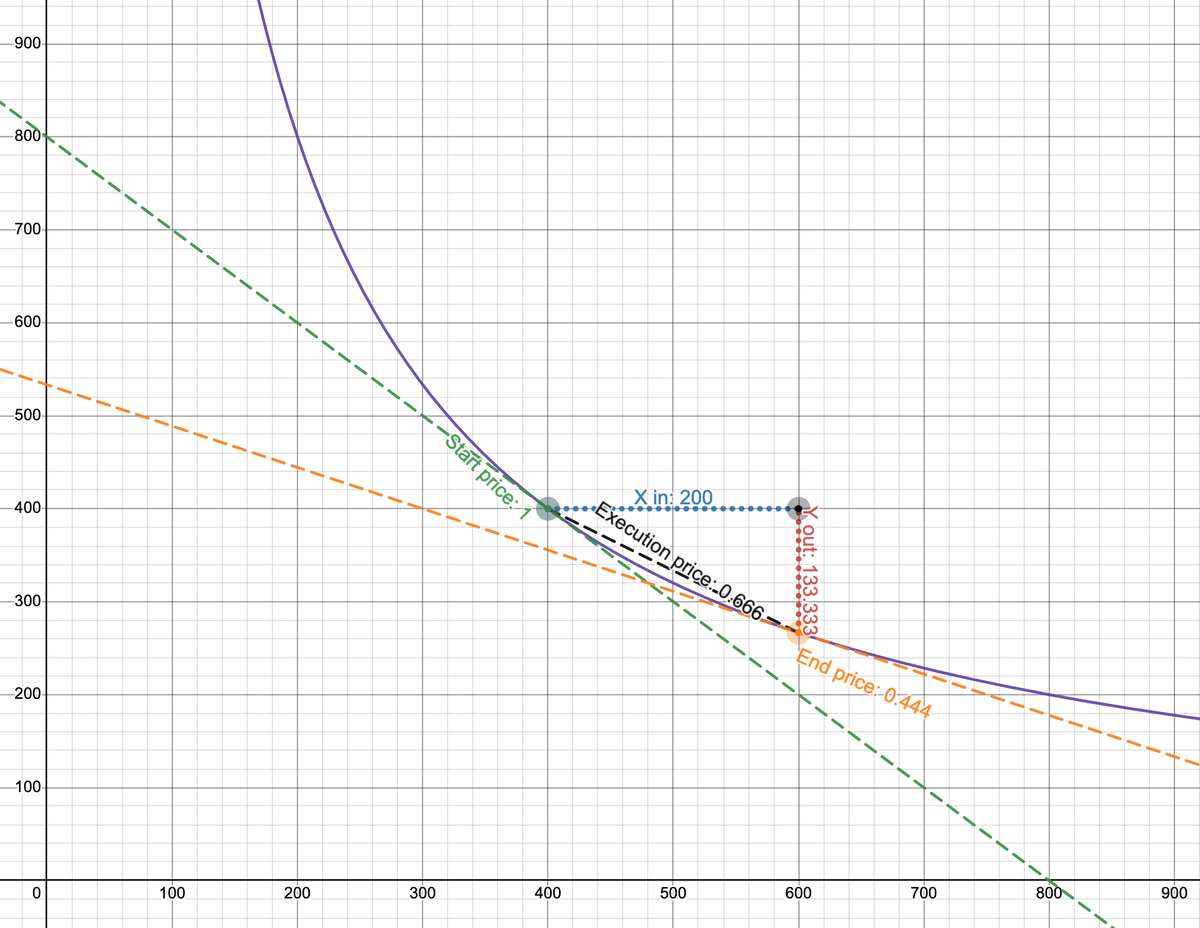
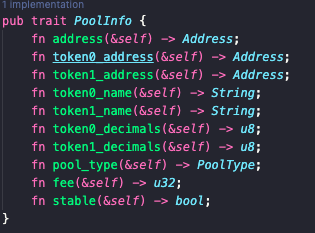
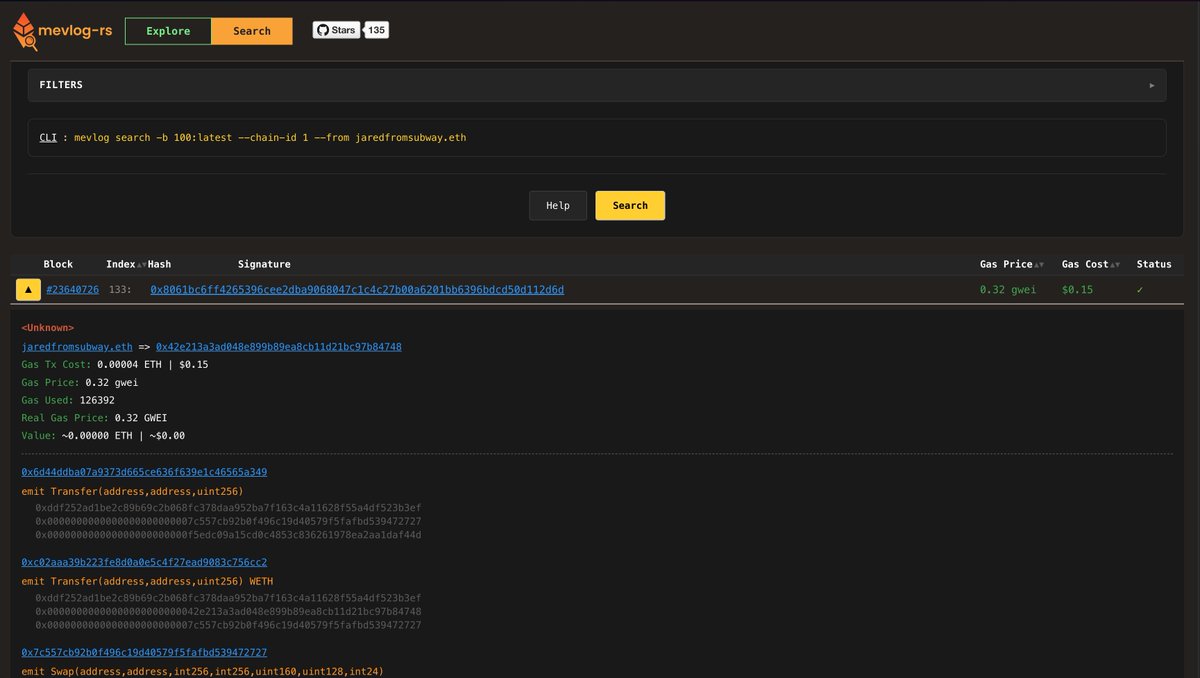
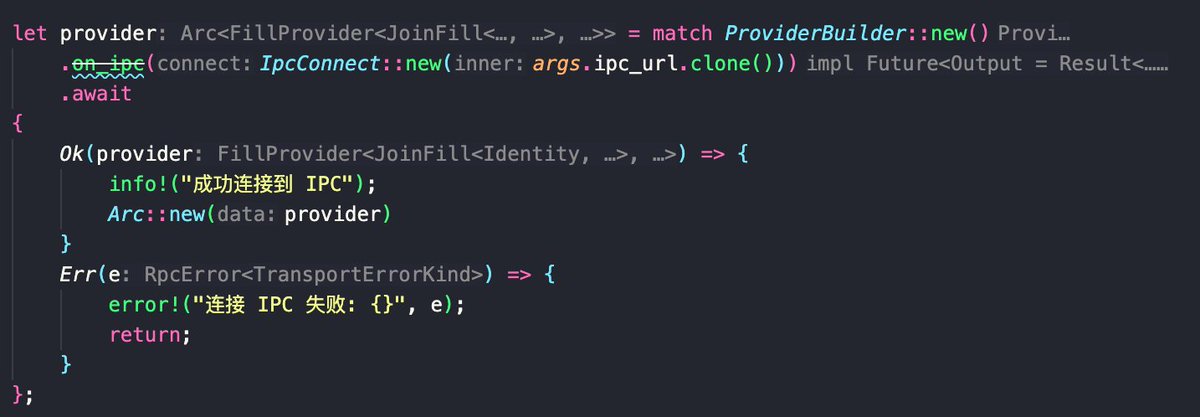
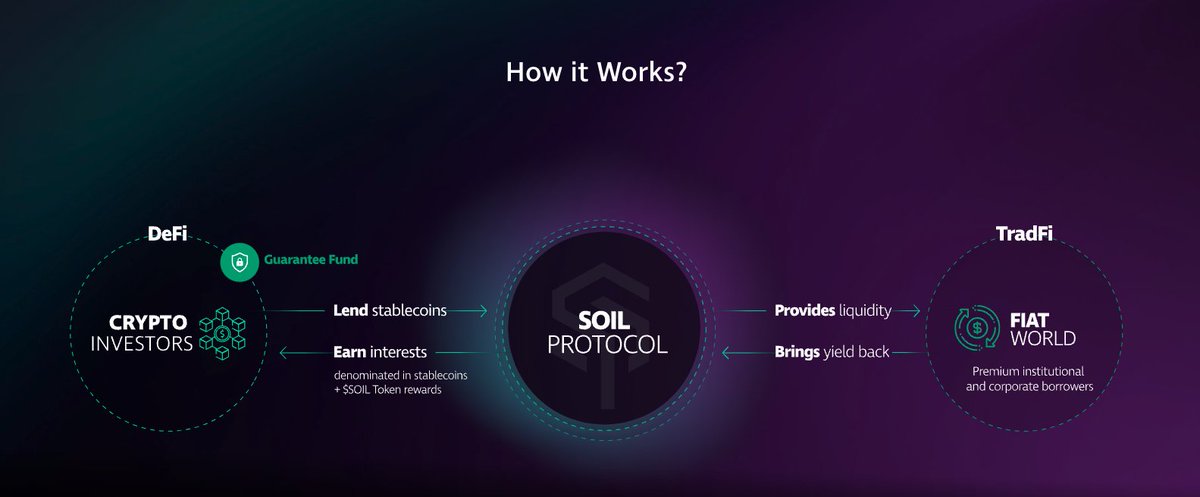
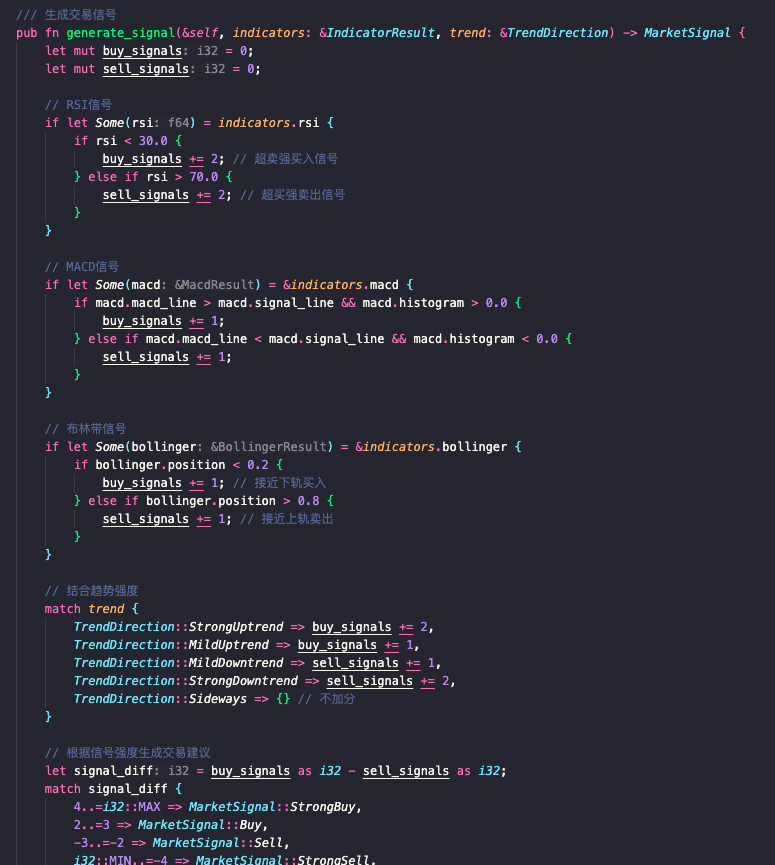
A major win is their influential arbitrage learning notes series, which not only showcases their mastery of complex DeFi concepts like multi-hop swaps and on-chain contract optimizations but also earned respect and followership within crypto technical circles.
Their life purpose revolves around mastering and demystifying blockchain arbitrage mechanics to empower others in the crypto space, essentially becoming a trusted navigational beacon within decentralized finance seas.
They believe in transparent knowledge-sharing, technical diligence, and community-driven learning over hype and shortcuts. They value honest effort ('勤奋、真诚、用心') and the integrity of on-chain data as the foundation for all trading success.
0xMomo's key strengths include deep technical expertise in DeFi protocols, exceptional analytical skills in pathfinding algorithms, and a consistent commitment to detailed documentation that educates and uplifts peers.
The overemphasis on technical depth might alienate casual followers or newcomers who prefer simpler, more engaging content. Also, their high standards for authenticity could slow down audience growth in a platform often favoring sensationalism.
To grow their audience on X, 0xMomo should blend their technical deep-dives with interactive, bite-sized explainers or visual threads that invite engagement from broader crypto enthusiasts. Hosting Q&A sessions or collaborating with influencers could humanize the technical lens and build a loyal community faster.
Fun fact: Despite being a '技术宅男' (tech geek), 0xMomo keeps it real by strictly avoiding follower inflation ('坚持不刷粉'), showing that authenticity beats vanity metrics every time.
{"data":{"__meta":{"device":false,"path":"/creators/0xmomonifty"},"/creators/0xmomonifty":{"data":{"user":{"id":"1744901065886318592","name":"0xMomo🕊️ | MemeMax⚡️","description":"| 职业 - 技术宅男 | 爱好 - 投研撸毛 | 梦想 - 链上小将 | 坚持不刷粉 | 勤奋、真诚、用心 | #蓝鸟会 |\n\n全链扫链打狗就用UX - https://t.co/LltO9E4VY7\n宇宙币安返佣点这个 - https://t.co/qbAI5Sglb7","followers_count":3787,"friends_count":1620,"statuses_count":5020,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1987713432142090240/nVrpjUqv_normal.jpg","screen_name":"0xmomonifty","location":"区块打包中...","entities":{"description":{"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/LltO9E4VY7","indices":[78,101]},{"display_url":"0xmomo.com/bn","expanded_url":"http://0xmomo.com/bn","url":"https://t.co/qbAI5Sglb7","indices":[114,137]}]}}},"details":{"type":"The Analyst","description":"0xMomo🕊️ | MemeMax⚡️ is a detail-oriented tech enthusiast and DeFi arbitrage explorer, who dives deep into on-chain data with a scholar's rigor. Their journey is marked by sharing intricate trading path algorithms and contract optimizations with a touch of humility and community spirit. They resist superficial growth hacks, focusing instead on genuine learning and meaningful contributions.","facts":"Fun fact: Despite being a '技术宅男' (tech geek), 0xMomo keeps it real by strictly avoiding follower inflation ('坚持不刷粉'), showing that authenticity beats vanity metrics every time.","purpose":"Their life purpose revolves around mastering and demystifying blockchain arbitrage mechanics to empower others in the crypto space, essentially becoming a trusted navigational beacon within decentralized finance seas.","beliefs":"They believe in transparent knowledge-sharing, technical diligence, and community-driven learning over hype and shortcuts. They value honest effort ('勤奋、真诚、用心') and the integrity of on-chain data as the foundation for all trading success.","strength":"0xMomo's key strengths include deep technical expertise in DeFi protocols, exceptional analytical skills in pathfinding algorithms, and a consistent commitment to detailed documentation that educates and uplifts peers.","weakness":"The overemphasis on technical depth might alienate casual followers or newcomers who prefer simpler, more engaging content. Also, their high standards for authenticity could slow down audience growth in a platform often favoring sensationalism.","recommendation":"To grow their audience on X, 0xMomo should blend their technical deep-dives with interactive, bite-sized explainers or visual threads that invite engagement from broader crypto enthusiasts. Hosting Q&A sessions or collaborating with influencers could humanize the technical lens and build a loyal community faster.","roast":"For someone obsessed with arbitrage optimizations and swap path graphs, 0xMomo probably dreams in DFS and BFS algorithms—just don't ask them to explain their weekend plans without a flowchart handy!","win":"A major win is their influential arbitrage learning notes series, which not only showcases their mastery of complex DeFi concepts like multi-hop swaps and on-chain contract optimizations but also earned respect and followership within crypto technical circles."},"tweets":[{"bookmarked":false,"display_text_range":[0,166],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/Bod4ky2vfY","expanded_url":"https://x.com/0xmomonifty/status/1949292154767237250/photo/1","id_str":"1949125229508526080","indices":[167,190],"media_key":"3_1949125229508526080","media_url_https":"https://pbs.twimg.com/media/GwyvEb-bgAA6Xg6.jpg","type":"photo","url":"https://t.co/Bod4ky2vfY","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1207,"resize":"fit"},"medium":{"h":1200,"w":707,"resize":"fit"},"small":{"h":680,"w":401,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2414,"focus_rects":[{"x":0,"y":652,"w":2414,"h":1352},{"x":0,"y":121,"w":2414,"h":2414},{"x":0,"y":0,"w":2414,"h":2752},{"x":304,"y":0,"w":2048,"h":4096},{"x":0,"y":0,"w":2414,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1949125229508526080"}}},{"display_url":"pic.x.com/Bod4ky2vfY","expanded_url":"https://x.com/0xmomonifty/status/1949292154767237250/photo/1","id_str":"1949125391496720384","indices":[167,190],"media_key":"3_1949125391496720384","media_url_https":"https://pbs.twimg.com/media/GwyvN3bbMAAZB6T.jpg","type":"photo","url":"https://t.co/Bod4ky2vfY","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1265,"resize":"fit"},"medium":{"h":1200,"w":741,"resize":"fit"},"small":{"h":680,"w":420,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2529,"focus_rects":[{"x":0,"y":824,"w":2529,"h":1416},{"x":0,"y":268,"w":2529,"h":2529},{"x":0,"y":91,"w":2529,"h":2883},{"x":0,"y":0,"w":2048,"h":4096},{"x":0,"y":0,"w":2529,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1949125391496720384"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1802308972503797760","name":"cakevm","screen_name":"cakevm","indices":[706,713]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/Bod4ky2vfY","expanded_url":"https://x.com/0xmomonifty/status/1949292154767237250/photo/1","id_str":"1949125229508526080","indices":[167,190],"media_key":"3_1949125229508526080","media_url_https":"https://pbs.twimg.com/media/GwyvEb-bgAA6Xg6.jpg","type":"photo","url":"https://t.co/Bod4ky2vfY","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1207,"resize":"fit"},"medium":{"h":1200,"w":707,"resize":"fit"},"small":{"h":680,"w":401,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2414,"focus_rects":[{"x":0,"y":652,"w":2414,"h":1352},{"x":0,"y":121,"w":2414,"h":2414},{"x":0,"y":0,"w":2414,"h":2752},{"x":304,"y":0,"w":2048,"h":4096},{"x":0,"y":0,"w":2414,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1949125229508526080"}}},{"display_url":"pic.x.com/Bod4ky2vfY","expanded_url":"https://x.com/0xmomonifty/status/1949292154767237250/photo/1","id_str":"1949125391496720384","indices":[167,190],"media_key":"3_1949125391496720384","media_url_https":"https://pbs.twimg.com/media/GwyvN3bbMAAZB6T.jpg","type":"photo","url":"https://t.co/Bod4ky2vfY","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1265,"resize":"fit"},"medium":{"h":1200,"w":741,"resize":"fit"},"small":{"h":680,"w":420,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2529,"focus_rects":[{"x":0,"y":824,"w":2529,"h":1416},{"x":0,"y":268,"w":2529,"h":2529},{"x":0,"y":91,"w":2529,"h":2883},{"x":0,"y":0,"w":2048,"h":4096},{"x":0,"y":0,"w":2529,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1949125391496720384"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1949292154767237250","view_count":32209,"bookmark_count":337,"created_at":1753582440000,"favorite_count":267,"quote_count":3,"reply_count":15,"retweet_count":46,"user_id_str":"1744901065886318592","conversation_id_str":"1949292154767237250","full_text":"【 Arbitrage 学习笔记 - ④ 交换路径 】\n\n在玩 Dex - Dex 套利的时候,计算和管理 Swap 的路径极为复杂,我们在同步获取到 Uniswap 各个交易对 Pool 之后,如何将池子之间路径连接起来形成路径,也是一门需要不断学习探索的步骤,下面是最近几天学习的笔记和资料分享给大家。\n\n▰▰▰▰▰▰\n套利路径\n\nA->B->C->…->A,使用 A 经过一系列池子之间的 Swap 之后能获得到更多的 A,这是我们的最终套利目的。我们把每个池子看成一条边,每条边都有一个起点和一个终点,形成一个环状的有向图,寻找路径就成了解决图问题。条数 hops 即为 Swap 长度,像我小白阶级可以先从 3 跳进行学习。\n目前最常见的 DFS(深度优先搜索),它从一个起始节点开始,沿着当前路径尽可能深地搜索,直到无法继续为止,然后回溯到上一个节点,选择另一条路径继续搜索。当然也有使用二分搜索等方法先确定范围进行求解。\n资料可参考 ccyanxyz/uniswap-arbitrage-analysis \n\n更高层次的可以按照价格 > 状态匹配度>路径条件进行排序,或者叠加更多因素进行凸面求解,最后算出来的路径进行交易。\n参考 advock/CFMM-Convex-Optimization- \n\n▰▰▰▰▰▰\n路径管理\n\n我们在根据自己喜好(比如我前期对池子大小进行筛选)进行过滤 Pool 后形成了许多数量的路径,但是众多池子鱼龙混杂,我们还需要一个 manager 来管理控制我们的路径数据库,进行黑白名单状态控制和交易对的快速查找。\n这里介绍一位在性能优化方面追求极致且极为出色的大佬 @cakevm 的 cakevm/swap-path。他也是 Loom 项目的重要贡献者,在群里,他非常热情且专业地解答大家的疑问,是我的崇拜对象。\n在这个项目中使用了 DashMap ,采用 DFS 计算多跳路径,可以非常方便快速的管理和查找池子和 Path,流程:新池加入 → 更新图结构 → DFS 查找所有可达路径 → 存储路径。\n\n以上均为个人笔记,理解可能存在问题,也非常感谢能够有大佬来指点一二","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/cKqSHJrpdW","expanded_url":"https://x.com/0xmomonifty/status/1962516933028581886/photo/1","id_str":"1962516510452424704","indices":[134,157],"media_key":"3_1962516510452424704","media_url_https":"https://pbs.twimg.com/media/GzxCXk9bIAAPWEQ.jpg","type":"photo","url":"https://t.co/cKqSHJrpdW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":746,"resize":"fit"},"medium":{"h":1200,"w":437,"resize":"fit"},"small":{"h":680,"w":248,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":1491,"focus_rects":[{"x":0,"y":95,"w":1491,"h":835},{"x":0,"y":0,"w":1491,"h":1491},{"x":0,"y":0,"w":1491,"h":1700},{"x":0,"y":0,"w":1491,"h":2982},{"x":0,"y":0,"w":1491,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1962516510452424704"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/cKqSHJrpdW","expanded_url":"https://x.com/0xmomonifty/status/1962516933028581886/photo/1","id_str":"1962516510452424704","indices":[134,157],"media_key":"3_1962516510452424704","media_url_https":"https://pbs.twimg.com/media/GzxCXk9bIAAPWEQ.jpg","type":"photo","url":"https://t.co/cKqSHJrpdW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":746,"resize":"fit"},"medium":{"h":1200,"w":437,"resize":"fit"},"small":{"h":680,"w":248,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":1491,"focus_rects":[{"x":0,"y":95,"w":1491,"h":835},{"x":0,"y":0,"w":1491,"h":1491},{"x":0,"y":0,"w":1491,"h":1700},{"x":0,"y":0,"w":1491,"h":2982},{"x":0,"y":0,"w":1491,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1962516510452424704"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1962516933028581886","view_count":24641,"bookmark_count":286,"created_at":1756735473000,"favorite_count":210,"quote_count":0,"reply_count":9,"retweet_count":37,"user_id_str":"1744901065886318592","conversation_id_str":"1962516933028581886","full_text":"【 Arbitrage 学习笔记 - ⑤ 寻找最优输入金额 】\n\n在 Dex-Dex 套利中,我们已经把 3 跳甚至 N 跳的路径全部枚举出来,接下来要做的就是:\n“在这些路径里,哪一条能给我带来最大利润?以及,我应该输入多少 tokens 才能让才能获得最大利润”\n\n之前我在路径查找的时候错误的理解成需要使用二分法快速的查找路径,怪自己学术不精误导了大家,非常尴尬,所以,非常恳求大佬们能够指点一二\n\n在利润计算的环节,这一步本质是一个带约束的线性规划问题。\n\n▰▰▰▰▰▰\n计算原理\n\n假设我们最终得到的路径是\nTokenA → TokenB → TokenC → TokenA\n把每一段池子的“有效汇率”写成 1×1 的标量:\nr₁ = ΔTokenB / ΔTokenA\nr₂ = ΔTokenC / ΔTokenB\nr₃ = ΔTokenA / ΔTokenC\n\n设投入 x 枚 TokenA,最终回收 y 枚 TokenA,则\nProfit (x) = y − x\n = x · r₁ · r₂ · r₃ − x\n = x (r₁r₂r₃ − 1)\n \n套利机会存在的充要条件是 r₁r₂r₃ > 1。\n\n这个方程通常没有解析解,需要用数值方法求根。其中牛顿迭代、二分查找或黄金分割,在一定的迭代次数内挑出能够获利的哪一条。\n\n▰▰▰▰▰▰\n方法示例\n\n在初次学习时,我们在程序中设置好最小金额和最大金额区间,以及循环步长后使用二分法左右寻找最优解。这里也可以参考 loom 的双向步长缩减算法,初始步长 1%,逐步缩小到 0.1%,以寻找利润最大化的输入金额。\n\n“把区间对半砍,看哪一半包含了根,再砍那一半,一直砍到足够细。”","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,168],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/HiCXV5gcE5","expanded_url":"https://x.com/0xmomonifty/status/1964326886336844143/photo/1","id_str":"1964326576117731333","indices":[169,192],"media_key":"3_1964326576117731333","media_url_https":"https://pbs.twimg.com/media/G0KwnRBbUAU7b7z.jpg","type":"photo","url":"https://t.co/HiCXV5gcE5","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1008,"resize":"fit"},"medium":{"h":1200,"w":590,"resize":"fit"},"small":{"h":680,"w":335,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2015,"focus_rects":[{"x":0,"y":1791,"w":2015,"h":1128},{"x":0,"y":1348,"w":2015,"h":2015},{"x":0,"y":1207,"w":2015,"h":2297},{"x":0,"y":66,"w":2015,"h":4030},{"x":0,"y":0,"w":2015,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1964326576117731333"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/HiCXV5gcE5","expanded_url":"https://x.com/0xmomonifty/status/1964326886336844143/photo/1","id_str":"1964326576117731333","indices":[169,192],"media_key":"3_1964326576117731333","media_url_https":"https://pbs.twimg.com/media/G0KwnRBbUAU7b7z.jpg","type":"photo","url":"https://t.co/HiCXV5gcE5","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1008,"resize":"fit"},"medium":{"h":1200,"w":590,"resize":"fit"},"small":{"h":680,"w":335,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2015,"focus_rects":[{"x":0,"y":1791,"w":2015,"h":1128},{"x":0,"y":1348,"w":2015,"h":2015},{"x":0,"y":1207,"w":2015,"h":2297},{"x":0,"y":66,"w":2015,"h":4030},{"x":0,"y":0,"w":2015,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1964326576117731333"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1964326886336844143","view_count":19327,"bookmark_count":205,"created_at":1757166999000,"favorite_count":189,"quote_count":1,"reply_count":12,"retweet_count":35,"user_id_str":"1744901065886318592","conversation_id_str":"1964326886336844143","full_text":"【 Arbitrage 学习笔记 - ⑥ 链上交易合约 】\n\n在寻找到有利润的套利路径之后,就是收尾将可获利交易提交到链上的部分了。这一步根据自己程序的逻辑习惯可以有很多方法,比如直接将 Pancake 和 Uniswap 的 Swap 接口打包进合约后调用,也可以在此基础上增加使用 Assembly 内联汇编方式将 calldata 需要按特定字节偏移量分段读取数据,进阶了可以使用 Huff 之类的低级类汇编语言来编写自己的逻辑极致节省 GAS,也是一个非常值得深入学习的挑战。\n\n到这一步其实基本流程已经跑通了,同步池子 - 构建路径 - 价格计算 - 寻找最优金额 - 交易上链,可以减少利润预期或者无视 Gas 成本或者负利润的进行一下上链通关。\n后续 Dex 套利我会逐步深入的学习一些知识,优化好每一步骤的细节,有时间过程也会写成内容分享给大家,当然内容可能会理解有误,欢迎大佬们指点分享。\n\n合约这一步 Momo 直接整合上了 Assembly 和闪电贷,所以跟我一样入门的小伙伴也可以尝试参考 solidquant/mev-templates 里面的 contracts ,将 amountIn、useLoan(闪电贷模式) 、loanPool(借贷池子)、第一跳的 router 、第一跳的 tokenIn、第一跳的 tokenOut 、第二跳的 router … \n根据 useLoan 进行闪电贷协议选择或者直接交易,使用 assembly 拆分好后面重复的多跳交换路径,其每三组地址即为一跳数据,长度就是条数 nhop。\n再根据路由地址执行相应协议的交换,最后可以 require (finalAmount >= repayAmount) 进行盈利检查,确保套利后的金额能覆盖闪电贷本金+手续费。\n这里需要特别注意的是,solidquant/mev-templates 的示例合约仅供参考,有授权漏洞,小伙伴入门的时候也要注意权限控制,比如授权、提款等操作,可以用 AI 来过一遍安全监测,毕竟也是资金交易的环节,合约安全即资金安全!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,175],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/KSfdEsqfbt","expanded_url":"https://x.com/0xmomonifty/status/1974142502635778316/photo/1","id_str":"1974142196191539207","indices":[176,199],"media_key":"3_1974142196191539207","media_url_https":"https://pbs.twimg.com/media/G2WP3jQbMAc0HHF.jpg","type":"photo","url":"https://t.co/KSfdEsqfbt","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1220,"w":2048,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2192,"width":3680,"focus_rects":[{"x":0,"y":131,"w":3680,"h":2061},{"x":744,"y":0,"w":2192,"h":2192},{"x":879,"y":0,"w":1923,"h":2192},{"x":1292,"y":0,"w":1096,"h":2192},{"x":0,"y":0,"w":3680,"h":2192}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1974142196191539207"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/KSfdEsqfbt","expanded_url":"https://x.com/0xmomonifty/status/1974142502635778316/photo/1","id_str":"1974142196191539207","indices":[176,199],"media_key":"3_1974142196191539207","media_url_https":"https://pbs.twimg.com/media/G2WP3jQbMAc0HHF.jpg","type":"photo","url":"https://t.co/KSfdEsqfbt","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1220,"w":2048,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2192,"width":3680,"focus_rects":[{"x":0,"y":131,"w":3680,"h":2061},{"x":744,"y":0,"w":2192,"h":2192},{"x":879,"y":0,"w":1923,"h":2192},{"x":1292,"y":0,"w":1096,"h":2192},{"x":0,"y":0,"w":3680,"h":2192}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1974142196191539207"}}}]},"favorited":true,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1974142502635778316","view_count":12847,"bookmark_count":220,"created_at":1759507225000,"favorite_count":163,"quote_count":1,"reply_count":9,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1974142502635778316","full_text":"【 Arbitrage 学习笔记 - 学习使用 Revm Database ① 】\n\n我刚开始学 Dex 套利时,为了计算 path 利润,直接用 RPC 拉取池子最新状态(用的 amms pool init),再把有利可图的交易 call 套利合约。虽然跑的是本地节点,但这套暴力操作还是会浪费服务器资源。\n后来我在学习大佬代码的时候发现一个宝藏的 crates -> revm:: database,可以使用该接口实现自己项目中一个小型内存数据库,这样既可以从 RPC Fork 目标账户等状态,也可以自由的修改调试执行状态变更。\n\n▰▰▰▰▰▰\n简单使用\n\n举个例子,我在上一篇中把最新区块变动的 Pool 保存下来包括池子的 reserve、slot 0 等状态已便后面的利润计算,那么我们开始尝试把这部分使用 revm:: database 实现一个内存数据库,记录和更新池子的信息。\n\n在 revm:: database 中,有一个 in_memory_db.rs ,其设计了一个 CacheDB,Cache 中有账户的基础信息(balance、nonce、code/code_hash) ,可以按需从只读后端懒加载账户/代码/存储,并支持本地执行后 commit 写回缓存,当然也可以使用它们外包一些适合自己的功能。\n\nCacheDB 有几个非常符合 EVM 的函数,load_account (),basic(),insert_contract (),insert_account_storage (),replace_account_storage ()。\n那么我们可以直接使用 insert_account_storage () 插入或修改 pool 的状态信息,\n\n之后我们可以使用 storage_ref () 来读取存储的最新 pool 信息,直接建立 AMM trait 来进行价格计算。运行后会发现 RPC 节点性能会非常稳定,且程序在建立池子信息时速度非常的快!\n\n▰▰▰▰▰▰\n小结\n\n这里我简单使用了 revm:: database ,但是它非常的强大,可以说是 REVM 与区块链状态之间的“桥梁”,之后我也会继续使用它来优化在程序中的细节,当然内容可能会理解有误,欢迎大佬们指点分享。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/8MSaltRadz","expanded_url":"https://x.com/0xmomonifty/status/1958100154839691687/photo/1","id_str":"1958100015647498240","indices":[160,183],"media_key":"3_1958100015647498240","media_url_https":"https://pbs.twimg.com/media/GyyRlvtbIAACtju.jpg","type":"photo","url":"https://t.co/8MSaltRadz","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":596,"w":1474,"resize":"fit"},"medium":{"h":485,"w":1200,"resize":"fit"},"small":{"h":275,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":596,"width":1474,"focus_rects":[{"x":0,"y":0,"w":1064,"h":596},{"x":33,"y":0,"w":596,"h":596},{"x":70,"y":0,"w":523,"h":596},{"x":182,"y":0,"w":298,"h":596},{"x":0,"y":0,"w":1474,"h":596}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1958100015647498240"}}},{"display_url":"pic.x.com/8MSaltRadz","expanded_url":"https://x.com/0xmomonifty/status/1958100154839691687/photo/1","id_str":"1958100047578697728","indices":[160,183],"media_key":"3_1958100047578697728","media_url_https":"https://pbs.twimg.com/media/GyyRnmqakAAw1yP.jpg","type":"photo","url":"https://t.co/8MSaltRadz","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1155,"w":2048,"resize":"fit"},"medium":{"h":677,"w":1200,"resize":"fit"},"small":{"h":383,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2012,"width":3568,"focus_rects":[{"x":0,"y":0,"w":3568,"h":1998},{"x":778,"y":0,"w":2012,"h":2012},{"x":902,"y":0,"w":1765,"h":2012},{"x":1281,"y":0,"w":1006,"h":2012},{"x":0,"y":0,"w":3568,"h":2012}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1958100047578697728"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/8MSaltRadz","expanded_url":"https://x.com/0xmomonifty/status/1958100154839691687/photo/1","id_str":"1958100015647498240","indices":[160,183],"media_key":"3_1958100015647498240","media_url_https":"https://pbs.twimg.com/media/GyyRlvtbIAACtju.jpg","type":"photo","url":"https://t.co/8MSaltRadz","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":596,"w":1474,"resize":"fit"},"medium":{"h":485,"w":1200,"resize":"fit"},"small":{"h":275,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":596,"width":1474,"focus_rects":[{"x":0,"y":0,"w":1064,"h":596},{"x":33,"y":0,"w":596,"h":596},{"x":70,"y":0,"w":523,"h":596},{"x":182,"y":0,"w":298,"h":596},{"x":0,"y":0,"w":1474,"h":596}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1958100015647498240"}}},{"display_url":"pic.x.com/8MSaltRadz","expanded_url":"https://x.com/0xmomonifty/status/1958100154839691687/photo/1","id_str":"1958100047578697728","indices":[160,183],"media_key":"3_1958100047578697728","media_url_https":"https://pbs.twimg.com/media/GyyRnmqakAAw1yP.jpg","type":"photo","url":"https://t.co/8MSaltRadz","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1155,"w":2048,"resize":"fit"},"medium":{"h":677,"w":1200,"resize":"fit"},"small":{"h":383,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2012,"width":3568,"focus_rects":[{"x":0,"y":0,"w":3568,"h":1998},{"x":778,"y":0,"w":2012,"h":2012},{"x":902,"y":0,"w":1765,"h":2012},{"x":1281,"y":0,"w":1006,"h":2012},{"x":0,"y":0,"w":3568,"h":2012}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1958100047578697728"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1958100154839691687","view_count":21477,"bookmark_count":161,"created_at":1755682431000,"favorite_count":143,"quote_count":2,"reply_count":6,"retweet_count":26,"user_id_str":"1744901065886318592","conversation_id_str":"1958100154839691687","full_text":"【 Arbitrage 学习笔记 - V3 池子 ticks 快速获取 】\n\n有些时候进行 V3 pool 进行交换会计算代币输入输出的具体价格及数量会考虑到池子的 tick 数据以及当前 tick 的流动性状态,我之前参照大佬 Zacholme7/PoolSync 会使用从历史区块同步的方法来获取池子的 ticks 状态,但是我在实际使用中只要当前池子的 ticks 数据,并不需要知道历史的变化,所以再回去查看文档和查阅资料发现其实还有更好的方法。(原谅我还只是小白)\n\n▰▰▰▰▰▰\nUni V3 Tick tickBitmap\n\n首先回顾一下,在 v3 中使用 Bitmap 来存储 tick 的状态例如:100101001101001,1 表示有流动性,0 没有被初始化,两个字节来存储 (0x4a69)。用 word n 来划分子数组,word 中有 256 个位置。\n\n▰▰▰▰▰▰\n使用合约获取 ticks 信息\n\n我之前使用区块事件扫描获取 mint/burn,其实在 V3 的 pool 有两个函数 tickBitmap() 和 ticks() 分别来获取位置信息和具体 ticks 信息,那么步骤就非常简单了,程序可以第一遍遍历计算 Bitmap word 数组大小如果 bitmap == 0 就跳过,第二遍获取有效的 word 中的 tick 数据。\n\n但是如果调用 RPC 还是需要发送大量的查询,那么这时候我们使用链上合约来一次性获取我们想要的信息,让节点把我们这步骤都做了。当然你也可以加上 tokenName,decimals 等信息。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,173],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/VkKtsCvz4u","expanded_url":"https://x.com/0xmomonifty/status/1947181136234569866/photo/1","id_str":"1947180609136369664","indices":[174,197],"media_key":"3_1947180609136369664","media_url_https":"https://pbs.twimg.com/media/GwXGcokaIAARK_k.png","type":"photo","url":"https://t.co/VkKtsCvz4u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1584,"w":2048,"resize":"fit"},"medium":{"h":928,"w":1200,"resize":"fit"},"small":{"h":526,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1632,"width":2110,"focus_rects":[{"x":0,"y":409,"w":2110,"h":1182},{"x":478,"y":0,"w":1632,"h":1632},{"x":600,"y":0,"w":1432,"h":1632},{"x":908,"y":0,"w":816,"h":1632},{"x":0,"y":0,"w":2110,"h":1632}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1947180609136369664"}}},{"display_url":"pic.x.com/VkKtsCvz4u","expanded_url":"https://x.com/0xmomonifty/status/1947181136234569866/photo/1","id_str":"1947180706146209792","indices":[174,197],"media_key":"3_1947180706146209792","media_url_https":"https://pbs.twimg.com/media/GwXGiR9W0AAOqoT.png","type":"photo","url":"https://t.co/VkKtsCvz4u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":714,"w":891,"resize":"fit"},"medium":{"h":714,"w":891,"resize":"fit"},"small":{"h":545,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":714,"width":891,"focus_rects":[{"x":0,"y":215,"w":891,"h":499},{"x":0,"y":0,"w":714,"h":714},{"x":21,"y":0,"w":626,"h":714},{"x":156,"y":0,"w":357,"h":714},{"x":0,"y":0,"w":891,"h":714}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1947180706146209792"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"desmos.com/calculator/7wb…","expanded_url":"https://www.desmos.com/calculator/7wbvkts2jf","url":"https://t.co/Dle9fL6SSi","indices":[593,616]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/VkKtsCvz4u","expanded_url":"https://x.com/0xmomonifty/status/1947181136234569866/photo/1","id_str":"1947180609136369664","indices":[174,197],"media_key":"3_1947180609136369664","media_url_https":"https://pbs.twimg.com/media/GwXGcokaIAARK_k.png","type":"photo","url":"https://t.co/VkKtsCvz4u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1584,"w":2048,"resize":"fit"},"medium":{"h":928,"w":1200,"resize":"fit"},"small":{"h":526,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1632,"width":2110,"focus_rects":[{"x":0,"y":409,"w":2110,"h":1182},{"x":478,"y":0,"w":1632,"h":1632},{"x":600,"y":0,"w":1432,"h":1632},{"x":908,"y":0,"w":816,"h":1632},{"x":0,"y":0,"w":2110,"h":1632}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1947180609136369664"}}},{"display_url":"pic.x.com/VkKtsCvz4u","expanded_url":"https://x.com/0xmomonifty/status/1947181136234569866/photo/1","id_str":"1947180706146209792","indices":[174,197],"media_key":"3_1947180706146209792","media_url_https":"https://pbs.twimg.com/media/GwXGiR9W0AAOqoT.png","type":"photo","url":"https://t.co/VkKtsCvz4u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":714,"w":891,"resize":"fit"},"medium":{"h":714,"w":891,"resize":"fit"},"small":{"h":545,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":714,"width":891,"focus_rects":[{"x":0,"y":215,"w":891,"h":499},{"x":0,"y":0,"w":714,"h":714},{"x":21,"y":0,"w":626,"h":714},{"x":156,"y":0,"w":357,"h":714},{"x":0,"y":0,"w":891,"h":714}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1947180706146209792"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1947181136234569866","view_count":14828,"bookmark_count":173,"created_at":1753079134000,"favorite_count":137,"quote_count":1,"reply_count":9,"retweet_count":29,"user_id_str":"1744901065886318592","conversation_id_str":"1947181136234569866","full_text":"【Arbitrage 学习笔记 - ③ 价格计算】\n\n我们有了各种协议池子的基础数据之后,就要开始着手价格计算和套利路径,这是非常关键的两步。\n\n这里我们先从价格计算入手,学习并简单记录一下 Uni 以及 Fork 其协议的相关的计算方法。\n\n中文资料可以阅读 adshao/publications 、uniswapV 3-book-zh-cn 或者直接啃 Dapp-Learning\n\n▰▰▰▰▰▰\n恒定函数做市商 (CFMM)\n\nV2V3 原理公式 x∗y=k 仅此而已且都围绕着它展开,其中 _x_ 代表第一个 token,_y_ 代表第二个 token,k 是他俩的乘积每次交易后保持不变。交易函数可以用它的原理推导出(x+rΔx)(y−Δy)=k,\nΔx 为交易放入池子的 token,Δy 为换取的 token,r 为池子手续费。\n\n▰▰▰▰▰▰\nV2 的价格计算\n\n在 V 2 中池子的价格是由 token 的供给量决定的,也就是池子的流动性,池子中两种 token 的数量决定了价格,即 P = y/x 。但是需要注意的是交易实际成交的价格却并不是这个价格,需要把需求也就是 swap 输入的代币数量考虑其中,需求越高,价格越高。\n\n(x+rΔx)(y−Δy)=xy -> Δy=(yrΔx)/(x+rΔx) 和 Δx= (xΔy)/(r(y-Δy))\n\n我们可以在 https://t.co/Dle9fL6SSi 可以看到我们卖出 200 个 token0 期望的到 200 个 token1,但实际只获得了133.333。(交易的实际发生价格,是连接新旧点的这条线的斜率)\n\n▰▰▰▰▰▰\nV3 的价格计算\n\n作为 V2 的升级,V3 把价格区间分成了许多 ticks,每个 ticks 对应一个价格,由许多 x∗y=k 的池子组成相互重叠,在交易的时候先确定交易的方向,如果交易数量当前tick范围内使用该tick的可用流动性进行交换,如果还有剩余输入代币,继续在下一个tick范围内进行交换。\n\nV3 的价格公式与 V2 一样,但为了流动性与价格成线性关系,两边开根(x 没法开根表示) ,使用 Q64.96 定点数格式,文档中经常会见到 sqrtRatioNextX96 表示下一个tick边界的价格的平方根。\n\n计算方法可以参考 amms-rs 和 uniswap_v3_math ,步骤理解为循环体( 计算下一个 tick 边界价格 -> 计算本 tick 区间最多能 swap 多少 -> 更新剩余输入、累计输出 -> 是否到达 tick 边界<是 → 更新流动性,tick前进/否 → tick=当前价格对应tick>) 返回累计输出。\n\n(图片摘自 uniswapV 3-book)\n\n以上均为个人理解笔记,如有问题请积极指出,也非常感谢能够有大佬来指点一二","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,146],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/AJsNgWlsBF","expanded_url":"https://x.com/0xmomonifty/status/1945760400454439151/photo/1","id_str":"1945759424422858752","indices":[147,170],"media_key":"3_1945759424422858752","media_url_https":"https://pbs.twimg.com/media/GwC54y8X0AAOJvF.png","type":"photo","url":"https://t.co/AJsNgWlsBF","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":233,"w":315,"resize":"fit"},"medium":{"h":233,"w":315,"resize":"fit"},"small":{"h":233,"w":315,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":233,"width":315,"focus_rects":[{"x":0,"y":57,"w":315,"h":176},{"x":0,"y":0,"w":233,"h":233},{"x":0,"y":0,"w":204,"h":233},{"x":28,"y":0,"w":117,"h":233},{"x":0,"y":0,"w":315,"h":233}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1945759424422858752"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[647,655]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/AJsNgWlsBF","expanded_url":"https://x.com/0xmomonifty/status/1945760400454439151/photo/1","id_str":"1945759424422858752","indices":[147,170],"media_key":"3_1945759424422858752","media_url_https":"https://pbs.twimg.com/media/GwC54y8X0AAOJvF.png","type":"photo","url":"https://t.co/AJsNgWlsBF","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":233,"w":315,"resize":"fit"},"medium":{"h":233,"w":315,"resize":"fit"},"small":{"h":233,"w":315,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":233,"width":315,"focus_rects":[{"x":0,"y":57,"w":315,"h":176},{"x":0,"y":0,"w":233,"h":233},{"x":0,"y":0,"w":204,"h":233},{"x":28,"y":0,"w":117,"h":233},{"x":0,"y":0,"w":315,"h":233}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1945759424422858752"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1945760400454439151","view_count":14621,"bookmark_count":143,"created_at":1752740404000,"favorite_count":119,"quote_count":2,"reply_count":9,"retweet_count":11,"user_id_str":"1744901065886318592","conversation_id_str":"1945760400454439151","full_text":"【 Arbitrage 学习笔记 - ② 同步池子 】\n\n在套利与 MEV 池子的基础数据是关键的起点,我们需要从区块链这个强大的数据库中把需要用到的各种协议池子的基础数据拿到手,已便后续路径以及利润的计算等。\n\n今天重新复习了一下这个最初的开始\n\n▰▰▰▰▰▰\n节点的选择\n\n在后期 BOT 的运行过程中,需要的大部分都是以实时或者最近几个区块数据,所以像 ETH、BSC 等 EVM 链只需跑 Full 之类的裁剪节点即可。第一次同步池子需要从早期区块开始,但是也就最初几次获取历史池子信息,直接使用免费额度的 infura、alchemy 等,同步后用 csv 或者自己喜欢的数据库存起来,大大可以减少自己的节点性能配置,除非经常需要历史数据回溯。\n\n▰▰▰▰▰▰\n池子同步\n\n最常见的 AMM 模型 Uni、Pancake v2v3 池子最初同步时保存合约地址、token0 地址名字精度、\nToken1 地址名字精度、费率即可。步骤为先用工厂合约(factory)地址和“池子创建事件”的签名,分批查询区块链的事件日志(logs),再从这些事件中解析出所有池子创建的合约地址,最后再批量同步每个池子的详细信息和状态。\n\n工厂合约在各个协议的文档中可以找到,可以直接 google 搜索如 \"pancakeswap doc\",找到 Factory Contract address 就可以看到所有链部署的地址。\n\n方法这里可以参照大佬写的 darkforestry/amms-rs,和 @rnmumu3 梦哥推荐过的 Zacholme7/PoolSync 非常的不错\n\n总体来说这部分还算简单,就是分批次去解析工厂合约创建池子的 Log,与大部分新土狗监控差不多,之前也有写过 Four meme 内盘聪明钱监控也是一样的步骤(不断 filter 新区块包含这些地址的的 log ,如果短时间内交易聪敏钱包 >3 就进行 TG 推送).","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,138],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1945325756294553626","view_count":15089,"bookmark_count":161,"created_at":1752636777000,"favorite_count":111,"quote_count":2,"reply_count":16,"retweet_count":13,"user_id_str":"1744901065886318592","conversation_id_str":"1945325756294553626","full_text":"前端时间沉迷于研究 AutoLP 发现很多东西其实都是之前学过的 Arbitrage 或者 Mev 非常类似 (没有完全成功过),所以准备回去研究一下这让我非常沉迷的玩意,我知道参与 DEX-DEX 是一场军备竞赛,但是他能让我学到非常多关于链上技术的知识,即使需要花钱去玩。\n\n所以接下来我也会将自己看到的学到的分享出来,也希望能够有更多的中文区伙伴讨论进来,毕竟许多这个圈子的社群都是英文大佬,有时候学习和沟通也非常的不方便。\n\n本人小白还在学习路上,内容仅供学习参考,如有问题请积极指出,也非常感谢能够有大佬来指点一二\n\n▰▰▰▰▰▰\n学习入门\n\n我第一次研究三角套利是从 solidquant/mev-templates 开始的,这个示例 Python/Javascript/Rust 三种语言,非常适合有一定 EVM 基础的小伙伴入门,而且在他的 Medium 也能找到好几期关于讨论 MEV 或者 Arbitrage 的文章,非常值得小白系统级入门。\n\n在他的示例中也能够非常清晰的了解到一个套利流程:检索历史所有池子 -> 异步处理计算影响的池子 -> 模拟计算多跳路径 -> 签署交易并创建包或发送到 Flashbots\n\n▰▰▰▰▰▰\n研究方向\n\n池子管理及计算\nV2 原理、V3 的计算,包括多跳中包含 V2V3 转换,如何做到寻找机会更快,套利公式更快更准,让套利空间更加有竞争性。\n这里分享几个框架 dexloom/loom 、darkforestry/amms-rs、0 xKitsune/uniswap-v 3-math,其中 loom 的作者们非常强大,能够将 Defi 套利工具模块化,能够非常高效的来定制自动化策略开发。\n\nGAS 优化\n寻找机会、计算最优利润、构建交易并快速提交以进入 N+1 区块。解决上述难题,最后演变成关于 Gas 的博弈,PGA - Price Gas Auction\n如何在有限的利润中,控制好你的 GAS 成本非常重要,这方面需要深入的学习 Solidity Yul 和 Huff 语言的基础知识,编写出属于自己的绝佳省油丰田合约,使用 Forge 等工具来测量 GAS 使用情况,合约入门前期可看 dexloom/multicaller\n\n基建军备\n一个不断扫描区块链以寻找新的机会,缺少不了一个强有力的 RPC,不管是主链还是策略都需要拥有强大的性能和与验证着足够近的机房,通常公共付费节点拥有严格的速率限制,并且短时间就会耗余额,目前不太会去使用这些。节点客户端的选择也非常重要,主网 Geth 客户端已经非常成熟,但也有像 Reth 或 Revm 这样的高级工具,高度模块化、强大的性能、活跃的社区。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,63],"entities":{"hashtags":[{"indices":[32,36],"text":"蓝鸟会"},{"indices":[37,43],"text":"SNAPS"},{"indices":[44,54],"text":"CookieFun"},{"indices":[55,63],"text":"SparkFi"}],"media":[{"display_url":"pic.x.com/JQ8vIghYnw","expanded_url":"https://x.com/0xmomonifty/status/1928277447880872389/photo/1","id_str":"1928277342159523841","indices":[64,87],"media_key":"3_1928277342159523841","media_url_https":"https://pbs.twimg.com/media/GsKeBrfaUAEM0F4.jpg","type":"photo","url":"https://t.co/JQ8vIghYnw","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":772,"w":1374,"resize":"fit"},"medium":{"h":674,"w":1200,"resize":"fit"},"small":{"h":382,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":772,"width":1374,"focus_rects":[{"x":0,"y":3,"w":1374,"h":769},{"x":0,"y":0,"w":772,"h":772},{"x":0,"y":0,"w":677,"h":772},{"x":47,"y":0,"w":386,"h":772},{"x":0,"y":0,"w":1374,"h":772}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1928277342159523841"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JQ8vIghYnw","expanded_url":"https://x.com/0xmomonifty/status/1928277447880872389/photo/1","id_str":"1928277342159523841","indices":[64,87],"media_key":"3_1928277342159523841","media_url_https":"https://pbs.twimg.com/media/GsKeBrfaUAEM0F4.jpg","type":"photo","url":"https://t.co/JQ8vIghYnw","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":772,"w":1374,"resize":"fit"},"medium":{"h":674,"w":1200,"resize":"fit"},"small":{"h":382,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":772,"width":1374,"focus_rects":[{"x":0,"y":3,"w":1374,"h":769},{"x":0,"y":0,"w":772,"h":772},{"x":0,"y":0,"w":677,"h":772},{"x":47,"y":0,"w":386,"h":772},{"x":0,"y":0,"w":1374,"h":772}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1928277342159523841"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1928277447880872389","view_count":4086,"bookmark_count":1,"created_at":1748572143000,"favorite_count":95,"quote_count":0,"reply_count":104,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1928277447880872389","full_text":"你关我,我关你\n\n一起 Cookies and Spark!\n\n#蓝鸟会 #SNAPS #CookieFun #SparkFi https://t.co/JQ8vIghYnw","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[{"indices":[2047,2053],"text":"steak"},{"indices":[2124,2130],"text":"steak"}],"media":[{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434358492102656","indices":[163,186],"media_key":"3_1929434358492102656","media_url_https":"https://pbs.twimg.com/media/Gsa6U5NbAAAdPz4.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":775,"y":667,"h":127,"w":127}]},"medium":{"faces":[{"x":454,"y":391,"h":74,"w":74}]},"small":{"faces":[{"x":257,"y":221,"h":42,"w":42}]},"orig":{"faces":[{"x":1267,"y":1091,"h":209,"w":209}]}},"sizes":{"large":{"h":1201,"w":2048,"resize":"fit"},"medium":{"h":704,"w":1200,"resize":"fit"},"small":{"h":399,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1962,"width":3346,"focus_rects":[{"x":0,"y":88,"w":3346,"h":1874},{"x":0,"y":0,"w":1962,"h":1962},{"x":58,"y":0,"w":1721,"h":1962},{"x":428,"y":0,"w":981,"h":1962},{"x":0,"y":0,"w":3346,"h":1962}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434358492102656"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434682288119809","indices":[163,186],"media_key":"3_1929434682288119809","media_url_https":"https://pbs.twimg.com/media/Gsa6nvcaIAEZXQS.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":445,"y":259,"h":239,"w":239}]},"medium":{"faces":[{"x":261,"y":152,"h":140,"w":140}]},"small":{"faces":[{"x":148,"y":86,"h":79,"w":79}]},"orig":{"faces":[{"x":451,"y":263,"h":242,"w":242}]}},"sizes":{"large":{"h":1700,"w":2048,"resize":"fit"},"medium":{"h":996,"w":1200,"resize":"fit"},"small":{"h":564,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1720,"width":2072,"focus_rects":[{"x":0,"y":0,"w":2072,"h":1160},{"x":0,"y":0,"w":1720,"h":1720},{"x":0,"y":0,"w":1509,"h":1720},{"x":139,"y":0,"w":860,"h":1720},{"x":0,"y":0,"w":2072,"h":1720}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434682288119809"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434767688445952","indices":[163,186],"media_key":"3_1929434767688445952","media_url_https":"https://pbs.twimg.com/media/Gsa6stlbsAABvWZ.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1166,"w":2048,"resize":"fit"},"medium":{"h":683,"w":1200,"resize":"fit"},"small":{"h":387,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1542,"width":2708,"focus_rects":[{"x":0,"y":0,"w":2708,"h":1516},{"x":0,"y":0,"w":1542,"h":1542},{"x":0,"y":0,"w":1353,"h":1542},{"x":0,"y":0,"w":771,"h":1542},{"x":0,"y":0,"w":2708,"h":1542}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434767688445952"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929435039240220672","indices":[163,186],"media_key":"3_1929435039240220672","media_url_https":"https://pbs.twimg.com/media/Gsa68hMa8AAADc3.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":160,"y":272,"h":271,"w":271}]},"medium":{"faces":[{"x":160,"y":272,"h":271,"w":271}]},"small":{"faces":[{"x":95,"y":163,"h":162,"w":162}]},"orig":{"faces":[{"x":160,"y":272,"h":271,"w":271}]}},"sizes":{"large":{"h":970,"w":1134,"resize":"fit"},"medium":{"h":970,"w":1134,"resize":"fit"},"small":{"h":582,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":970,"width":1134,"focus_rects":[{"x":0,"y":335,"w":1134,"h":635},{"x":0,"y":0,"w":970,"h":970},{"x":0,"y":0,"w":851,"h":970},{"x":69,"y":0,"w":485,"h":970},{"x":0,"y":0,"w":1134,"h":970}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929435039240220672"}}}],"symbols":[{"indices":[1429,1436],"text":"Cookie"},{"indices":[1496,1503],"text":"Cookie"},{"indices":[1600,1605],"text":"USDS"},{"indices":[1612,1619],"text":"Pendle"},{"indices":[2467,2473],"text":"Kaito"}],"timestamps":[],"urls":[{"display_url":"guild.xyz/sparkdotfi","expanded_url":"https://guild.xyz/sparkdotfi","url":"https://t.co/i0RxxEK1Rx","indices":[1954,1977]}],"user_mentions":[{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[40,53]},{"id_str":"1522696492791869445","name":"Kaito AI 🌊","screen_name":"KaitoAI","indices":[57,65]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[40,53]},{"id_str":"1522696492791869445","name":"Kaito AI 🌊","screen_name":"KaitoAI","indices":[57,65]},{"id_str":"1085216475550531585","name":"Aagent.ai","screen_name":"aagentai","indices":[1479,1488]},{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[1527,1538]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434358492102656","indices":[163,186],"media_key":"3_1929434358492102656","media_url_https":"https://pbs.twimg.com/media/Gsa6U5NbAAAdPz4.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":775,"y":667,"h":127,"w":127}]},"medium":{"faces":[{"x":454,"y":391,"h":74,"w":74}]},"small":{"faces":[{"x":257,"y":221,"h":42,"w":42}]},"orig":{"faces":[{"x":1267,"y":1091,"h":209,"w":209}]}},"sizes":{"large":{"h":1201,"w":2048,"resize":"fit"},"medium":{"h":704,"w":1200,"resize":"fit"},"small":{"h":399,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1962,"width":3346,"focus_rects":[{"x":0,"y":88,"w":3346,"h":1874},{"x":0,"y":0,"w":1962,"h":1962},{"x":58,"y":0,"w":1721,"h":1962},{"x":428,"y":0,"w":981,"h":1962},{"x":0,"y":0,"w":3346,"h":1962}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434358492102656"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434682288119809","indices":[163,186],"media_key":"3_1929434682288119809","media_url_https":"https://pbs.twimg.com/media/Gsa6nvcaIAEZXQS.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":445,"y":259,"h":239,"w":239}]},"medium":{"faces":[{"x":261,"y":152,"h":140,"w":140}]},"small":{"faces":[{"x":148,"y":86,"h":79,"w":79}]},"orig":{"faces":[{"x":451,"y":263,"h":242,"w":242}]}},"sizes":{"large":{"h":1700,"w":2048,"resize":"fit"},"medium":{"h":996,"w":1200,"resize":"fit"},"small":{"h":564,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1720,"width":2072,"focus_rects":[{"x":0,"y":0,"w":2072,"h":1160},{"x":0,"y":0,"w":1720,"h":1720},{"x":0,"y":0,"w":1509,"h":1720},{"x":139,"y":0,"w":860,"h":1720},{"x":0,"y":0,"w":2072,"h":1720}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434682288119809"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434767688445952","indices":[163,186],"media_key":"3_1929434767688445952","media_url_https":"https://pbs.twimg.com/media/Gsa6stlbsAABvWZ.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1166,"w":2048,"resize":"fit"},"medium":{"h":683,"w":1200,"resize":"fit"},"small":{"h":387,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1542,"width":2708,"focus_rects":[{"x":0,"y":0,"w":2708,"h":1516},{"x":0,"y":0,"w":1542,"h":1542},{"x":0,"y":0,"w":1353,"h":1542},{"x":0,"y":0,"w":771,"h":1542},{"x":0,"y":0,"w":2708,"h":1542}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434767688445952"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929435039240220672","indices":[163,186],"media_key":"3_1929435039240220672","media_url_https":"https://pbs.twimg.com/media/Gsa68hMa8AAADc3.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":160,"y":272,"h":271,"w":271}]},"medium":{"faces":[{"x":160,"y":272,"h":271,"w":271}]},"small":{"faces":[{"x":95,"y":163,"h":162,"w":162}]},"orig":{"faces":[{"x":160,"y":272,"h":271,"w":271}]}},"sizes":{"large":{"h":970,"w":1134,"resize":"fit"},"medium":{"h":970,"w":1134,"resize":"fit"},"small":{"h":582,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":970,"width":1134,"focus_rects":[{"x":0,"y":335,"w":1134,"h":635},{"x":0,"y":0,"w":970,"h":970},{"x":0,"y":0,"w":851,"h":970},{"x":69,"y":0,"w":485,"h":970},{"x":0,"y":0,"w":1134,"h":970}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929435039240220672"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1929435806248395228","view_count":5287,"bookmark_count":1,"created_at":1748848318000,"favorite_count":89,"quote_count":2,"reply_count":88,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1929435806248395228","full_text":"【互动互关贴 - 在嘴撸的赛道,我们到底应该怎么撸】\n\n在去中心化区块链领域, @cookiedotfun 和 @KaitoAI 的 InfoFi 时代带来了深刻变革。\n\n过去,加密市场信息碎片化严重,优质内容难以凸显。Kaito 和 Cookie 通过 AI 技术与激励机制,重新赋予信息价值。Kaito 的 Yaps 机制依据内容影响力、深度等维度奖励创作者,Cookie 的 Snaps 则侧重内容质量、用户参与情绪等多维社交信号,鼓励用户专注单一项目、长期参与,构建起围绕优质内容的注意力经济体系。\n\n那么如何深度的参与到 InfoFi 当中去,来获得丰厚的回报极为重要。但是现在铺天盖地的“嘴撸”推文,大量同质化、缺乏深度的内容充斥社区,导致信息过载,用户难以获取有价值的信息,且不利于项目以及 InfoFi 的可持续发展。\n\n所以下面以 Momo 个人的想法来展开讲讲如何去精细化深入研究项目背景、技术细节和市场前景,确保内容具有深度和价值,以及饱和式参与交互。\n\n====\n# 细读 & 挖掘 -> 内容输出\n\n每当一个项目有一个特点非常吸引你进行参与时,首先得仔细研读项目的白皮书,理解其核心理念。如 Cookie 聚焦于 X 平台数据,通过低延迟访问实时数据,即时洞察市场动态和社会参与情况,并过情绪分析和忠诚度评分激励内容创作。\n所以我们在文章内容输出时,要为读者提供有价值的信息和独特的视角。当然优先聚焦在热点内容,或者聚焦在自己擅长的细分领域发布专业内容来获得丰厚的流量。一定要避免发布泛泛水文,以及同质化文章。\n\n在深入了解项目的同时得了解其技术架构,Cookie 侧重于情绪分析和忠诚度评分,能够提供针对加密货币的特定智能分析,拥有专有的指标,如智能互动评分,可过滤掉机器人活动。\n所以我们在文章发布的同时,要与相关用户多参与互评,且要多与排行榜、高质量博主进行互动,如果通时得到高权重博主回复就非常加分,务必记住互动内容必须要有价值。\n\n总结重点就是要提高 Mindshare 指标 (用于量化项目或账户在加密生态系统中获得的关注度和参与度) 。\n1. 撰写深度文章,可以从自己的笔记开始,不要水文,同质化文章\n2. 多互动多回复有价值的内容,高权重博主互动非常加分\n\n====\n# 交互 & 质押 -> 深度参与\n\n积极参与生态交互能够通过实际使用,深入了解平台的用户体验、数据质量,并且能够在后期的社区讨论中提出自己的建议和想法。\n\n比如 Cookie 与 Spark (SparkDotFi) 第一个合作项目活动中,我们可以在 Cookie 上参与社区互动,发布与 Spark 相关的内容来赚取 Snaps 积分。同时 Cookie 本身可以进行质押和空投挖矿,Spark 是一个借贷平台,也可以参与参与质押、借贷等。\n\n在 Cookie 中,我们可以质押 Cookie 代币来获得积分,根据积分的数量对应相应的等级。\n\n目前年化以及积分对应为:\n30天:1倍积分,APY: 1.01% \n90天:2倍积分,APY: 3.98% \n180天:3倍积分,APY: 8% \n365天:5倍积分,APY: 12.41%\n\n积分对应等级\n▪︎500:Bronze青铜 \n▪︎5000:Sliver白银 \n▪︎20000:Gold黄金 \n▪︎100000:Platinum铂金 \n▪︎500000:Diamond钻石\n\n在进行 $Cookie 的质押和撸积分之后,我们可以在 Farming 以及后去的活动中获得空投,在前几天\n@aagentai 项目方已经给 $Cookie 的质押着们进行了空投分配!\n\n在 Spark @sparkdotfi 中,我们可以通过质押稳定币 USDC USDS DAI 等,来获得预期空投和实际年化收益。也可以在 Points 中质押 $USDS YT 或者 $Pendle 来获取积分。当然你还可以在他的借贷中借出代币来充分利用自己的资金。\n\n质押代币在目前的 Defi 世界中,以及项目生态不断壮大的路途中是一个不错的选择,毕竟项目方的成长也离不开强大的流动性支撑,项目方也愿意将空投份额留给参与质押者们。当然需根据自己的风险承受能力和投资目标,制定合理的质押策略。\n\n====\n# 交流 & NFT -> 获取身份\n\n在参与项目交互的同时,在交流群组中,积极参与讨论和互动,与其他用户分享信息和观点,也十分的重要。通过 DC 等社交群组中积极参与交流、活动,提升自己在社区中的知名度和影响力,能够获得项目方或者社区极为难得的尊贵身份,能够为以后社交链接空投带来不错的收益。\n\n比如在 Spark 的 DC 中,我们首先需要 Guild (https://t.co/i0RxxEK1Rx) 中做完社交任务 (特别是 1-5-2) 才能在 DC 中发言,在 DC 中多多交流发表自己的看法,即可获得 sparkies 积分。在 #steak 频道输入【\"/daily\"、\"/weekly\"、\"/monthly\" 】来进行签到也可获得积分,当得到 sparkies 积分之后就可以在 #steak 频道输入 /shop 来购买积分角色。当然不同的积分、XP 对应不同的角色,不同的角色也对对应不同的身份、以及未来的收获!\n\n积分对应角色:\n200 -> sparkie Lvl 1\n250 -> sparkie Lvl 2\n300 -> sparkie Lvl 3 \n350 -> sparkie Lvl 4 \n400 -> psparkie Lvl 5 \n\n参与早期 NFT 获取获得项目的早期身份标识的同时也能够因 NFT 的价格大幅增长带来巨额收益。目前许多项目会为早期持有者提供独家的社区访问权和参与权,可以简单的理解为是项目的早期 \"股东\"。\n\n比如之前 Kaito 的 Genesis NFT,不仅项目方进行 TGE 的时候对 NFT 的持有者进行了丰厚的 $Kaito 代币空投,其他项目方也对该持有者进行了特殊空投。并且对 Genesis NFT 的持有者将持续享有生态优先权。\n\n(Kaito Genesis NFT - PFP 都好可爱!)\n\n所以说,在参与 InfoFi 项目的过程中,除了深入了解项目的技术架构和市场前景外,积极参与社区交流和获取身份标识(如 NFT)也是一种极为有效的策略。通过在社区中积极互动、完成社交任务、积累积分,不仅可以提升自己在社区中的知名度和影响力,还能获得项目方或社区赋予的独特身份和权益,这些身份和权益在未来可能会带来可观的收益。\n\n====\n# 总结\n在 InfoFi 项目中,深度参与不仅意味着获取短期的空投收益,更是在加密市场中建立长期个人账号影响力的必经之路。通过深度研究项目背景、技术细节和市场前景,积极参与生态交互,以及通过社区交流和获取身份标识(如 NFT)提升自己的知名度和影响力,可以在 InfoFi 领域的带领下实现自己的价值的最大化。知识是不断积累,财富也是~!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,157],"entities":{"hashtags":[{"indices":[348,356],"text":"SparkFi"},{"indices":[357,364],"text":"Cookie"},{"indices":[365,372],"text":"infofi"},{"indices":[373,379],"text":"SNAPS"},{"indices":[380,385],"text":"DeFi"}],"media":[{"display_url":"pic.x.com/upHHbb7H2f","expanded_url":"https://x.com/0xmomonifty/status/1931001444020474279/photo/1","id_str":"1931000299856216064","indices":[158,181],"media_key":"3_1931000299856216064","media_url_https":"https://pbs.twimg.com/media/GsxKirYaQAAIosf.jpg","type":"photo","url":"https://t.co/upHHbb7H2f","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1262,"w":1628,"resize":"fit"},"medium":{"h":930,"w":1200,"resize":"fit"},"small":{"h":527,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1262,"width":1628,"focus_rects":[{"x":0,"y":0,"w":1628,"h":912},{"x":0,"y":0,"w":1262,"h":1262},{"x":0,"y":0,"w":1107,"h":1262},{"x":0,"y":0,"w":631,"h":1262},{"x":0,"y":0,"w":1628,"h":1262}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1931000299856216064"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[66,79]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[66,79]},{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[322,333]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[334,347]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/upHHbb7H2f","expanded_url":"https://x.com/0xmomonifty/status/1931001444020474279/photo/1","id_str":"1931000299856216064","indices":[158,181],"media_key":"3_1931000299856216064","media_url_https":"https://pbs.twimg.com/media/GsxKirYaQAAIosf.jpg","type":"photo","url":"https://t.co/upHHbb7H2f","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1262,"w":1628,"resize":"fit"},"medium":{"h":930,"w":1200,"resize":"fit"},"small":{"h":527,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1262,"width":1628,"focus_rects":[{"x":0,"y":0,"w":1628,"h":912},{"x":0,"y":0,"w":1262,"h":1262},{"x":0,"y":0,"w":1107,"h":1262},{"x":0,"y":0,"w":631,"h":1262},{"x":0,"y":0,"w":1628,"h":1262}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1931000299856216064"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1931001444020474279","view_count":2677,"bookmark_count":1,"created_at":1749221595000,"favorite_count":81,"quote_count":0,"reply_count":73,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1931001444020474279","full_text":"【 今日互关互动-听说今天 Cookie 加分比以前猛了 】\n\n看了一下排行榜,今天猛一点的都能拿到 SNAPS 32 分了,今早 @cookiedotfun 官方也宣布开始支持除英文外其他语言,包括中文!\n\n这表明了一个好现象, 饼干厂的的 InfoFi 变得越来越公平,我们这些小蓝 V 也能竞争一下喝口汤啦!\n\n当然在InfoFi项目中,深度参与绝非仅仅是为了短期的空投收益,更是构建长期个人影响力的关键路径。\n\n深入钻研项目背景、技术细节与市场前景,积极投身生态互动,借助社区交流及获取身份标识(如NFT)来提升知名度,便能在InfoFi领域引领下,实现个人价值的最大化。记住,知识与财富,皆需日积月累!\n\n一起加油 ! 饼干兄弟们!\n@sparkdotfi\n@cookiedotfun\n#SparkFi #Cookie #infofi #SNAPS #DeFi","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,173],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/lohl9mN2dQ","expanded_url":"https://x.com/0xmomonifty/status/1943140383522984388/photo/1","id_str":"1943139588509437952","indices":[174,197],"media_key":"3_1943139588509437952","media_url_https":"https://pbs.twimg.com/media/GvdrKRoakAAqCWE.jpg","type":"photo","url":"https://t.co/lohl9mN2dQ","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":498,"w":1434,"resize":"fit"},"medium":{"h":417,"w":1200,"resize":"fit"},"small":{"h":236,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":498,"width":1434,"focus_rects":[{"x":0,"y":0,"w":889,"h":498},{"x":0,"y":0,"w":498,"h":498},{"x":0,"y":0,"w":437,"h":498},{"x":55,"y":0,"w":249,"h":498},{"x":0,"y":0,"w":1434,"h":498}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943139588509437952"}}},{"display_url":"pic.x.com/lohl9mN2dQ","expanded_url":"https://x.com/0xmomonifty/status/1943140383522984388/photo/1","id_str":"1943139619073134593","indices":[174,197],"media_key":"3_1943139619073134593","media_url_https":"https://pbs.twimg.com/media/GvdrMDfXkAE5m5-.jpg","type":"photo","url":"https://t.co/lohl9mN2dQ","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":76,"w":902,"resize":"fit"},"medium":{"h":76,"w":902,"resize":"fit"},"small":{"h":57,"w":680,"resize":"fit"},"thumb":{"h":76,"w":76,"resize":"crop"}},"original_info":{"height":76,"width":902,"focus_rects":[{"x":89,"y":0,"w":136,"h":76},{"x":119,"y":0,"w":76,"h":76},{"x":124,"y":0,"w":67,"h":76},{"x":138,"y":0,"w":38,"h":76},{"x":0,"y":0,"w":902,"h":76}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943139619073134593"}}},{"display_url":"pic.x.com/lohl9mN2dQ","expanded_url":"https://x.com/0xmomonifty/status/1943140383522984388/photo/1","id_str":"1943139664644407296","indices":[174,197],"media_key":"3_1943139664644407296","media_url_https":"https://pbs.twimg.com/media/GvdrOtQaAAAA7ZH.jpg","type":"photo","url":"https://t.co/lohl9mN2dQ","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":96,"w":1092,"resize":"fit"},"medium":{"h":96,"w":1092,"resize":"fit"},"small":{"h":60,"w":680,"resize":"fit"},"thumb":{"h":96,"w":96,"resize":"crop"}},"original_info":{"height":96,"width":1092,"focus_rects":[{"x":51,"y":0,"w":171,"h":96},{"x":88,"y":0,"w":96,"h":96},{"x":94,"y":0,"w":84,"h":96},{"x":112,"y":0,"w":48,"h":96},{"x":0,"y":0,"w":1092,"h":96}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943139664644407296"}}},{"display_url":"pic.x.com/lohl9mN2dQ","expanded_url":"https://x.com/0xmomonifty/status/1943140383522984388/photo/1","id_str":"1943139698521546753","indices":[174,197],"media_key":"3_1943139698521546753","media_url_https":"https://pbs.twimg.com/media/GvdrQrdWIAEY9Ws.jpg","type":"photo","url":"https://t.co/lohl9mN2dQ","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":74,"w":1022,"resize":"fit"},"medium":{"h":74,"w":1022,"resize":"fit"},"small":{"h":49,"w":680,"resize":"fit"},"thumb":{"h":74,"w":74,"resize":"crop"}},"original_info":{"height":74,"width":1022,"focus_rects":[{"x":828,"y":0,"w":132,"h":74},{"x":857,"y":0,"w":74,"h":74},{"x":862,"y":0,"w":65,"h":74},{"x":876,"y":0,"w":37,"h":74},{"x":0,"y":0,"w":1022,"h":74}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943139698521546753"}}}],"symbols":[{"indices":[84,87],"text":"BR"},{"indices":[84,87],"text":"BR"},{"indices":[84,87],"text":"BR"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/lohl9mN2dQ","expanded_url":"https://x.com/0xmomonifty/status/1943140383522984388/photo/1","id_str":"1943139588509437952","indices":[174,197],"media_key":"3_1943139588509437952","media_url_https":"https://pbs.twimg.com/media/GvdrKRoakAAqCWE.jpg","type":"photo","url":"https://t.co/lohl9mN2dQ","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":498,"w":1434,"resize":"fit"},"medium":{"h":417,"w":1200,"resize":"fit"},"small":{"h":236,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":498,"width":1434,"focus_rects":[{"x":0,"y":0,"w":889,"h":498},{"x":0,"y":0,"w":498,"h":498},{"x":0,"y":0,"w":437,"h":498},{"x":55,"y":0,"w":249,"h":498},{"x":0,"y":0,"w":1434,"h":498}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943139588509437952"}}},{"display_url":"pic.x.com/lohl9mN2dQ","expanded_url":"https://x.com/0xmomonifty/status/1943140383522984388/photo/1","id_str":"1943139619073134593","indices":[174,197],"media_key":"3_1943139619073134593","media_url_https":"https://pbs.twimg.com/media/GvdrMDfXkAE5m5-.jpg","type":"photo","url":"https://t.co/lohl9mN2dQ","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":76,"w":902,"resize":"fit"},"medium":{"h":76,"w":902,"resize":"fit"},"small":{"h":57,"w":680,"resize":"fit"},"thumb":{"h":76,"w":76,"resize":"crop"}},"original_info":{"height":76,"width":902,"focus_rects":[{"x":89,"y":0,"w":136,"h":76},{"x":119,"y":0,"w":76,"h":76},{"x":124,"y":0,"w":67,"h":76},{"x":138,"y":0,"w":38,"h":76},{"x":0,"y":0,"w":902,"h":76}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943139619073134593"}}},{"display_url":"pic.x.com/lohl9mN2dQ","expanded_url":"https://x.com/0xmomonifty/status/1943140383522984388/photo/1","id_str":"1943139664644407296","indices":[174,197],"media_key":"3_1943139664644407296","media_url_https":"https://pbs.twimg.com/media/GvdrOtQaAAAA7ZH.jpg","type":"photo","url":"https://t.co/lohl9mN2dQ","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":96,"w":1092,"resize":"fit"},"medium":{"h":96,"w":1092,"resize":"fit"},"small":{"h":60,"w":680,"resize":"fit"},"thumb":{"h":96,"w":96,"resize":"crop"}},"original_info":{"height":96,"width":1092,"focus_rects":[{"x":51,"y":0,"w":171,"h":96},{"x":88,"y":0,"w":96,"h":96},{"x":94,"y":0,"w":84,"h":96},{"x":112,"y":0,"w":48,"h":96},{"x":0,"y":0,"w":1092,"h":96}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943139664644407296"}}},{"display_url":"pic.x.com/lohl9mN2dQ","expanded_url":"https://x.com/0xmomonifty/status/1943140383522984388/photo/1","id_str":"1943139698521546753","indices":[174,197],"media_key":"3_1943139698521546753","media_url_https":"https://pbs.twimg.com/media/GvdrQrdWIAEY9Ws.jpg","type":"photo","url":"https://t.co/lohl9mN2dQ","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":74,"w":1022,"resize":"fit"},"medium":{"h":74,"w":1022,"resize":"fit"},"small":{"h":49,"w":680,"resize":"fit"},"thumb":{"h":74,"w":74,"resize":"crop"}},"original_info":{"height":74,"width":1022,"focus_rects":[{"x":828,"y":0,"w":132,"h":74},{"x":857,"y":0,"w":74,"h":74},{"x":862,"y":0,"w":65,"h":74},{"x":876,"y":0,"w":37,"h":74},{"x":0,"y":0,"w":1022,"h":74}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943139698521546753"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1943140383522984388","view_count":5954,"bookmark_count":75,"created_at":1752115743000,"favorite_count":49,"quote_count":1,"reply_count":3,"retweet_count":6,"user_id_str":"1744901065886318592","conversation_id_str":"1943140383522984388","full_text":"【 AutoLP 学习笔记 - ② 】\n\n最近简单的尝试写了一下 AutoLP ,测试下来有一定的可行性,但是还需需要考虑的更多因素,不然会亏损的非常严重,比如今天的 $BR 暴跌 50%。\n\n▰▰▰▰▰▰\n整理逻辑\n\nLP BOT 设计逻辑其实非常清晰:监听区块 -> 获取池子在新区块的状态 (比例/价格/流动性/tick) -> 计算自己 LP 价格及区间状态 -> 判断是否需要调整 LP,在调整 LP 动作中,新手期可以先设计成直接暴力平衡 Token0 和 Token1 比例为价值的 5:5 再 Mint 成 LP。\n\n▰▰▰▰▰▰\n开始实现\n\n这次在 Github 找到一位科学家 Fork paradigm/artemis 并用了最新的 alloy 1 的 MEV 框架【burberry】,(贴连接限流,大家自行搜索哈),所以接下来就用这个框架和 alloy 来写。\n\n1. 主程序逻辑\n首先创建 provider 连接节点,这里我是用的是 IPC (Geth 的本地通信机制) ,一般不做数据分析可以直接使用 http/ws 的 rpc,公共或者付费都可以。\n创建引擎\n创建过滤器, 监听 block 事件\n将 block 事件添加到收集器中\n至此已完成上期提到的 _Collectors_(收集器) 部分即最新区块产生事件(也可以理解为订阅新区块产生)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,151],"entities":{"hashtags":[{"indices":[528,535],"text":"COOKIE"},{"indices":[536,541],"text":"SOIL"}],"media":[{"display_url":"pic.x.com/hVnNIEHbyI","expanded_url":"https://x.com/0xmomonifty/status/1929784933851300316/photo/1","id_str":"1929784609321242624","indices":[152,175],"media_key":"3_1929784609321242624","media_url_https":"https://pbs.twimg.com/media/Gsf44LOb0AAzUX5.jpg","type":"photo","url":"https://t.co/hVnNIEHbyI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":655,"w":1583,"resize":"fit"},"medium":{"h":497,"w":1200,"resize":"fit"},"small":{"h":281,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":655,"width":1583,"focus_rects":[{"x":246,"y":0,"w":1170,"h":655},{"x":504,"y":0,"w":655,"h":655},{"x":544,"y":0,"w":575,"h":655},{"x":667,"y":0,"w":328,"h":655},{"x":0,"y":0,"w":1583,"h":655}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929784609321242624"}}}],"symbols":[{"indices":[168,172],"text":"KET"},{"indices":[542,547],"text":"SOIL"}],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[138,151]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[138,151]},{"id_str":"1752118369430482944","name":"Apex 2025","screen_name":"xrplapex","indices":[223,232]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[514,527]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/hVnNIEHbyI","expanded_url":"https://x.com/0xmomonifty/status/1929784933851300316/photo/1","id_str":"1929784609321242624","indices":[152,175],"media_key":"3_1929784609321242624","media_url_https":"https://pbs.twimg.com/media/Gsf44LOb0AAzUX5.jpg","type":"photo","url":"https://t.co/hVnNIEHbyI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":655,"w":1583,"resize":"fit"},"medium":{"h":497,"w":1200,"resize":"fit"},"small":{"h":281,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":655,"width":1583,"focus_rects":[{"x":246,"y":0,"w":1170,"h":655},{"x":504,"y":0,"w":655,"h":655},{"x":544,"y":0,"w":575,"h":655},{"x":667,"y":0,"w":328,"h":655},{"x":0,"y":0,"w":1583,"h":655}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929784609321242624"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1929784933851300316","view_count":1174,"bookmark_count":1,"created_at":1748931556000,"favorite_count":44,"quote_count":0,"reply_count":34,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1929784933851300316","full_text":"【 Soil 官方宣布与 Cookie 合作,饼干建设的兄弟们猪脚饭又要来了 】\n\nCookie 作为一个极具潜力的项目,一直以来都备受关注。它不仅拥有庞大的用户基础和强大的社区支持,还不断通过创新和合作拓展自己的生态版图。\n\n此前,已经有 200 多个 Web 3 项目向 @cookiedotfun 抛出了合作的橄榄枝,包括此前的 $KET 要给 SNAPS 的前 25 名发放 5 W 美金的空投,排行榜靠前的大佬都麻了。\n\nSoil 是 @xrplapex 的官方赞助商,它通过将中小企业贷款打包成数字资产,也是最近热火的 RWA 赛道。Soil 是一个基于区块链的借贷协议,它连接了传统金融和加密世界,重塑了中小企业债务和固定收益投资。它是一个债务市场,成熟的公司可以在这里获得融资,而加密投资者可以将他们的稳定币借出,以赚取来自链下真实世界资产的收益。\n\n目前能了解到的信息并不是很多,但是从 Cookie 的热度以及 RWA 的热点项目来说,无疑是强强联合的典范。 Cookie 通过与 Soil 的合作,进一步拓展其在 RWA 赛道的布局,为用户提供更多元化的投资选择。\n\nCookie 的兄弟们一起建设起来!\n@cookiedotfun\n#COOKIE #SOIL $SOIL","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,153],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591154945015808","indices":[154,177],"media_key":"3_1943591154945015808","media_url_https":"https://pbs.twimg.com/media/GvkF25sWwAArEJr.png","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":865,"w":775,"resize":"fit"},"medium":{"h":865,"w":775,"resize":"fit"},"small":{"h":680,"w":609,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":865,"width":775,"focus_rects":[{"x":0,"y":107,"w":775,"h":434},{"x":0,"y":0,"w":775,"h":775},{"x":0,"y":0,"w":759,"h":865},{"x":151,"y":0,"w":433,"h":865},{"x":0,"y":0,"w":775,"h":865}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591154945015808"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591188952469504","indices":[154,177],"media_key":"3_1943591188952469504","media_url_https":"https://pbs.twimg.com/media/GvkF44YXUAAnK_q.jpg","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1264,"w":1404,"resize":"fit"},"medium":{"h":1080,"w":1200,"resize":"fit"},"small":{"h":612,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1264,"width":1404,"focus_rects":[{"x":0,"y":478,"w":1404,"h":786},{"x":140,"y":0,"w":1264,"h":1264},{"x":295,"y":0,"w":1109,"h":1264},{"x":772,"y":0,"w":632,"h":1264},{"x":0,"y":0,"w":1404,"h":1264}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591188952469504"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591248004280320","indices":[154,177],"media_key":"3_1943591248004280320","media_url_https":"https://pbs.twimg.com/media/GvkF8UXacAA6b71.png","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":299,"w":416,"resize":"fit"},"medium":{"h":299,"w":416,"resize":"fit"},"small":{"h":299,"w":416,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":299,"width":416,"focus_rects":[{"x":0,"y":66,"w":416,"h":233},{"x":69,"y":0,"w":299,"h":299},{"x":87,"y":0,"w":262,"h":299},{"x":143,"y":0,"w":150,"h":299},{"x":0,"y":0,"w":416,"h":299}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591248004280320"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591281784971265","indices":[154,177],"media_key":"3_1943591281784971265","media_url_https":"https://pbs.twimg.com/media/GvkF-SNW4AEd9cP.jpg","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":31,"y":376,"h":84,"w":84},{"x":402,"y":485,"h":180,"w":180}]},"medium":{"faces":[{"x":23,"y":290,"h":64,"w":64},{"x":310,"y":374,"h":138,"w":138}]},"small":{"faces":[{"x":13,"y":164,"h":36,"w":36},{"x":175,"y":212,"h":78,"w":78}]},"orig":{"faces":[{"x":31,"y":376,"h":84,"w":84},{"x":402,"y":485,"h":180,"w":180}]}},"sizes":{"large":{"h":1226,"w":1554,"resize":"fit"},"medium":{"h":947,"w":1200,"resize":"fit"},"small":{"h":536,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1226,"width":1554,"focus_rects":[{"x":0,"y":147,"w":1554,"h":870},{"x":0,"y":0,"w":1226,"h":1226},{"x":0,"y":0,"w":1075,"h":1226},{"x":199,"y":0,"w":613,"h":1226},{"x":0,"y":0,"w":1554,"h":1226}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591281784971265"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591154945015808","indices":[154,177],"media_key":"3_1943591154945015808","media_url_https":"https://pbs.twimg.com/media/GvkF25sWwAArEJr.png","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":865,"w":775,"resize":"fit"},"medium":{"h":865,"w":775,"resize":"fit"},"small":{"h":680,"w":609,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":865,"width":775,"focus_rects":[{"x":0,"y":107,"w":775,"h":434},{"x":0,"y":0,"w":775,"h":775},{"x":0,"y":0,"w":759,"h":865},{"x":151,"y":0,"w":433,"h":865},{"x":0,"y":0,"w":775,"h":865}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591154945015808"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591188952469504","indices":[154,177],"media_key":"3_1943591188952469504","media_url_https":"https://pbs.twimg.com/media/GvkF44YXUAAnK_q.jpg","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1264,"w":1404,"resize":"fit"},"medium":{"h":1080,"w":1200,"resize":"fit"},"small":{"h":612,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1264,"width":1404,"focus_rects":[{"x":0,"y":478,"w":1404,"h":786},{"x":140,"y":0,"w":1264,"h":1264},{"x":295,"y":0,"w":1109,"h":1264},{"x":772,"y":0,"w":632,"h":1264},{"x":0,"y":0,"w":1404,"h":1264}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591188952469504"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591248004280320","indices":[154,177],"media_key":"3_1943591248004280320","media_url_https":"https://pbs.twimg.com/media/GvkF8UXacAA6b71.png","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":299,"w":416,"resize":"fit"},"medium":{"h":299,"w":416,"resize":"fit"},"small":{"h":299,"w":416,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":299,"width":416,"focus_rects":[{"x":0,"y":66,"w":416,"h":233},{"x":69,"y":0,"w":299,"h":299},{"x":87,"y":0,"w":262,"h":299},{"x":143,"y":0,"w":150,"h":299},{"x":0,"y":0,"w":416,"h":299}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591248004280320"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591281784971265","indices":[154,177],"media_key":"3_1943591281784971265","media_url_https":"https://pbs.twimg.com/media/GvkF-SNW4AEd9cP.jpg","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":31,"y":376,"h":84,"w":84},{"x":402,"y":485,"h":180,"w":180}]},"medium":{"faces":[{"x":23,"y":290,"h":64,"w":64},{"x":310,"y":374,"h":138,"w":138}]},"small":{"faces":[{"x":13,"y":164,"h":36,"w":36},{"x":175,"y":212,"h":78,"w":78}]},"orig":{"faces":[{"x":31,"y":376,"h":84,"w":84},{"x":402,"y":485,"h":180,"w":180}]}},"sizes":{"large":{"h":1226,"w":1554,"resize":"fit"},"medium":{"h":947,"w":1200,"resize":"fit"},"small":{"h":536,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1226,"width":1554,"focus_rects":[{"x":0,"y":147,"w":1554,"h":870},{"x":0,"y":0,"w":1226,"h":1226},{"x":0,"y":0,"w":1075,"h":1226},{"x":199,"y":0,"w":613,"h":1226},{"x":0,"y":0,"w":1554,"h":1226}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591281784971265"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1943591470562419065","view_count":5608,"bookmark_count":58,"created_at":1752223291000,"favorite_count":44,"quote_count":0,"reply_count":14,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1943591470562419065","full_text":"【 AutoLP 学习笔记 - ③ 】\n\n上一次考虑到单纯频繁的铸造、撤出 LP 存在价格暴跌的无偿风险,那么结合之前我玩过二级量化的经验 (只是小白玩家级别),加入了 MA、RSI、MACD 等指标作为量化因子,来测试一下能否减少价格下跌带来的损失。\n\n▰▰▰▰▰▰\n使用量化因子来判断趋势\n\n目前引入了 MA、RSI、MACD 等指标,订阅池子的 Log 计算出每笔交易的价格,每 30 s 未周期进行采样缓存,达到能够计算指标的数值后来进行积分判断,根据积分强度来判断看涨、看跌、HOLD 。\n\n▰▰▰▰▰▰\n使用趋势来管理 LP 的状态\n\n有了看涨看跌技术指标后,咱们就可以根据趋势情况来管理 LP。\n优先判断当前价格是否在区间内,如果区间内如果是卖出信号也不用变动 LP,如果超出区间了根据信号操作下一个 LP 或者 swap 成稳定币,并且如果没有 LP 的时候 hold 和下跌不做 LP 的信号减少价格下跌带来的损失\n\n整理成表格如下\n效果日志","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}],"ctweets":[{"bookmarked":false,"display_text_range":[0,63],"entities":{"hashtags":[{"indices":[32,36],"text":"蓝鸟会"},{"indices":[37,43],"text":"SNAPS"},{"indices":[44,54],"text":"CookieFun"},{"indices":[55,63],"text":"SparkFi"}],"media":[{"display_url":"pic.x.com/JQ8vIghYnw","expanded_url":"https://x.com/0xmomonifty/status/1928277447880872389/photo/1","id_str":"1928277342159523841","indices":[64,87],"media_key":"3_1928277342159523841","media_url_https":"https://pbs.twimg.com/media/GsKeBrfaUAEM0F4.jpg","type":"photo","url":"https://t.co/JQ8vIghYnw","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":772,"w":1374,"resize":"fit"},"medium":{"h":674,"w":1200,"resize":"fit"},"small":{"h":382,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":772,"width":1374,"focus_rects":[{"x":0,"y":3,"w":1374,"h":769},{"x":0,"y":0,"w":772,"h":772},{"x":0,"y":0,"w":677,"h":772},{"x":47,"y":0,"w":386,"h":772},{"x":0,"y":0,"w":1374,"h":772}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1928277342159523841"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JQ8vIghYnw","expanded_url":"https://x.com/0xmomonifty/status/1928277447880872389/photo/1","id_str":"1928277342159523841","indices":[64,87],"media_key":"3_1928277342159523841","media_url_https":"https://pbs.twimg.com/media/GsKeBrfaUAEM0F4.jpg","type":"photo","url":"https://t.co/JQ8vIghYnw","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":772,"w":1374,"resize":"fit"},"medium":{"h":674,"w":1200,"resize":"fit"},"small":{"h":382,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":772,"width":1374,"focus_rects":[{"x":0,"y":3,"w":1374,"h":769},{"x":0,"y":0,"w":772,"h":772},{"x":0,"y":0,"w":677,"h":772},{"x":47,"y":0,"w":386,"h":772},{"x":0,"y":0,"w":1374,"h":772}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1928277342159523841"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1928277447880872389","view_count":4086,"bookmark_count":1,"created_at":1748572143000,"favorite_count":95,"quote_count":0,"reply_count":104,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1928277447880872389","full_text":"你关我,我关你\n\n一起 Cookies and Spark!\n\n#蓝鸟会 #SNAPS #CookieFun #SparkFi https://t.co/JQ8vIghYnw","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[{"indices":[2047,2053],"text":"steak"},{"indices":[2124,2130],"text":"steak"}],"media":[{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434358492102656","indices":[163,186],"media_key":"3_1929434358492102656","media_url_https":"https://pbs.twimg.com/media/Gsa6U5NbAAAdPz4.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":775,"y":667,"h":127,"w":127}]},"medium":{"faces":[{"x":454,"y":391,"h":74,"w":74}]},"small":{"faces":[{"x":257,"y":221,"h":42,"w":42}]},"orig":{"faces":[{"x":1267,"y":1091,"h":209,"w":209}]}},"sizes":{"large":{"h":1201,"w":2048,"resize":"fit"},"medium":{"h":704,"w":1200,"resize":"fit"},"small":{"h":399,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1962,"width":3346,"focus_rects":[{"x":0,"y":88,"w":3346,"h":1874},{"x":0,"y":0,"w":1962,"h":1962},{"x":58,"y":0,"w":1721,"h":1962},{"x":428,"y":0,"w":981,"h":1962},{"x":0,"y":0,"w":3346,"h":1962}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434358492102656"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434682288119809","indices":[163,186],"media_key":"3_1929434682288119809","media_url_https":"https://pbs.twimg.com/media/Gsa6nvcaIAEZXQS.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":445,"y":259,"h":239,"w":239}]},"medium":{"faces":[{"x":261,"y":152,"h":140,"w":140}]},"small":{"faces":[{"x":148,"y":86,"h":79,"w":79}]},"orig":{"faces":[{"x":451,"y":263,"h":242,"w":242}]}},"sizes":{"large":{"h":1700,"w":2048,"resize":"fit"},"medium":{"h":996,"w":1200,"resize":"fit"},"small":{"h":564,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1720,"width":2072,"focus_rects":[{"x":0,"y":0,"w":2072,"h":1160},{"x":0,"y":0,"w":1720,"h":1720},{"x":0,"y":0,"w":1509,"h":1720},{"x":139,"y":0,"w":860,"h":1720},{"x":0,"y":0,"w":2072,"h":1720}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434682288119809"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434767688445952","indices":[163,186],"media_key":"3_1929434767688445952","media_url_https":"https://pbs.twimg.com/media/Gsa6stlbsAABvWZ.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1166,"w":2048,"resize":"fit"},"medium":{"h":683,"w":1200,"resize":"fit"},"small":{"h":387,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1542,"width":2708,"focus_rects":[{"x":0,"y":0,"w":2708,"h":1516},{"x":0,"y":0,"w":1542,"h":1542},{"x":0,"y":0,"w":1353,"h":1542},{"x":0,"y":0,"w":771,"h":1542},{"x":0,"y":0,"w":2708,"h":1542}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434767688445952"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929435039240220672","indices":[163,186],"media_key":"3_1929435039240220672","media_url_https":"https://pbs.twimg.com/media/Gsa68hMa8AAADc3.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":160,"y":272,"h":271,"w":271}]},"medium":{"faces":[{"x":160,"y":272,"h":271,"w":271}]},"small":{"faces":[{"x":95,"y":163,"h":162,"w":162}]},"orig":{"faces":[{"x":160,"y":272,"h":271,"w":271}]}},"sizes":{"large":{"h":970,"w":1134,"resize":"fit"},"medium":{"h":970,"w":1134,"resize":"fit"},"small":{"h":582,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":970,"width":1134,"focus_rects":[{"x":0,"y":335,"w":1134,"h":635},{"x":0,"y":0,"w":970,"h":970},{"x":0,"y":0,"w":851,"h":970},{"x":69,"y":0,"w":485,"h":970},{"x":0,"y":0,"w":1134,"h":970}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929435039240220672"}}}],"symbols":[{"indices":[1429,1436],"text":"Cookie"},{"indices":[1496,1503],"text":"Cookie"},{"indices":[1600,1605],"text":"USDS"},{"indices":[1612,1619],"text":"Pendle"},{"indices":[2467,2473],"text":"Kaito"}],"timestamps":[],"urls":[{"display_url":"guild.xyz/sparkdotfi","expanded_url":"https://guild.xyz/sparkdotfi","url":"https://t.co/i0RxxEK1Rx","indices":[1954,1977]}],"user_mentions":[{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[40,53]},{"id_str":"1522696492791869445","name":"Kaito AI 🌊","screen_name":"KaitoAI","indices":[57,65]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[40,53]},{"id_str":"1522696492791869445","name":"Kaito AI 🌊","screen_name":"KaitoAI","indices":[57,65]},{"id_str":"1085216475550531585","name":"Aagent.ai","screen_name":"aagentai","indices":[1479,1488]},{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[1527,1538]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434358492102656","indices":[163,186],"media_key":"3_1929434358492102656","media_url_https":"https://pbs.twimg.com/media/Gsa6U5NbAAAdPz4.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":775,"y":667,"h":127,"w":127}]},"medium":{"faces":[{"x":454,"y":391,"h":74,"w":74}]},"small":{"faces":[{"x":257,"y":221,"h":42,"w":42}]},"orig":{"faces":[{"x":1267,"y":1091,"h":209,"w":209}]}},"sizes":{"large":{"h":1201,"w":2048,"resize":"fit"},"medium":{"h":704,"w":1200,"resize":"fit"},"small":{"h":399,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1962,"width":3346,"focus_rects":[{"x":0,"y":88,"w":3346,"h":1874},{"x":0,"y":0,"w":1962,"h":1962},{"x":58,"y":0,"w":1721,"h":1962},{"x":428,"y":0,"w":981,"h":1962},{"x":0,"y":0,"w":3346,"h":1962}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434358492102656"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434682288119809","indices":[163,186],"media_key":"3_1929434682288119809","media_url_https":"https://pbs.twimg.com/media/Gsa6nvcaIAEZXQS.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":445,"y":259,"h":239,"w":239}]},"medium":{"faces":[{"x":261,"y":152,"h":140,"w":140}]},"small":{"faces":[{"x":148,"y":86,"h":79,"w":79}]},"orig":{"faces":[{"x":451,"y":263,"h":242,"w":242}]}},"sizes":{"large":{"h":1700,"w":2048,"resize":"fit"},"medium":{"h":996,"w":1200,"resize":"fit"},"small":{"h":564,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1720,"width":2072,"focus_rects":[{"x":0,"y":0,"w":2072,"h":1160},{"x":0,"y":0,"w":1720,"h":1720},{"x":0,"y":0,"w":1509,"h":1720},{"x":139,"y":0,"w":860,"h":1720},{"x":0,"y":0,"w":2072,"h":1720}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434682288119809"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929434767688445952","indices":[163,186],"media_key":"3_1929434767688445952","media_url_https":"https://pbs.twimg.com/media/Gsa6stlbsAABvWZ.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1166,"w":2048,"resize":"fit"},"medium":{"h":683,"w":1200,"resize":"fit"},"small":{"h":387,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1542,"width":2708,"focus_rects":[{"x":0,"y":0,"w":2708,"h":1516},{"x":0,"y":0,"w":1542,"h":1542},{"x":0,"y":0,"w":1353,"h":1542},{"x":0,"y":0,"w":771,"h":1542},{"x":0,"y":0,"w":2708,"h":1542}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929434767688445952"}}},{"display_url":"pic.x.com/mogFso7XQI","expanded_url":"https://x.com/0xmomonifty/status/1929435806248395228/photo/1","id_str":"1929435039240220672","indices":[163,186],"media_key":"3_1929435039240220672","media_url_https":"https://pbs.twimg.com/media/Gsa68hMa8AAADc3.jpg","type":"photo","url":"https://t.co/mogFso7XQI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":160,"y":272,"h":271,"w":271}]},"medium":{"faces":[{"x":160,"y":272,"h":271,"w":271}]},"small":{"faces":[{"x":95,"y":163,"h":162,"w":162}]},"orig":{"faces":[{"x":160,"y":272,"h":271,"w":271}]}},"sizes":{"large":{"h":970,"w":1134,"resize":"fit"},"medium":{"h":970,"w":1134,"resize":"fit"},"small":{"h":582,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":970,"width":1134,"focus_rects":[{"x":0,"y":335,"w":1134,"h":635},{"x":0,"y":0,"w":970,"h":970},{"x":0,"y":0,"w":851,"h":970},{"x":69,"y":0,"w":485,"h":970},{"x":0,"y":0,"w":1134,"h":970}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929435039240220672"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1929435806248395228","view_count":5287,"bookmark_count":1,"created_at":1748848318000,"favorite_count":89,"quote_count":2,"reply_count":88,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1929435806248395228","full_text":"【互动互关贴 - 在嘴撸的赛道,我们到底应该怎么撸】\n\n在去中心化区块链领域, @cookiedotfun 和 @KaitoAI 的 InfoFi 时代带来了深刻变革。\n\n过去,加密市场信息碎片化严重,优质内容难以凸显。Kaito 和 Cookie 通过 AI 技术与激励机制,重新赋予信息价值。Kaito 的 Yaps 机制依据内容影响力、深度等维度奖励创作者,Cookie 的 Snaps 则侧重内容质量、用户参与情绪等多维社交信号,鼓励用户专注单一项目、长期参与,构建起围绕优质内容的注意力经济体系。\n\n那么如何深度的参与到 InfoFi 当中去,来获得丰厚的回报极为重要。但是现在铺天盖地的“嘴撸”推文,大量同质化、缺乏深度的内容充斥社区,导致信息过载,用户难以获取有价值的信息,且不利于项目以及 InfoFi 的可持续发展。\n\n所以下面以 Momo 个人的想法来展开讲讲如何去精细化深入研究项目背景、技术细节和市场前景,确保内容具有深度和价值,以及饱和式参与交互。\n\n====\n# 细读 & 挖掘 -> 内容输出\n\n每当一个项目有一个特点非常吸引你进行参与时,首先得仔细研读项目的白皮书,理解其核心理念。如 Cookie 聚焦于 X 平台数据,通过低延迟访问实时数据,即时洞察市场动态和社会参与情况,并过情绪分析和忠诚度评分激励内容创作。\n所以我们在文章内容输出时,要为读者提供有价值的信息和独特的视角。当然优先聚焦在热点内容,或者聚焦在自己擅长的细分领域发布专业内容来获得丰厚的流量。一定要避免发布泛泛水文,以及同质化文章。\n\n在深入了解项目的同时得了解其技术架构,Cookie 侧重于情绪分析和忠诚度评分,能够提供针对加密货币的特定智能分析,拥有专有的指标,如智能互动评分,可过滤掉机器人活动。\n所以我们在文章发布的同时,要与相关用户多参与互评,且要多与排行榜、高质量博主进行互动,如果通时得到高权重博主回复就非常加分,务必记住互动内容必须要有价值。\n\n总结重点就是要提高 Mindshare 指标 (用于量化项目或账户在加密生态系统中获得的关注度和参与度) 。\n1. 撰写深度文章,可以从自己的笔记开始,不要水文,同质化文章\n2. 多互动多回复有价值的内容,高权重博主互动非常加分\n\n====\n# 交互 & 质押 -> 深度参与\n\n积极参与生态交互能够通过实际使用,深入了解平台的用户体验、数据质量,并且能够在后期的社区讨论中提出自己的建议和想法。\n\n比如 Cookie 与 Spark (SparkDotFi) 第一个合作项目活动中,我们可以在 Cookie 上参与社区互动,发布与 Spark 相关的内容来赚取 Snaps 积分。同时 Cookie 本身可以进行质押和空投挖矿,Spark 是一个借贷平台,也可以参与参与质押、借贷等。\n\n在 Cookie 中,我们可以质押 Cookie 代币来获得积分,根据积分的数量对应相应的等级。\n\n目前年化以及积分对应为:\n30天:1倍积分,APY: 1.01% \n90天:2倍积分,APY: 3.98% \n180天:3倍积分,APY: 8% \n365天:5倍积分,APY: 12.41%\n\n积分对应等级\n▪︎500:Bronze青铜 \n▪︎5000:Sliver白银 \n▪︎20000:Gold黄金 \n▪︎100000:Platinum铂金 \n▪︎500000:Diamond钻石\n\n在进行 $Cookie 的质押和撸积分之后,我们可以在 Farming 以及后去的活动中获得空投,在前几天\n@aagentai 项目方已经给 $Cookie 的质押着们进行了空投分配!\n\n在 Spark @sparkdotfi 中,我们可以通过质押稳定币 USDC USDS DAI 等,来获得预期空投和实际年化收益。也可以在 Points 中质押 $USDS YT 或者 $Pendle 来获取积分。当然你还可以在他的借贷中借出代币来充分利用自己的资金。\n\n质押代币在目前的 Defi 世界中,以及项目生态不断壮大的路途中是一个不错的选择,毕竟项目方的成长也离不开强大的流动性支撑,项目方也愿意将空投份额留给参与质押者们。当然需根据自己的风险承受能力和投资目标,制定合理的质押策略。\n\n====\n# 交流 & NFT -> 获取身份\n\n在参与项目交互的同时,在交流群组中,积极参与讨论和互动,与其他用户分享信息和观点,也十分的重要。通过 DC 等社交群组中积极参与交流、活动,提升自己在社区中的知名度和影响力,能够获得项目方或者社区极为难得的尊贵身份,能够为以后社交链接空投带来不错的收益。\n\n比如在 Spark 的 DC 中,我们首先需要 Guild (https://t.co/i0RxxEK1Rx) 中做完社交任务 (特别是 1-5-2) 才能在 DC 中发言,在 DC 中多多交流发表自己的看法,即可获得 sparkies 积分。在 #steak 频道输入【\"/daily\"、\"/weekly\"、\"/monthly\" 】来进行签到也可获得积分,当得到 sparkies 积分之后就可以在 #steak 频道输入 /shop 来购买积分角色。当然不同的积分、XP 对应不同的角色,不同的角色也对对应不同的身份、以及未来的收获!\n\n积分对应角色:\n200 -> sparkie Lvl 1\n250 -> sparkie Lvl 2\n300 -> sparkie Lvl 3 \n350 -> sparkie Lvl 4 \n400 -> psparkie Lvl 5 \n\n参与早期 NFT 获取获得项目的早期身份标识的同时也能够因 NFT 的价格大幅增长带来巨额收益。目前许多项目会为早期持有者提供独家的社区访问权和参与权,可以简单的理解为是项目的早期 \"股东\"。\n\n比如之前 Kaito 的 Genesis NFT,不仅项目方进行 TGE 的时候对 NFT 的持有者进行了丰厚的 $Kaito 代币空投,其他项目方也对该持有者进行了特殊空投。并且对 Genesis NFT 的持有者将持续享有生态优先权。\n\n(Kaito Genesis NFT - PFP 都好可爱!)\n\n所以说,在参与 InfoFi 项目的过程中,除了深入了解项目的技术架构和市场前景外,积极参与社区交流和获取身份标识(如 NFT)也是一种极为有效的策略。通过在社区中积极互动、完成社交任务、积累积分,不仅可以提升自己在社区中的知名度和影响力,还能获得项目方或社区赋予的独特身份和权益,这些身份和权益在未来可能会带来可观的收益。\n\n====\n# 总结\n在 InfoFi 项目中,深度参与不仅意味着获取短期的空投收益,更是在加密市场中建立长期个人账号影响力的必经之路。通过深度研究项目背景、技术细节和市场前景,积极参与生态交互,以及通过社区交流和获取身份标识(如 NFT)提升自己的知名度和影响力,可以在 InfoFi 领域的带领下实现自己的价值的最大化。知识是不断积累,财富也是~!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,157],"entities":{"hashtags":[{"indices":[348,356],"text":"SparkFi"},{"indices":[357,364],"text":"Cookie"},{"indices":[365,372],"text":"infofi"},{"indices":[373,379],"text":"SNAPS"},{"indices":[380,385],"text":"DeFi"}],"media":[{"display_url":"pic.x.com/upHHbb7H2f","expanded_url":"https://x.com/0xmomonifty/status/1931001444020474279/photo/1","id_str":"1931000299856216064","indices":[158,181],"media_key":"3_1931000299856216064","media_url_https":"https://pbs.twimg.com/media/GsxKirYaQAAIosf.jpg","type":"photo","url":"https://t.co/upHHbb7H2f","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1262,"w":1628,"resize":"fit"},"medium":{"h":930,"w":1200,"resize":"fit"},"small":{"h":527,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1262,"width":1628,"focus_rects":[{"x":0,"y":0,"w":1628,"h":912},{"x":0,"y":0,"w":1262,"h":1262},{"x":0,"y":0,"w":1107,"h":1262},{"x":0,"y":0,"w":631,"h":1262},{"x":0,"y":0,"w":1628,"h":1262}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1931000299856216064"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[66,79]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[66,79]},{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[322,333]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[334,347]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/upHHbb7H2f","expanded_url":"https://x.com/0xmomonifty/status/1931001444020474279/photo/1","id_str":"1931000299856216064","indices":[158,181],"media_key":"3_1931000299856216064","media_url_https":"https://pbs.twimg.com/media/GsxKirYaQAAIosf.jpg","type":"photo","url":"https://t.co/upHHbb7H2f","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1262,"w":1628,"resize":"fit"},"medium":{"h":930,"w":1200,"resize":"fit"},"small":{"h":527,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1262,"width":1628,"focus_rects":[{"x":0,"y":0,"w":1628,"h":912},{"x":0,"y":0,"w":1262,"h":1262},{"x":0,"y":0,"w":1107,"h":1262},{"x":0,"y":0,"w":631,"h":1262},{"x":0,"y":0,"w":1628,"h":1262}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1931000299856216064"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1931001444020474279","view_count":2677,"bookmark_count":1,"created_at":1749221595000,"favorite_count":81,"quote_count":0,"reply_count":73,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1931001444020474279","full_text":"【 今日互关互动-听说今天 Cookie 加分比以前猛了 】\n\n看了一下排行榜,今天猛一点的都能拿到 SNAPS 32 分了,今早 @cookiedotfun 官方也宣布开始支持除英文外其他语言,包括中文!\n\n这表明了一个好现象, 饼干厂的的 InfoFi 变得越来越公平,我们这些小蓝 V 也能竞争一下喝口汤啦!\n\n当然在InfoFi项目中,深度参与绝非仅仅是为了短期的空投收益,更是构建长期个人影响力的关键路径。\n\n深入钻研项目背景、技术细节与市场前景,积极投身生态互动,借助社区交流及获取身份标识(如NFT)来提升知名度,便能在InfoFi领域引领下,实现个人价值的最大化。记住,知识与财富,皆需日积月累!\n\n一起加油 ! 饼干兄弟们!\n@sparkdotfi\n@cookiedotfun\n#SparkFi #Cookie #infofi #SNAPS #DeFi","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,151],"entities":{"hashtags":[{"indices":[528,535],"text":"COOKIE"},{"indices":[536,541],"text":"SOIL"}],"media":[{"display_url":"pic.x.com/hVnNIEHbyI","expanded_url":"https://x.com/0xmomonifty/status/1929784933851300316/photo/1","id_str":"1929784609321242624","indices":[152,175],"media_key":"3_1929784609321242624","media_url_https":"https://pbs.twimg.com/media/Gsf44LOb0AAzUX5.jpg","type":"photo","url":"https://t.co/hVnNIEHbyI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":655,"w":1583,"resize":"fit"},"medium":{"h":497,"w":1200,"resize":"fit"},"small":{"h":281,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":655,"width":1583,"focus_rects":[{"x":246,"y":0,"w":1170,"h":655},{"x":504,"y":0,"w":655,"h":655},{"x":544,"y":0,"w":575,"h":655},{"x":667,"y":0,"w":328,"h":655},{"x":0,"y":0,"w":1583,"h":655}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929784609321242624"}}}],"symbols":[{"indices":[168,172],"text":"KET"},{"indices":[542,547],"text":"SOIL"}],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[138,151]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[138,151]},{"id_str":"1752118369430482944","name":"Apex 2025","screen_name":"xrplapex","indices":[223,232]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[514,527]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/hVnNIEHbyI","expanded_url":"https://x.com/0xmomonifty/status/1929784933851300316/photo/1","id_str":"1929784609321242624","indices":[152,175],"media_key":"3_1929784609321242624","media_url_https":"https://pbs.twimg.com/media/Gsf44LOb0AAzUX5.jpg","type":"photo","url":"https://t.co/hVnNIEHbyI","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":655,"w":1583,"resize":"fit"},"medium":{"h":497,"w":1200,"resize":"fit"},"small":{"h":281,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":655,"width":1583,"focus_rects":[{"x":246,"y":0,"w":1170,"h":655},{"x":504,"y":0,"w":655,"h":655},{"x":544,"y":0,"w":575,"h":655},{"x":667,"y":0,"w":328,"h":655},{"x":0,"y":0,"w":1583,"h":655}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1929784609321242624"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1929784933851300316","view_count":1174,"bookmark_count":1,"created_at":1748931556000,"favorite_count":44,"quote_count":0,"reply_count":34,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1929784933851300316","full_text":"【 Soil 官方宣布与 Cookie 合作,饼干建设的兄弟们猪脚饭又要来了 】\n\nCookie 作为一个极具潜力的项目,一直以来都备受关注。它不仅拥有庞大的用户基础和强大的社区支持,还不断通过创新和合作拓展自己的生态版图。\n\n此前,已经有 200 多个 Web 3 项目向 @cookiedotfun 抛出了合作的橄榄枝,包括此前的 $KET 要给 SNAPS 的前 25 名发放 5 W 美金的空投,排行榜靠前的大佬都麻了。\n\nSoil 是 @xrplapex 的官方赞助商,它通过将中小企业贷款打包成数字资产,也是最近热火的 RWA 赛道。Soil 是一个基于区块链的借贷协议,它连接了传统金融和加密世界,重塑了中小企业债务和固定收益投资。它是一个债务市场,成熟的公司可以在这里获得融资,而加密投资者可以将他们的稳定币借出,以赚取来自链下真实世界资产的收益。\n\n目前能了解到的信息并不是很多,但是从 Cookie 的热度以及 RWA 的热点项目来说,无疑是强强联合的典范。 Cookie 通过与 Soil 的合作,进一步拓展其在 RWA 赛道的布局,为用户提供更多元化的投资选择。\n\nCookie 的兄弟们一起建设起来!\n@cookiedotfun\n#COOKIE #SOIL $SOIL","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,138],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1945325756294553626","view_count":15089,"bookmark_count":161,"created_at":1752636777000,"favorite_count":111,"quote_count":2,"reply_count":16,"retweet_count":13,"user_id_str":"1744901065886318592","conversation_id_str":"1945325756294553626","full_text":"前端时间沉迷于研究 AutoLP 发现很多东西其实都是之前学过的 Arbitrage 或者 Mev 非常类似 (没有完全成功过),所以准备回去研究一下这让我非常沉迷的玩意,我知道参与 DEX-DEX 是一场军备竞赛,但是他能让我学到非常多关于链上技术的知识,即使需要花钱去玩。\n\n所以接下来我也会将自己看到的学到的分享出来,也希望能够有更多的中文区伙伴讨论进来,毕竟许多这个圈子的社群都是英文大佬,有时候学习和沟通也非常的不方便。\n\n本人小白还在学习路上,内容仅供学习参考,如有问题请积极指出,也非常感谢能够有大佬来指点一二\n\n▰▰▰▰▰▰\n学习入门\n\n我第一次研究三角套利是从 solidquant/mev-templates 开始的,这个示例 Python/Javascript/Rust 三种语言,非常适合有一定 EVM 基础的小伙伴入门,而且在他的 Medium 也能找到好几期关于讨论 MEV 或者 Arbitrage 的文章,非常值得小白系统级入门。\n\n在他的示例中也能够非常清晰的了解到一个套利流程:检索历史所有池子 -> 异步处理计算影响的池子 -> 模拟计算多跳路径 -> 签署交易并创建包或发送到 Flashbots\n\n▰▰▰▰▰▰\n研究方向\n\n池子管理及计算\nV2 原理、V3 的计算,包括多跳中包含 V2V3 转换,如何做到寻找机会更快,套利公式更快更准,让套利空间更加有竞争性。\n这里分享几个框架 dexloom/loom 、darkforestry/amms-rs、0 xKitsune/uniswap-v 3-math,其中 loom 的作者们非常强大,能够将 Defi 套利工具模块化,能够非常高效的来定制自动化策略开发。\n\nGAS 优化\n寻找机会、计算最优利润、构建交易并快速提交以进入 N+1 区块。解决上述难题,最后演变成关于 Gas 的博弈,PGA - Price Gas Auction\n如何在有限的利润中,控制好你的 GAS 成本非常重要,这方面需要深入的学习 Solidity Yul 和 Huff 语言的基础知识,编写出属于自己的绝佳省油丰田合约,使用 Forge 等工具来测量 GAS 使用情况,合约入门前期可看 dexloom/multicaller\n\n基建军备\n一个不断扫描区块链以寻找新的机会,缺少不了一个强有力的 RPC,不管是主链还是策略都需要拥有强大的性能和与验证着足够近的机房,通常公共付费节点拥有严格的速率限制,并且短时间就会耗余额,目前不太会去使用这些。节点客户端的选择也非常重要,主网 Geth 客户端已经非常成熟,但也有像 Reth 或 Revm 这样的高级工具,高度模块化、强大的性能、活跃的社区。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,166],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/Bod4ky2vfY","expanded_url":"https://x.com/0xmomonifty/status/1949292154767237250/photo/1","id_str":"1949125229508526080","indices":[167,190],"media_key":"3_1949125229508526080","media_url_https":"https://pbs.twimg.com/media/GwyvEb-bgAA6Xg6.jpg","type":"photo","url":"https://t.co/Bod4ky2vfY","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1207,"resize":"fit"},"medium":{"h":1200,"w":707,"resize":"fit"},"small":{"h":680,"w":401,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2414,"focus_rects":[{"x":0,"y":652,"w":2414,"h":1352},{"x":0,"y":121,"w":2414,"h":2414},{"x":0,"y":0,"w":2414,"h":2752},{"x":304,"y":0,"w":2048,"h":4096},{"x":0,"y":0,"w":2414,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1949125229508526080"}}},{"display_url":"pic.x.com/Bod4ky2vfY","expanded_url":"https://x.com/0xmomonifty/status/1949292154767237250/photo/1","id_str":"1949125391496720384","indices":[167,190],"media_key":"3_1949125391496720384","media_url_https":"https://pbs.twimg.com/media/GwyvN3bbMAAZB6T.jpg","type":"photo","url":"https://t.co/Bod4ky2vfY","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1265,"resize":"fit"},"medium":{"h":1200,"w":741,"resize":"fit"},"small":{"h":680,"w":420,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2529,"focus_rects":[{"x":0,"y":824,"w":2529,"h":1416},{"x":0,"y":268,"w":2529,"h":2529},{"x":0,"y":91,"w":2529,"h":2883},{"x":0,"y":0,"w":2048,"h":4096},{"x":0,"y":0,"w":2529,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1949125391496720384"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1802308972503797760","name":"cakevm","screen_name":"cakevm","indices":[706,713]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/Bod4ky2vfY","expanded_url":"https://x.com/0xmomonifty/status/1949292154767237250/photo/1","id_str":"1949125229508526080","indices":[167,190],"media_key":"3_1949125229508526080","media_url_https":"https://pbs.twimg.com/media/GwyvEb-bgAA6Xg6.jpg","type":"photo","url":"https://t.co/Bod4ky2vfY","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1207,"resize":"fit"},"medium":{"h":1200,"w":707,"resize":"fit"},"small":{"h":680,"w":401,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2414,"focus_rects":[{"x":0,"y":652,"w":2414,"h":1352},{"x":0,"y":121,"w":2414,"h":2414},{"x":0,"y":0,"w":2414,"h":2752},{"x":304,"y":0,"w":2048,"h":4096},{"x":0,"y":0,"w":2414,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1949125229508526080"}}},{"display_url":"pic.x.com/Bod4ky2vfY","expanded_url":"https://x.com/0xmomonifty/status/1949292154767237250/photo/1","id_str":"1949125391496720384","indices":[167,190],"media_key":"3_1949125391496720384","media_url_https":"https://pbs.twimg.com/media/GwyvN3bbMAAZB6T.jpg","type":"photo","url":"https://t.co/Bod4ky2vfY","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1265,"resize":"fit"},"medium":{"h":1200,"w":741,"resize":"fit"},"small":{"h":680,"w":420,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2529,"focus_rects":[{"x":0,"y":824,"w":2529,"h":1416},{"x":0,"y":268,"w":2529,"h":2529},{"x":0,"y":91,"w":2529,"h":2883},{"x":0,"y":0,"w":2048,"h":4096},{"x":0,"y":0,"w":2529,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1949125391496720384"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1949292154767237250","view_count":32209,"bookmark_count":337,"created_at":1753582440000,"favorite_count":267,"quote_count":3,"reply_count":15,"retweet_count":46,"user_id_str":"1744901065886318592","conversation_id_str":"1949292154767237250","full_text":"【 Arbitrage 学习笔记 - ④ 交换路径 】\n\n在玩 Dex - Dex 套利的时候,计算和管理 Swap 的路径极为复杂,我们在同步获取到 Uniswap 各个交易对 Pool 之后,如何将池子之间路径连接起来形成路径,也是一门需要不断学习探索的步骤,下面是最近几天学习的笔记和资料分享给大家。\n\n▰▰▰▰▰▰\n套利路径\n\nA->B->C->…->A,使用 A 经过一系列池子之间的 Swap 之后能获得到更多的 A,这是我们的最终套利目的。我们把每个池子看成一条边,每条边都有一个起点和一个终点,形成一个环状的有向图,寻找路径就成了解决图问题。条数 hops 即为 Swap 长度,像我小白阶级可以先从 3 跳进行学习。\n目前最常见的 DFS(深度优先搜索),它从一个起始节点开始,沿着当前路径尽可能深地搜索,直到无法继续为止,然后回溯到上一个节点,选择另一条路径继续搜索。当然也有使用二分搜索等方法先确定范围进行求解。\n资料可参考 ccyanxyz/uniswap-arbitrage-analysis \n\n更高层次的可以按照价格 > 状态匹配度>路径条件进行排序,或者叠加更多因素进行凸面求解,最后算出来的路径进行交易。\n参考 advock/CFMM-Convex-Optimization- \n\n▰▰▰▰▰▰\n路径管理\n\n我们在根据自己喜好(比如我前期对池子大小进行筛选)进行过滤 Pool 后形成了许多数量的路径,但是众多池子鱼龙混杂,我们还需要一个 manager 来管理控制我们的路径数据库,进行黑白名单状态控制和交易对的快速查找。\n这里介绍一位在性能优化方面追求极致且极为出色的大佬 @cakevm 的 cakevm/swap-path。他也是 Loom 项目的重要贡献者,在群里,他非常热情且专业地解答大家的疑问,是我的崇拜对象。\n在这个项目中使用了 DashMap ,采用 DFS 计算多跳路径,可以非常方便快速的管理和查找池子和 Path,流程:新池加入 → 更新图结构 → DFS 查找所有可达路径 → 存储路径。\n\n以上均为个人笔记,理解可能存在问题,也非常感谢能够有大佬来指点一二","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,153],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591154945015808","indices":[154,177],"media_key":"3_1943591154945015808","media_url_https":"https://pbs.twimg.com/media/GvkF25sWwAArEJr.png","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":865,"w":775,"resize":"fit"},"medium":{"h":865,"w":775,"resize":"fit"},"small":{"h":680,"w":609,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":865,"width":775,"focus_rects":[{"x":0,"y":107,"w":775,"h":434},{"x":0,"y":0,"w":775,"h":775},{"x":0,"y":0,"w":759,"h":865},{"x":151,"y":0,"w":433,"h":865},{"x":0,"y":0,"w":775,"h":865}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591154945015808"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591188952469504","indices":[154,177],"media_key":"3_1943591188952469504","media_url_https":"https://pbs.twimg.com/media/GvkF44YXUAAnK_q.jpg","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1264,"w":1404,"resize":"fit"},"medium":{"h":1080,"w":1200,"resize":"fit"},"small":{"h":612,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1264,"width":1404,"focus_rects":[{"x":0,"y":478,"w":1404,"h":786},{"x":140,"y":0,"w":1264,"h":1264},{"x":295,"y":0,"w":1109,"h":1264},{"x":772,"y":0,"w":632,"h":1264},{"x":0,"y":0,"w":1404,"h":1264}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591188952469504"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591248004280320","indices":[154,177],"media_key":"3_1943591248004280320","media_url_https":"https://pbs.twimg.com/media/GvkF8UXacAA6b71.png","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":299,"w":416,"resize":"fit"},"medium":{"h":299,"w":416,"resize":"fit"},"small":{"h":299,"w":416,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":299,"width":416,"focus_rects":[{"x":0,"y":66,"w":416,"h":233},{"x":69,"y":0,"w":299,"h":299},{"x":87,"y":0,"w":262,"h":299},{"x":143,"y":0,"w":150,"h":299},{"x":0,"y":0,"w":416,"h":299}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591248004280320"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591281784971265","indices":[154,177],"media_key":"3_1943591281784971265","media_url_https":"https://pbs.twimg.com/media/GvkF-SNW4AEd9cP.jpg","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":31,"y":376,"h":84,"w":84},{"x":402,"y":485,"h":180,"w":180}]},"medium":{"faces":[{"x":23,"y":290,"h":64,"w":64},{"x":310,"y":374,"h":138,"w":138}]},"small":{"faces":[{"x":13,"y":164,"h":36,"w":36},{"x":175,"y":212,"h":78,"w":78}]},"orig":{"faces":[{"x":31,"y":376,"h":84,"w":84},{"x":402,"y":485,"h":180,"w":180}]}},"sizes":{"large":{"h":1226,"w":1554,"resize":"fit"},"medium":{"h":947,"w":1200,"resize":"fit"},"small":{"h":536,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1226,"width":1554,"focus_rects":[{"x":0,"y":147,"w":1554,"h":870},{"x":0,"y":0,"w":1226,"h":1226},{"x":0,"y":0,"w":1075,"h":1226},{"x":199,"y":0,"w":613,"h":1226},{"x":0,"y":0,"w":1554,"h":1226}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591281784971265"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591154945015808","indices":[154,177],"media_key":"3_1943591154945015808","media_url_https":"https://pbs.twimg.com/media/GvkF25sWwAArEJr.png","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":865,"w":775,"resize":"fit"},"medium":{"h":865,"w":775,"resize":"fit"},"small":{"h":680,"w":609,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":865,"width":775,"focus_rects":[{"x":0,"y":107,"w":775,"h":434},{"x":0,"y":0,"w":775,"h":775},{"x":0,"y":0,"w":759,"h":865},{"x":151,"y":0,"w":433,"h":865},{"x":0,"y":0,"w":775,"h":865}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591154945015808"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591188952469504","indices":[154,177],"media_key":"3_1943591188952469504","media_url_https":"https://pbs.twimg.com/media/GvkF44YXUAAnK_q.jpg","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1264,"w":1404,"resize":"fit"},"medium":{"h":1080,"w":1200,"resize":"fit"},"small":{"h":612,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1264,"width":1404,"focus_rects":[{"x":0,"y":478,"w":1404,"h":786},{"x":140,"y":0,"w":1264,"h":1264},{"x":295,"y":0,"w":1109,"h":1264},{"x":772,"y":0,"w":632,"h":1264},{"x":0,"y":0,"w":1404,"h":1264}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591188952469504"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591248004280320","indices":[154,177],"media_key":"3_1943591248004280320","media_url_https":"https://pbs.twimg.com/media/GvkF8UXacAA6b71.png","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":299,"w":416,"resize":"fit"},"medium":{"h":299,"w":416,"resize":"fit"},"small":{"h":299,"w":416,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":299,"width":416,"focus_rects":[{"x":0,"y":66,"w":416,"h":233},{"x":69,"y":0,"w":299,"h":299},{"x":87,"y":0,"w":262,"h":299},{"x":143,"y":0,"w":150,"h":299},{"x":0,"y":0,"w":416,"h":299}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591248004280320"}}},{"display_url":"pic.x.com/WfGOkyQ5h4","expanded_url":"https://x.com/0xmomonifty/status/1943591470562419065/photo/1","id_str":"1943591281784971265","indices":[154,177],"media_key":"3_1943591281784971265","media_url_https":"https://pbs.twimg.com/media/GvkF-SNW4AEd9cP.jpg","type":"photo","url":"https://t.co/WfGOkyQ5h4","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":31,"y":376,"h":84,"w":84},{"x":402,"y":485,"h":180,"w":180}]},"medium":{"faces":[{"x":23,"y":290,"h":64,"w":64},{"x":310,"y":374,"h":138,"w":138}]},"small":{"faces":[{"x":13,"y":164,"h":36,"w":36},{"x":175,"y":212,"h":78,"w":78}]},"orig":{"faces":[{"x":31,"y":376,"h":84,"w":84},{"x":402,"y":485,"h":180,"w":180}]}},"sizes":{"large":{"h":1226,"w":1554,"resize":"fit"},"medium":{"h":947,"w":1200,"resize":"fit"},"small":{"h":536,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1226,"width":1554,"focus_rects":[{"x":0,"y":147,"w":1554,"h":870},{"x":0,"y":0,"w":1226,"h":1226},{"x":0,"y":0,"w":1075,"h":1226},{"x":199,"y":0,"w":613,"h":1226},{"x":0,"y":0,"w":1554,"h":1226}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1943591281784971265"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1943591470562419065","view_count":5608,"bookmark_count":58,"created_at":1752223291000,"favorite_count":44,"quote_count":0,"reply_count":14,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1943591470562419065","full_text":"【 AutoLP 学习笔记 - ③ 】\n\n上一次考虑到单纯频繁的铸造、撤出 LP 存在价格暴跌的无偿风险,那么结合之前我玩过二级量化的经验 (只是小白玩家级别),加入了 MA、RSI、MACD 等指标作为量化因子,来测试一下能否减少价格下跌带来的损失。\n\n▰▰▰▰▰▰\n使用量化因子来判断趋势\n\n目前引入了 MA、RSI、MACD 等指标,订阅池子的 Log 计算出每笔交易的价格,每 30 s 未周期进行采样缓存,达到能够计算指标的数值后来进行积分判断,根据积分强度来判断看涨、看跌、HOLD 。\n\n▰▰▰▰▰▰\n使用趋势来管理 LP 的状态\n\n有了看涨看跌技术指标后,咱们就可以根据趋势情况来管理 LP。\n优先判断当前价格是否在区间内,如果区间内如果是卖出信号也不用变动 LP,如果超出区间了根据信号操作下一个 LP 或者 swap 成稳定币,并且如果没有 LP 的时候 hold 和下跌不做 LP 的信号减少价格下跌带来的损失\n\n整理成表格如下\n效果日志","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,168],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/HiCXV5gcE5","expanded_url":"https://x.com/0xmomonifty/status/1964326886336844143/photo/1","id_str":"1964326576117731333","indices":[169,192],"media_key":"3_1964326576117731333","media_url_https":"https://pbs.twimg.com/media/G0KwnRBbUAU7b7z.jpg","type":"photo","url":"https://t.co/HiCXV5gcE5","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1008,"resize":"fit"},"medium":{"h":1200,"w":590,"resize":"fit"},"small":{"h":680,"w":335,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2015,"focus_rects":[{"x":0,"y":1791,"w":2015,"h":1128},{"x":0,"y":1348,"w":2015,"h":2015},{"x":0,"y":1207,"w":2015,"h":2297},{"x":0,"y":66,"w":2015,"h":4030},{"x":0,"y":0,"w":2015,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1964326576117731333"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/HiCXV5gcE5","expanded_url":"https://x.com/0xmomonifty/status/1964326886336844143/photo/1","id_str":"1964326576117731333","indices":[169,192],"media_key":"3_1964326576117731333","media_url_https":"https://pbs.twimg.com/media/G0KwnRBbUAU7b7z.jpg","type":"photo","url":"https://t.co/HiCXV5gcE5","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1008,"resize":"fit"},"medium":{"h":1200,"w":590,"resize":"fit"},"small":{"h":680,"w":335,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":2015,"focus_rects":[{"x":0,"y":1791,"w":2015,"h":1128},{"x":0,"y":1348,"w":2015,"h":2015},{"x":0,"y":1207,"w":2015,"h":2297},{"x":0,"y":66,"w":2015,"h":4030},{"x":0,"y":0,"w":2015,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1964326576117731333"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1964326886336844143","view_count":19327,"bookmark_count":205,"created_at":1757166999000,"favorite_count":189,"quote_count":1,"reply_count":12,"retweet_count":35,"user_id_str":"1744901065886318592","conversation_id_str":"1964326886336844143","full_text":"【 Arbitrage 学习笔记 - ⑥ 链上交易合约 】\n\n在寻找到有利润的套利路径之后,就是收尾将可获利交易提交到链上的部分了。这一步根据自己程序的逻辑习惯可以有很多方法,比如直接将 Pancake 和 Uniswap 的 Swap 接口打包进合约后调用,也可以在此基础上增加使用 Assembly 内联汇编方式将 calldata 需要按特定字节偏移量分段读取数据,进阶了可以使用 Huff 之类的低级类汇编语言来编写自己的逻辑极致节省 GAS,也是一个非常值得深入学习的挑战。\n\n到这一步其实基本流程已经跑通了,同步池子 - 构建路径 - 价格计算 - 寻找最优金额 - 交易上链,可以减少利润预期或者无视 Gas 成本或者负利润的进行一下上链通关。\n后续 Dex 套利我会逐步深入的学习一些知识,优化好每一步骤的细节,有时间过程也会写成内容分享给大家,当然内容可能会理解有误,欢迎大佬们指点分享。\n\n合约这一步 Momo 直接整合上了 Assembly 和闪电贷,所以跟我一样入门的小伙伴也可以尝试参考 solidquant/mev-templates 里面的 contracts ,将 amountIn、useLoan(闪电贷模式) 、loanPool(借贷池子)、第一跳的 router 、第一跳的 tokenIn、第一跳的 tokenOut 、第二跳的 router … \n根据 useLoan 进行闪电贷协议选择或者直接交易,使用 assembly 拆分好后面重复的多跳交换路径,其每三组地址即为一跳数据,长度就是条数 nhop。\n再根据路由地址执行相应协议的交换,最后可以 require (finalAmount >= repayAmount) 进行盈利检查,确保套利后的金额能覆盖闪电贷本金+手续费。\n这里需要特别注意的是,solidquant/mev-templates 的示例合约仅供参考,有授权漏洞,小伙伴入门的时候也要注意权限控制,比如授权、提款等操作,可以用 AI 来过一遍安全监测,毕竟也是资金交易的环节,合约安全即资金安全!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,150],"entities":{"hashtags":[{"indices":[512,520],"text":"SparkFi"}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[4,15]},{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[4,15]},{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[344,355]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[486,499]},{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[500,511]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1927982532387295681","view_count":447,"bookmark_count":0,"created_at":1748501830000,"favorite_count":21,"quote_count":0,"reply_count":12,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1927982532387295681","full_text":"【 卷 @sparkdotfi 的 SNAPS 邀请也非常重要】\n\n在 Sparkfi 的世界里,积分(SNAPS)是衡量你对Spark生态贡献的重要指标,也是获取奖励的关键。而邀请机制则是获取更多 SNAPS 、加速你的 Spark 之旅并冲刺排行榜的有效途径之一。\n\n✨解锁邀请权限:达到10个 SNAPS,即可解锁邀请权限,分享专属链接邀请新用户。\n✨团队奖励:被邀请者每发布一个 SNAPS,你将获得10%的奖励。\n\n在团队也就是受你邀请的用户接下来的互动也非常重要,需要鼓励团队成员点赞、评论彼此的SNAPS,专注于Sparkfi相关内容,避免同时推广多个项目。\n\n当然也可以在自己多个社区之间进行互动,互相之间多发表有质量的回复,也十分有助于分数的提高。\n\nSparkFi @sparkdotfi 是基于 Base 区块链的全新 DeFi 协议,专注于稳定币储蓄、去中心化借贷和智能流动性管理。它通过创新机制如隔离借贷、效率模式(eMode)和利率地板价,为用户提供高效、透明的收益平台。无论是新手还是资深玩家,SparkFi 都值得一试!🔗 了解更多 \n\n@cookiedotfun\n@sparkdotfi\n#SparkFi","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,189],"entities":{"hashtags":[{"indices":[473,477],"text":"蓝鸟会"}],"media":[{"display_url":"pic.x.com/G53ZU8jhCv","expanded_url":"https://x.com/0xmomonifty/status/1930270252123963427/photo/1","id_str":"1930269806730850305","indices":[190,213],"media_key":"3_1930269806730850305","media_url_https":"https://pbs.twimg.com/media/GsmyKYbasAEyKfm.jpg","type":"photo","url":"https://t.co/G53ZU8jhCv","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":86,"y":721,"h":39,"w":39}]},"medium":{"faces":[{"x":86,"y":721,"h":39,"w":39}]},"small":{"faces":[{"x":63,"y":532,"h":28,"w":28}]},"orig":{"faces":[{"x":86,"y":721,"h":39,"w":39}]}},"sizes":{"large":{"h":920,"w":782,"resize":"fit"},"medium":{"h":920,"w":782,"resize":"fit"},"small":{"h":680,"w":578,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":920,"width":782,"focus_rects":[{"x":0,"y":0,"w":782,"h":438},{"x":0,"y":0,"w":782,"h":782},{"x":0,"y":0,"w":782,"h":891},{"x":69,"y":0,"w":460,"h":920},{"x":0,"y":0,"w":782,"h":920}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1930269806730850305"}}}],"symbols":[{"indices":[219,226],"text":"COOKIE"},{"indices":[380,384],"text":"KET"}],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1438365197505232902","name":"Virtuals Protocol","screen_name":"virtuals_io","indices":[5,17]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[20,33]},{"id_str":"1438365197505232902","name":"Virtuals Protocol","screen_name":"virtuals_io","indices":[5,17]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[20,33]},{"id_str":"1207019158791229440","name":"鸟哥 | 蓝鸟会🕊️","screen_name":"NFTCPS","indices":[248,255]},{"id_str":"1624370752446435330","name":"纪正光 Zhengguang Ji $M|🐜","screen_name":"Jizhengguang","indices":[262,275]},{"id_str":"1757553204747972608","name":"Somnia","screen_name":"Somnia_Network","indices":[358,373]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/G53ZU8jhCv","expanded_url":"https://x.com/0xmomonifty/status/1930270252123963427/photo/1","id_str":"1930269806730850305","indices":[190,213],"media_key":"3_1930269806730850305","media_url_https":"https://pbs.twimg.com/media/GsmyKYbasAEyKfm.jpg","type":"photo","url":"https://t.co/G53ZU8jhCv","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":86,"y":721,"h":39,"w":39}]},"medium":{"faces":[{"x":86,"y":721,"h":39,"w":39}]},"small":{"faces":[{"x":63,"y":532,"h":28,"w":28}]},"orig":{"faces":[{"x":86,"y":721,"h":39,"w":39}]}},"sizes":{"large":{"h":920,"w":782,"resize":"fit"},"medium":{"h":920,"w":782,"resize":"fit"},"small":{"h":680,"w":578,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":920,"width":782,"focus_rects":[{"x":0,"y":0,"w":782,"h":438},{"x":0,"y":0,"w":782,"h":782},{"x":0,"y":0,"w":782,"h":891},{"x":69,"y":0,"w":460,"h":920},{"x":0,"y":0,"w":782,"h":920}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1930269806730850305"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1930270252123963427","view_count":502,"bookmark_count":0,"created_at":1749047265000,"favorite_count":14,"quote_count":0,"reply_count":11,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1930270252123963427","full_text":"昨晚看到 @virtuals_io 和 @cookiedotfun 一起开 Space,这难道是 InfoFi 赛道要强强联手了吗?\n\n之前我也写过 Virtuals,Virtuals 是一个基于区块链技术的 AI 代理生成平台,在其平台上,每个AI代理通过 ERC-20 代币实现资产化。\n\n如果 Virtuals 和 Cookie 联合,AI + 嘴撸天梯,不得了不得了!\n\n晚些时候我又看到消息说官推要给 OG 徽章持有者来分发 $COOKIE 代币,不过从今天的情况来看,我们的董事长 @NFTCPS 还有纪总 @Jizhengguang 都没有拿到,看来条件是相当苛刻,但是我觉得不必灰心,继续做我们饼干厂的厂长,也建议项目方还是把范围放大一些,像我们这些小散能吃个猪脚饭效果也会非常不错。\n\n现在 @Somnia_Network 包括之前的 $KET 卷心智榜单前 25 非常的激烈,我觉得项目方还是能够分散代币分发,把甜头给到更多的人才能持续性发展。希望能够成为链上的 Alpha!\n\n饼干兄弟们,我们一起努力,一起加油!\n\n#蓝鸟会","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,209],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/Iq28EbonkP","expanded_url":"https://x.com/0xmomonifty/status/1927553730141974625/photo/1","id_str":"1927551981041696768","indices":[210,233],"media_key":"3_1927551981041696768","media_url_https":"https://pbs.twimg.com/media/GsAKUGwXQAA468a.png","type":"photo","url":"https://t.co/Iq28EbonkP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":422,"y":163,"h":92,"w":92},{"x":23,"y":164,"h":88,"w":88},{"x":70,"y":165,"h":86,"w":86}]},"medium":{"faces":[{"x":422,"y":163,"h":92,"w":92},{"x":23,"y":164,"h":88,"w":88},{"x":70,"y":165,"h":86,"w":86}]},"small":{"faces":[{"x":337,"y":130,"h":73,"w":73},{"x":18,"y":131,"h":70,"w":70},{"x":56,"y":132,"h":68,"w":68}]},"orig":{"faces":[{"x":422,"y":163,"h":92,"w":92},{"x":23,"y":164,"h":88,"w":88},{"x":70,"y":165,"h":86,"w":86}]}},"sizes":{"large":{"h":489,"w":850,"resize":"fit"},"medium":{"h":489,"w":850,"resize":"fit"},"small":{"h":391,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":489,"width":850,"focus_rects":[{"x":0,"y":0,"w":850,"h":476},{"x":0,"y":0,"w":489,"h":489},{"x":0,"y":0,"w":429,"h":489},{"x":0,"y":0,"w":245,"h":489},{"x":0,"y":0,"w":850,"h":489}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1927551981041696768"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"app.spark.fi/points/QRNOJ6","expanded_url":"https://app.spark.fi/points/QRNOJ6","url":"https://t.co/WUqUvQVHV5","indices":[70,93]},{"display_url":"app.spark.fi/points/QRNOJ6","expanded_url":"https://app.spark.fi/points/QRNOJ6","url":"https://t.co/Zvb11eWCbV","indices":[70,93]}],"user_mentions":[{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[23,34]},{"id_str":"1621178567781679105","name":"Spark","screen_name":"sparkdotfi","indices":[23,34]},{"id_str":"1762471547485184000","name":"Cookie DAO 🍪","screen_name":"cookiedotfun","indices":[287,300]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/Iq28EbonkP","expanded_url":"https://x.com/0xmomonifty/status/1927553730141974625/photo/1","id_str":"1927551981041696768","indices":[210,233],"media_key":"3_1927551981041696768","media_url_https":"https://pbs.twimg.com/media/GsAKUGwXQAA468a.png","type":"photo","url":"https://t.co/Iq28EbonkP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":422,"y":163,"h":92,"w":92},{"x":23,"y":164,"h":88,"w":88},{"x":70,"y":165,"h":86,"w":86}]},"medium":{"faces":[{"x":422,"y":163,"h":92,"w":92},{"x":23,"y":164,"h":88,"w":88},{"x":70,"y":165,"h":86,"w":86}]},"small":{"faces":[{"x":337,"y":130,"h":73,"w":73},{"x":18,"y":131,"h":70,"w":70},{"x":56,"y":132,"h":68,"w":68}]},"orig":{"faces":[{"x":422,"y":163,"h":92,"w":92},{"x":23,"y":164,"h":88,"w":88},{"x":70,"y":165,"h":86,"w":86}]}},"sizes":{"large":{"h":489,"w":850,"resize":"fit"},"medium":{"h":489,"w":850,"resize":"fit"},"small":{"h":391,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":489,"width":850,"focus_rects":[{"x":0,"y":0,"w":850,"h":476},{"x":0,"y":0,"w":489,"h":489},{"x":0,"y":0,"w":429,"h":489},{"x":0,"y":0,"w":245,"h":489},{"x":0,"y":0,"w":850,"h":489}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1927551981041696768"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1927553730141974625","view_count":517,"bookmark_count":0,"created_at":1748399596000,"favorite_count":14,"quote_count":0,"reply_count":10,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1927553730141974625","full_text":"【 我的 Spark 也破 0 啦 】\n\n在 @sparkdotfi 上除了嘴撸其实还可以坐下面几个内容\n\n1⃣ 在 Spark 进行存款 https://t.co/Zvb11eWCbV\n\n2⃣ 在 DC 进行卷身份\nSpark Initiate(紫色)\nSparkie(黄色)\nSpark Crew(蓝色)\n也可以再在『bot-commands』频道发送 /daily、/weekly、/monthly 进行积分获取\n\n所以除了在 X 上进行内容创作之外,也可以在多在 DC 进行身份的获取,目前中文频道也非常的卷,屏幕滚动速度飞快,需要在这一波获利的得加油卷起来啦!\n\n@cookiedotfun","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/TveMkxXE37","expanded_url":"https://x.com/0xmomonifty/status/1940936094402461742/photo/1","id_str":"1940784521227739136","indices":[163,186],"media_key":"3_1940784521227739136","media_url_https":"https://pbs.twimg.com/media/Gu8NPUVbIAApEQM.png","type":"photo","url":"https://t.co/TveMkxXE37","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1066,"w":1018,"resize":"fit"},"medium":{"h":1066,"w":1018,"resize":"fit"},"small":{"h":680,"w":649,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1066,"width":1018,"focus_rects":[{"x":0,"y":496,"w":1018,"h":570},{"x":0,"y":48,"w":1018,"h":1018},{"x":0,"y":0,"w":935,"h":1066},{"x":186,"y":0,"w":533,"h":1066},{"x":0,"y":0,"w":1018,"h":1066}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1940784521227739136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/TveMkxXE37","expanded_url":"https://x.com/0xmomonifty/status/1940936094402461742/photo/1","id_str":"1940784521227739136","indices":[163,186],"media_key":"3_1940784521227739136","media_url_https":"https://pbs.twimg.com/media/Gu8NPUVbIAApEQM.png","type":"photo","url":"https://t.co/TveMkxXE37","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1066,"w":1018,"resize":"fit"},"medium":{"h":1066,"w":1018,"resize":"fit"},"small":{"h":680,"w":649,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1066,"width":1018,"focus_rects":[{"x":0,"y":496,"w":1018,"h":570},{"x":0,"y":48,"w":1018,"h":1018},{"x":0,"y":0,"w":935,"h":1066},{"x":186,"y":0,"w":533,"h":1066},{"x":0,"y":0,"w":1018,"h":1066}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1940784521227739136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1940936094402461742","view_count":1032,"bookmark_count":9,"created_at":1751590200000,"favorite_count":19,"quote_count":0,"reply_count":9,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1940936094402461742","full_text":"【 AutoLP 学习笔记 - ①】\n\n前言:想要写一个 V3 LP 的自动化 Bot,那就从今天开始吧!我把它叫 AutoLP!\n\n▰▰▰▰▰▰\n编程语言的选择\n\n我在工作中一般以 Python 为主,它十分的灵活配合 AI 能够实现想法的速通。公司的项目通常以 Java 写,虽然成熟稳定可靠,但是我还是觉得非常的啰嗦。\n但是来到了 Web3 就选择目前区块链最热门的 Rust,安全和性能是它的优势,并且 Polkadot、Solana、Substrate 等都是由 Rust 来构建,在 EVM 和链上玩家领域,也有丰富的框架如:Revm、Reth、Alloy 等,性能也非常炸裂。( 边学习边 Code 了)\n\n▰▰▰▰▰▰\n链上分析和监听框架\n\nMomo 这次 AutoLP 主要在 EVM 链进行研究(主要是 Solana 搭建节点成本太贵哈哈哈),所以区块链基础、EVM 工作原理、Solidity 等就不赘述了。\n\n链上分析和监听其动作主要是在不断的收集新的区块以及交易,然后将它们转换为内部事件,通过不断的计算(比如池子的状态,代币对币价等)达到自己设定的目的后来执行相关的操作如提交交易或者其他链下动作。\n\n在专业一些就是把它分成三个部分:Collectors(收集器)、Strategies(策略)、Executors(执行器)。\n\n- 收集器:收集器接收外部事件(如待处理的交易、新区块、市场订单等),并将它们转换为内部事件\n- 策略:它接收事件作为输入,并计算是否存在任何机会(例如,一个策略可能会监听市场订单流,以查看是否存在跨交易所套利)\n- 执行器:执行器处理操作,并负责在不同环境中执行想要达到的操作(例如提交交易、发布链下订单等)\n\n在 Rust 中我们可以使用 Paradigm 的 Artemis 框架来入门学习和编写(对!就是那个大名鼎鼎的技术投资公司 Paradigm)。\nArtemis 是一个用 Rust 编写 MEV 挖矿机器人的框架,它能够非常明确的指引我们去设计自己的链上监听、分析程序,也非常适合我这次来学习自动区间池子 LP BOT (我以后叫他 AutoLP) 。\n不过这个库上一次更新已经是 2 年前了,想要跟上脚步就得用到最新的 alloy (类似于 js 的 etherjs、python 的 web 3)。\n\n2025-07-03","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,146],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/AJsNgWlsBF","expanded_url":"https://x.com/0xmomonifty/status/1945760400454439151/photo/1","id_str":"1945759424422858752","indices":[147,170],"media_key":"3_1945759424422858752","media_url_https":"https://pbs.twimg.com/media/GwC54y8X0AAOJvF.png","type":"photo","url":"https://t.co/AJsNgWlsBF","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":233,"w":315,"resize":"fit"},"medium":{"h":233,"w":315,"resize":"fit"},"small":{"h":233,"w":315,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":233,"width":315,"focus_rects":[{"x":0,"y":57,"w":315,"h":176},{"x":0,"y":0,"w":233,"h":233},{"x":0,"y":0,"w":204,"h":233},{"x":28,"y":0,"w":117,"h":233},{"x":0,"y":0,"w":315,"h":233}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1945759424422858752"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[647,655]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/AJsNgWlsBF","expanded_url":"https://x.com/0xmomonifty/status/1945760400454439151/photo/1","id_str":"1945759424422858752","indices":[147,170],"media_key":"3_1945759424422858752","media_url_https":"https://pbs.twimg.com/media/GwC54y8X0AAOJvF.png","type":"photo","url":"https://t.co/AJsNgWlsBF","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":233,"w":315,"resize":"fit"},"medium":{"h":233,"w":315,"resize":"fit"},"small":{"h":233,"w":315,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":233,"width":315,"focus_rects":[{"x":0,"y":57,"w":315,"h":176},{"x":0,"y":0,"w":233,"h":233},{"x":0,"y":0,"w":204,"h":233},{"x":28,"y":0,"w":117,"h":233},{"x":0,"y":0,"w":315,"h":233}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1945759424422858752"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1945760400454439151","view_count":14621,"bookmark_count":143,"created_at":1752740404000,"favorite_count":119,"quote_count":2,"reply_count":9,"retweet_count":11,"user_id_str":"1744901065886318592","conversation_id_str":"1945760400454439151","full_text":"【 Arbitrage 学习笔记 - ② 同步池子 】\n\n在套利与 MEV 池子的基础数据是关键的起点,我们需要从区块链这个强大的数据库中把需要用到的各种协议池子的基础数据拿到手,已便后续路径以及利润的计算等。\n\n今天重新复习了一下这个最初的开始\n\n▰▰▰▰▰▰\n节点的选择\n\n在后期 BOT 的运行过程中,需要的大部分都是以实时或者最近几个区块数据,所以像 ETH、BSC 等 EVM 链只需跑 Full 之类的裁剪节点即可。第一次同步池子需要从早期区块开始,但是也就最初几次获取历史池子信息,直接使用免费额度的 infura、alchemy 等,同步后用 csv 或者自己喜欢的数据库存起来,大大可以减少自己的节点性能配置,除非经常需要历史数据回溯。\n\n▰▰▰▰▰▰\n池子同步\n\n最常见的 AMM 模型 Uni、Pancake v2v3 池子最初同步时保存合约地址、token0 地址名字精度、\nToken1 地址名字精度、费率即可。步骤为先用工厂合约(factory)地址和“池子创建事件”的签名,分批查询区块链的事件日志(logs),再从这些事件中解析出所有池子创建的合约地址,最后再批量同步每个池子的详细信息和状态。\n\n工厂合约在各个协议的文档中可以找到,可以直接 google 搜索如 \"pancakeswap doc\",找到 Factory Contract address 就可以看到所有链部署的地址。\n\n方法这里可以参照大佬写的 darkforestry/amms-rs,和 @rnmumu3 梦哥推荐过的 Zacholme7/PoolSync 非常的不错\n\n总体来说这部分还算简单,就是分批次去解析工厂合约创建池子的 Log,与大部分新土狗监控差不多,之前也有写过 Four meme 内盘聪明钱监控也是一样的步骤(不断 filter 新区块包含这些地址的的 log ,如果短时间内交易聪敏钱包 >3 就进行 TG 推送).","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,173],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/VkKtsCvz4u","expanded_url":"https://x.com/0xmomonifty/status/1947181136234569866/photo/1","id_str":"1947180609136369664","indices":[174,197],"media_key":"3_1947180609136369664","media_url_https":"https://pbs.twimg.com/media/GwXGcokaIAARK_k.png","type":"photo","url":"https://t.co/VkKtsCvz4u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1584,"w":2048,"resize":"fit"},"medium":{"h":928,"w":1200,"resize":"fit"},"small":{"h":526,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1632,"width":2110,"focus_rects":[{"x":0,"y":409,"w":2110,"h":1182},{"x":478,"y":0,"w":1632,"h":1632},{"x":600,"y":0,"w":1432,"h":1632},{"x":908,"y":0,"w":816,"h":1632},{"x":0,"y":0,"w":2110,"h":1632}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1947180609136369664"}}},{"display_url":"pic.x.com/VkKtsCvz4u","expanded_url":"https://x.com/0xmomonifty/status/1947181136234569866/photo/1","id_str":"1947180706146209792","indices":[174,197],"media_key":"3_1947180706146209792","media_url_https":"https://pbs.twimg.com/media/GwXGiR9W0AAOqoT.png","type":"photo","url":"https://t.co/VkKtsCvz4u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":714,"w":891,"resize":"fit"},"medium":{"h":714,"w":891,"resize":"fit"},"small":{"h":545,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":714,"width":891,"focus_rects":[{"x":0,"y":215,"w":891,"h":499},{"x":0,"y":0,"w":714,"h":714},{"x":21,"y":0,"w":626,"h":714},{"x":156,"y":0,"w":357,"h":714},{"x":0,"y":0,"w":891,"h":714}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1947180706146209792"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"desmos.com/calculator/7wb…","expanded_url":"https://www.desmos.com/calculator/7wbvkts2jf","url":"https://t.co/Dle9fL6SSi","indices":[593,616]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/VkKtsCvz4u","expanded_url":"https://x.com/0xmomonifty/status/1947181136234569866/photo/1","id_str":"1947180609136369664","indices":[174,197],"media_key":"3_1947180609136369664","media_url_https":"https://pbs.twimg.com/media/GwXGcokaIAARK_k.png","type":"photo","url":"https://t.co/VkKtsCvz4u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1584,"w":2048,"resize":"fit"},"medium":{"h":928,"w":1200,"resize":"fit"},"small":{"h":526,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1632,"width":2110,"focus_rects":[{"x":0,"y":409,"w":2110,"h":1182},{"x":478,"y":0,"w":1632,"h":1632},{"x":600,"y":0,"w":1432,"h":1632},{"x":908,"y":0,"w":816,"h":1632},{"x":0,"y":0,"w":2110,"h":1632}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1947180609136369664"}}},{"display_url":"pic.x.com/VkKtsCvz4u","expanded_url":"https://x.com/0xmomonifty/status/1947181136234569866/photo/1","id_str":"1947180706146209792","indices":[174,197],"media_key":"3_1947180706146209792","media_url_https":"https://pbs.twimg.com/media/GwXGiR9W0AAOqoT.png","type":"photo","url":"https://t.co/VkKtsCvz4u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":714,"w":891,"resize":"fit"},"medium":{"h":714,"w":891,"resize":"fit"},"small":{"h":545,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":714,"width":891,"focus_rects":[{"x":0,"y":215,"w":891,"h":499},{"x":0,"y":0,"w":714,"h":714},{"x":21,"y":0,"w":626,"h":714},{"x":156,"y":0,"w":357,"h":714},{"x":0,"y":0,"w":891,"h":714}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1947180706146209792"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1947181136234569866","view_count":14828,"bookmark_count":173,"created_at":1753079134000,"favorite_count":137,"quote_count":1,"reply_count":9,"retweet_count":29,"user_id_str":"1744901065886318592","conversation_id_str":"1947181136234569866","full_text":"【Arbitrage 学习笔记 - ③ 价格计算】\n\n我们有了各种协议池子的基础数据之后,就要开始着手价格计算和套利路径,这是非常关键的两步。\n\n这里我们先从价格计算入手,学习并简单记录一下 Uni 以及 Fork 其协议的相关的计算方法。\n\n中文资料可以阅读 adshao/publications 、uniswapV 3-book-zh-cn 或者直接啃 Dapp-Learning\n\n▰▰▰▰▰▰\n恒定函数做市商 (CFMM)\n\nV2V3 原理公式 x∗y=k 仅此而已且都围绕着它展开,其中 _x_ 代表第一个 token,_y_ 代表第二个 token,k 是他俩的乘积每次交易后保持不变。交易函数可以用它的原理推导出(x+rΔx)(y−Δy)=k,\nΔx 为交易放入池子的 token,Δy 为换取的 token,r 为池子手续费。\n\n▰▰▰▰▰▰\nV2 的价格计算\n\n在 V 2 中池子的价格是由 token 的供给量决定的,也就是池子的流动性,池子中两种 token 的数量决定了价格,即 P = y/x 。但是需要注意的是交易实际成交的价格却并不是这个价格,需要把需求也就是 swap 输入的代币数量考虑其中,需求越高,价格越高。\n\n(x+rΔx)(y−Δy)=xy -> Δy=(yrΔx)/(x+rΔx) 和 Δx= (xΔy)/(r(y-Δy))\n\n我们可以在 https://t.co/Dle9fL6SSi 可以看到我们卖出 200 个 token0 期望的到 200 个 token1,但实际只获得了133.333。(交易的实际发生价格,是连接新旧点的这条线的斜率)\n\n▰▰▰▰▰▰\nV3 的价格计算\n\n作为 V2 的升级,V3 把价格区间分成了许多 ticks,每个 ticks 对应一个价格,由许多 x∗y=k 的池子组成相互重叠,在交易的时候先确定交易的方向,如果交易数量当前tick范围内使用该tick的可用流动性进行交换,如果还有剩余输入代币,继续在下一个tick范围内进行交换。\n\nV3 的价格公式与 V2 一样,但为了流动性与价格成线性关系,两边开根(x 没法开根表示) ,使用 Q64.96 定点数格式,文档中经常会见到 sqrtRatioNextX96 表示下一个tick边界的价格的平方根。\n\n计算方法可以参考 amms-rs 和 uniswap_v3_math ,步骤理解为循环体( 计算下一个 tick 边界价格 -> 计算本 tick 区间最多能 swap 多少 -> 更新剩余输入、累计输出 -> 是否到达 tick 边界<是 → 更新流动性,tick前进/否 → tick=当前价格对应tick>) 返回累计输出。\n\n(图片摘自 uniswapV 3-book)\n\n以上均为个人理解笔记,如有问题请积极指出,也非常感谢能够有大佬来指点一二","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,133],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/cKqSHJrpdW","expanded_url":"https://x.com/0xmomonifty/status/1962516933028581886/photo/1","id_str":"1962516510452424704","indices":[134,157],"media_key":"3_1962516510452424704","media_url_https":"https://pbs.twimg.com/media/GzxCXk9bIAAPWEQ.jpg","type":"photo","url":"https://t.co/cKqSHJrpdW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":746,"resize":"fit"},"medium":{"h":1200,"w":437,"resize":"fit"},"small":{"h":680,"w":248,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":1491,"focus_rects":[{"x":0,"y":95,"w":1491,"h":835},{"x":0,"y":0,"w":1491,"h":1491},{"x":0,"y":0,"w":1491,"h":1700},{"x":0,"y":0,"w":1491,"h":2982},{"x":0,"y":0,"w":1491,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1962516510452424704"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/cKqSHJrpdW","expanded_url":"https://x.com/0xmomonifty/status/1962516933028581886/photo/1","id_str":"1962516510452424704","indices":[134,157],"media_key":"3_1962516510452424704","media_url_https":"https://pbs.twimg.com/media/GzxCXk9bIAAPWEQ.jpg","type":"photo","url":"https://t.co/cKqSHJrpdW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":746,"resize":"fit"},"medium":{"h":1200,"w":437,"resize":"fit"},"small":{"h":680,"w":248,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4096,"width":1491,"focus_rects":[{"x":0,"y":95,"w":1491,"h":835},{"x":0,"y":0,"w":1491,"h":1491},{"x":0,"y":0,"w":1491,"h":1700},{"x":0,"y":0,"w":1491,"h":2982},{"x":0,"y":0,"w":1491,"h":4096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1962516510452424704"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1962516933028581886","view_count":24641,"bookmark_count":286,"created_at":1756735473000,"favorite_count":210,"quote_count":0,"reply_count":9,"retweet_count":37,"user_id_str":"1744901065886318592","conversation_id_str":"1962516933028581886","full_text":"【 Arbitrage 学习笔记 - ⑤ 寻找最优输入金额 】\n\n在 Dex-Dex 套利中,我们已经把 3 跳甚至 N 跳的路径全部枚举出来,接下来要做的就是:\n“在这些路径里,哪一条能给我带来最大利润?以及,我应该输入多少 tokens 才能让才能获得最大利润”\n\n之前我在路径查找的时候错误的理解成需要使用二分法快速的查找路径,怪自己学术不精误导了大家,非常尴尬,所以,非常恳求大佬们能够指点一二\n\n在利润计算的环节,这一步本质是一个带约束的线性规划问题。\n\n▰▰▰▰▰▰\n计算原理\n\n假设我们最终得到的路径是\nTokenA → TokenB → TokenC → TokenA\n把每一段池子的“有效汇率”写成 1×1 的标量:\nr₁ = ΔTokenB / ΔTokenA\nr₂ = ΔTokenC / ΔTokenB\nr₃ = ΔTokenA / ΔTokenC\n\n设投入 x 枚 TokenA,最终回收 y 枚 TokenA,则\nProfit (x) = y − x\n = x · r₁ · r₂ · r₃ − x\n = x (r₁r₂r₃ − 1)\n \n套利机会存在的充要条件是 r₁r₂r₃ > 1。\n\n这个方程通常没有解析解,需要用数值方法求根。其中牛顿迭代、二分查找或黄金分割,在一定的迭代次数内挑出能够获利的哪一条。\n\n▰▰▰▰▰▰\n方法示例\n\n在初次学习时,我们在程序中设置好最小金额和最大金额区间,以及循环步长后使用二分法左右寻找最优解。这里也可以参考 loom 的双向步长缩减算法,初始步长 1%,逐步缩小到 0.1%,以寻找利润最大化的输入金额。\n\n“把区间对半砍,看哪一半包含了根,再砍那一半,一直砍到足够细。”","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,175],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/KSfdEsqfbt","expanded_url":"https://x.com/0xmomonifty/status/1974142502635778316/photo/1","id_str":"1974142196191539207","indices":[176,199],"media_key":"3_1974142196191539207","media_url_https":"https://pbs.twimg.com/media/G2WP3jQbMAc0HHF.jpg","type":"photo","url":"https://t.co/KSfdEsqfbt","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1220,"w":2048,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2192,"width":3680,"focus_rects":[{"x":0,"y":131,"w":3680,"h":2061},{"x":744,"y":0,"w":2192,"h":2192},{"x":879,"y":0,"w":1923,"h":2192},{"x":1292,"y":0,"w":1096,"h":2192},{"x":0,"y":0,"w":3680,"h":2192}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1974142196191539207"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/KSfdEsqfbt","expanded_url":"https://x.com/0xmomonifty/status/1974142502635778316/photo/1","id_str":"1974142196191539207","indices":[176,199],"media_key":"3_1974142196191539207","media_url_https":"https://pbs.twimg.com/media/G2WP3jQbMAc0HHF.jpg","type":"photo","url":"https://t.co/KSfdEsqfbt","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1220,"w":2048,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2192,"width":3680,"focus_rects":[{"x":0,"y":131,"w":3680,"h":2061},{"x":744,"y":0,"w":2192,"h":2192},{"x":879,"y":0,"w":1923,"h":2192},{"x":1292,"y":0,"w":1096,"h":2192},{"x":0,"y":0,"w":3680,"h":2192}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1974142196191539207"}}}]},"favorited":true,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1974142502635778316","view_count":12847,"bookmark_count":220,"created_at":1759507225000,"favorite_count":163,"quote_count":1,"reply_count":9,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1974142502635778316","full_text":"【 Arbitrage 学习笔记 - 学习使用 Revm Database ① 】\n\n我刚开始学 Dex 套利时,为了计算 path 利润,直接用 RPC 拉取池子最新状态(用的 amms pool init),再把有利可图的交易 call 套利合约。虽然跑的是本地节点,但这套暴力操作还是会浪费服务器资源。\n后来我在学习大佬代码的时候发现一个宝藏的 crates -> revm:: database,可以使用该接口实现自己项目中一个小型内存数据库,这样既可以从 RPC Fork 目标账户等状态,也可以自由的修改调试执行状态变更。\n\n▰▰▰▰▰▰\n简单使用\n\n举个例子,我在上一篇中把最新区块变动的 Pool 保存下来包括池子的 reserve、slot 0 等状态已便后面的利润计算,那么我们开始尝试把这部分使用 revm:: database 实现一个内存数据库,记录和更新池子的信息。\n\n在 revm:: database 中,有一个 in_memory_db.rs ,其设计了一个 CacheDB,Cache 中有账户的基础信息(balance、nonce、code/code_hash) ,可以按需从只读后端懒加载账户/代码/存储,并支持本地执行后 commit 写回缓存,当然也可以使用它们外包一些适合自己的功能。\n\nCacheDB 有几个非常符合 EVM 的函数,load_account (),basic(),insert_contract (),insert_account_storage (),replace_account_storage ()。\n那么我们可以直接使用 insert_account_storage () 插入或修改 pool 的状态信息,\n\n之后我们可以使用 storage_ref () 来读取存储的最新 pool 信息,直接建立 AMM trait 来进行价格计算。运行后会发现 RPC 节点性能会非常稳定,且程序在建立池子信息时速度非常的快!\n\n▰▰▰▰▰▰\n小结\n\n这里我简单使用了 revm:: database ,但是它非常的强大,可以说是 REVM 与区块链状态之间的“桥梁”,之后我也会继续使用它来优化在程序中的细节,当然内容可能会理解有误,欢迎大佬们指点分享。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}],"activities":{"nreplies":[{"label":"2025-10-17","value":1,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":6,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":0,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":1,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":1,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":1,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":6,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":10,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":6,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":4,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":1,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":5,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":7,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":1,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":1,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}],"nbookmarks":[{"label":"2025-10-17","value":0,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":29,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":1,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":119,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":11,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":1,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":89,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":26,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":2,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":16,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":2,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}],"nretweets":[{"label":"2025-10-17","value":0,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":0,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":0,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":20,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":1,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":14,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":2,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":1,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":0,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}],"nlikes":[{"label":"2025-10-17","value":2,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":22,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":0,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":4,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":101,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":19,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":15,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":72,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":37,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":1,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":13,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":3,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":11,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":1,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":2,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}],"nviews":[{"label":"2025-10-17","value":1848,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":5177,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":243,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":3575,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":6701,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":149,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":13068,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":2663,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":12328,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":1690,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":4880,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":1802,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":3085,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":4104,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":914,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":1311,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":1558,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":1574,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":125,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}]},"interactions":{"users":[{"created_at":1675824163000,"uid":"1623150253452177413","id":"1623150253452177413","screen_name":"realxiodos","name":"真诚小道士丨MemeMax⚡️","friends_count":5062,"followers_count":25331,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1987712262484922368/FtzdMKxM_normal.jpg","description":"✧ 信仰 $OKB $PARTI ,立志要成为嘴撸王的男人丨 #蓝鸟会\n\n✦ 全链交易用UX丨https://t.co/XlXPMmAmIM 邀请码:2BEHE5\n\n✧ 出入金用BiYa丨https://t.co/fCvElmWLwf\n\n✦ 省钱就用Weex丨https://t.co/Xvk56bV3Sh","entities":{"description":{"urls":[{"display_url":"xiodos.com/ux","expanded_url":"http://xiodos.com/ux","url":"https://t.co/XlXPMmAmIM","indices":[47,70]},{"display_url":"xiodos.com/biya","expanded_url":"http://xiodos.com/biya","url":"https://t.co/fCvElmWLwf","indices":[95,118]},{"display_url":"xiodos.com/weex","expanded_url":"http://xiodos.com/weex","url":"https://t.co/Xvk56bV3Sh","indices":[131,154]}]},"url":{"urls":[{"display_url":"realxiodos.t.me","expanded_url":"http://realxiodos.t.me","url":"https://t.co/GI7czuMUyt","indices":[0,23]}]}},"interactions":1}],"period":14,"start":1761991343309,"end":1763200943309},"interactions_updated":1763200943407,"created":1763200943165,"updated":1763200943407,"type":"the analyst","hits":1},"people":[{"user":{"id":"808666100598710272","name":"Ken(✧ᴗ✧)","description":"A Technical Analyst 📉📈, Web3 Content Creator, Verified Tester of all Blockchain and Protocol","followers_count":1536,"friends_count":3697,"statuses_count":12401,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1958464360235372544/csRTYnlB_normal.jpg","screen_name":"symplyKen","location":"City Centre, Berlin","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"Ken(✧ᴗ✧) is a savvy Technical Analyst and Web3 content creator deeply immersed in the blockchain and AI privacy space. With an analytical mind and a passion for sharing insights, Ken breaks down complex protocols and emerging tech trends with clarity and authority. He’s not just testing and verifying—he’s educating and engaging a curious community about the future of decentralized tech.","purpose":"Ken’s life purpose centers on demystifying blockchain and AI innovations, empowering users to navigate these cutting-edge spaces confidently. He seeks to foster responsible development and adoption of privacy-focused technology, ultimately shaping a transparent and trustworthy digital ecosystem.","beliefs":"Ken values transparency, verifiability, and responsible innovation in technology. He believes in the power of data ownership and privacy as fundamental human rights, championing protocols that provide clear, auditable logic rather than blind trust. Community education and hands-on learning are core pillars of his approach.","facts":"Fun fact: Ken has tested and verified so many blockchain protocols that he could probably build his own decentralized AI privacy network before breakfast!","strength":"Ken’s strength lies in his deep technical expertise combined with his ability to translate complex ideas into engaging and accessible content. He excels at connecting advanced tech concepts with real-world applications and incentives, creating trust and enthusiasm within his audience.","weakness":"Ken’s deep dive into the technical details might sometimes alienate casual readers who want quick soundbites over in-depth analysis. Also, his high tweet volume could overwhelm followers, diluting the impact of each insight.","recommendation":"To grow his audience on X, Ken should blend his detailed tech posts with quick, digestible highlights or visual threads to hook casual scrollers. Engaging more with trending Web3 and AI conversations using popular hashtags and polls can boost visibility and foster community interaction.","roast":"Ken’s timeline looks like an open-source encyclopedia—great if you need a blockchain thesis, but even his coffee needs footnotes. Maybe give your followers a cheat sheet before you overload them with all those protocols, Professor Crypto.","win":"Ken’s biggest win is establishing himself as a trusted verifier in the blockchain community, helping users safely navigate and earn rewards through emerging protocols like @zk_agi and @irys_xyz. His contributions are paving the way for more transparent and privacy-conscious Web3 adoption."},"created":1763205629056,"type":"the analyst","id":"symplyken"},{"user":{"id":"420439902","name":"Sam Pavlovic","description":"Graphics Programmer at @FcpnchStds on @s8box, previously @PunyHuman @NodrawSoftware, Road Cycling enthusiast, super chill lad. \n\nAlways Do Good","followers_count":2752,"friends_count":1081,"statuses_count":11437,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1638246051294375952/K_MPYOnq_normal.jpg","screen_name":"SamZaNemesis","location":"","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"vitamin.software","expanded_url":"http://vitamin.software/","url":"https://t.co/seArai55CK","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Sam Pavlovic is a graphics programmer and keen cyclist who blends precision with a passion for cutting-edge tech. With a rich background in programming and a casual vibe, Sam delivers deep insights into graphics and API discussions. Beyond the code, Sam’s super chill demeanor keeps the tech talk engaging and approachable.","purpose":"Sam’s life purpose revolves around advancing graphics programming while fostering a community of informed and curious tech enthusiasts. Sharing knowledge and demystifying complex technical aspects to empower others is at the heart of their online presence.","beliefs":"Sam values transparency, precision, and innovation, believing that good tech communication bridges gaps between developers and users. They also uphold ethical sharing of information, respecting agreements and emphasizing the importance of responsibility in tech reporting.","facts":"Fun fact: Sam’s tweet about Metal API being better than Vulkan and DirectX sparked significant discussion, showing their authoritative yet approachable style in technical debates.","strength":"Sam’s strengths lie in their deep expertise in graphics programming and the ability to break down complex information engagingly, attracting a knowledgeable audience. Their consistent, high-quality tweets build trust and demonstrate thought leadership in a niche field.","weakness":"The technical depth and focused content might limit broader appeal, potentially alienating casual users or those outside the graphics programming community. Also, the super chill style might sometimes make their content seem less urgent or dynamic to fast-paced social media audiences.","roast":"Sam’s tweets are so technically dense that even their bike might get confused trying to follow along – maybe they should program a ‘tech-to-human’ translator next, or at least code a break for those of us not fluent in graphics jargon!","win":"Sam’s breakthrough tweet on Valve’s silent withholding of game info won massive engagement (over 150k views), establishing them as a credible voice on insider industry knowledge.","recommendation":"To grow their audience on X, Sam should consider mixing in relatable, behind-the-scenes stories or cycling adventures to humanize their brand. Engaging with broader tech conversations and using more accessible language occasionally will help widen their reach beyond hardcore graphics programmers."},"created":1763204895197,"type":"the analyst","id":"samzanemesis"},{"user":{"id":"1741393579187265536","name":"メタプラマニアック","description":"","followers_count":1995,"friends_count":194,"statuses_count":2371,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1916115481284710400/YVrM6N-h_normal.jpg","screen_name":"metapuramaniac","location":"","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"メタプラマニアック is a detail-oriented observer and commentator who thrives on dissecting complex financial and market information with precision. With a sharp eye for facts, they debunk misinformation and bring clarity to the chaotic world of investment. Their tweets reveal a deep passion for the Metaplanet community, combining data-driven insights with heartfelt engagement.","purpose":"To empower their audience with accurate, well-researched information that cuts through noise and speculation, fostering informed decision-making within the investment community.","beliefs":"They value truth, transparency, and intellectual rigor, believing that responsible commentary must be grounded in verifiable data rather than rumor or unfounded speculation. Community and shared knowledge are also core to their beliefs.","facts":"Fun fact: メタプラマニアック has tweeted over 2,371 times, showing a strong dedication to keeping their followers informed and engaged.","strength":"Exceptional ability to analyze complex financial data and communicate it clearly, combined with a commitment to factual accuracy and community building.","weakness":"Sometimes their direct and fact-focused communication style can come across as overly critical or blunt, potentially alienating more casual or emotional followers.","recommendation":"To grow their audience on X, メタプラマニアック should blend their strong analytical content with more approachable storytelling and relatable moments, perhaps using threads or multimedia to make complex data more digestible and engaging.","roast":"For someone who lives and breathes facts, you’ve spent so much time defending the numbers that your tweets might as well come with a calculator attached—and maybe a warning label for anyone who dares post an unsupported opinion!","win":"Successfully positioned themselves as a trusted voice debunking misinformation around Metaplanet’s public funding efforts, reinforcing community trust and attracting attention from major investment stakeholders."},"created":1763204737291,"type":"the analyst","id":"metapuramaniac"},{"user":{"id":"14553807","name":"morgan —","description":"deep yearning","followers_count":8474,"friends_count":2517,"statuses_count":50056,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1874095611563118592/IgVofQuu_normal.jpg","screen_name":"morqon","location":"london","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"info.cern.ch","expanded_url":"https://info.cern.ch","url":"https://t.co/E9mAbYKRR6","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Morgan is a data-driven thinker who dives deep into technology, economics, and industry trends with a sharp eye for detail. Their tweets reveal a passion for scrutinizing complex topics like AI, privacy, and startup culture, sharing incisive commentary that sparks thoughtful conversations. Always probing beneath the surface, Morgan’s presence is a magnet for those craving thoughtful analysis and nuanced perspectives.","purpose":"Morgan’s life purpose revolves around unraveling and explaining the complexities of the tech world, empowering their audience to make informed decisions and question prevailing narratives. They thrive on illuminating hidden truths and fostering critical thinking in an ever-evolving digital landscape.","beliefs":"Morgan believes in transparency, intellectual honesty, and the importance of data-backed insights. They value privacy and ethical considerations in technology while advocating for accountability in influential companies and leaders.","facts":"Fun fact: Despite posting over 50,000 tweets, Morgan’s follower count remains undefined, suggesting a relentless dedication to content and ideas over chasing popularity metrics.","strength":"Morgan’s greatest strength is their ability to distill complex subjects into engaging, insightful tweets that resonate with a curious, thoughtful audience. Their consistency and depth set them apart as a trusted source for nuanced tech and business critique.","weakness":"However, Morgan’s detailed and sometimes dense style can overwhelm casual readers and may limit broader engagement, especially in a fast-scrolling social media environment.","roast":"Morgan tweets so much analysis, even Sherlock Holmes would feel tired trying to keep up—and yet somehow, their follower count stays as mysterious as a secret CIA file.","win":"Morgan’s biggest win is creating viral tweets that break down tech giants’ strategies and controversies, influencing public discourse and educating thousands on complex industry maneuvers.","recommendation":"To grow their audience on X, Morgan should consider blending their deep dives with more accessible, bite-sized insights that hook casual scrollers. Engaging in conversations via replies and leveraging trending hashtags can also amplify their reach without sacrificing depth."},"created":1763204202938,"type":"the analyst","id":"morqon"},{"user":{"id":"2990381086","name":"Alex The Black Cap","description":"we are all someone's exit liquidity","followers_count":3760,"friends_count":4122,"statuses_count":6379,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1960682457428033536/NBnqCMtU_normal.jpg","screen_name":"blackcapx02","location":"","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"Alex The Black Cap is a deep thinker who thrives on dissecting complex concepts in the crypto and DeFi space while adding a pinch of humor and relatable commentary. With thousands of tweets, Alex blends insightful analysis, commentary on trending moments, and practical advice to keep the audience both informed and entertained. They embrace transparency and knowledge sharing, creating a space for thoughtful discussion and witty reflections.","purpose":"To demystify the complexities of DeFi and blockchain technologies for a broader audience, using data-driven insights and transparency advocacy to empower followers to make smarter decisions and navigate crypto risks with confidence.","beliefs":"Alex values transparency, risk management, and intellectual curiosity. They believe in empowering others through clear explanations and governance-based accountability, while also valuing humor and social awareness as tools for community engagement.","facts":"Alex advocates for transparency in DeFi, highlighting governance and upfront risk details as key to secure financial technologies. Also, they have a keen eye for current events, blending crypto insight with pop culture moments like the Salt Bae World Cup anecdote.","strength":"Exceptional ability to break down complex blockchain mechanics and industry nuances into digestible insights, coupled with prolific content creation and a knack for injecting humor into technical discussions.","weakness":"Their large following count compared to undefined follower count and intense focus on niche topics might limit wider appeal, potentially overwhelming some audiences with technical jargon or insider references.","recommendation":"To grow their audience on X, Alex should engage more interactively by turning technical content into approachable threads with Q&A sessions, and tap into trending topics with relatable memes to boost shareability. Collaborating with influencers outside the core crypto space could also expand reach.","roast":"For someone who tweets thousands of times, Alex might want to check if infinite scrolling on X is sponsoring their content strategy, because nobody reads that much without needing some kind of digital coffee break!","win":"Successfully educated a niche community on the nuances of DeFi risk management by pioneering transparent governance dialogues, making complex financial protocols more accessible and trusted."},"created":1763202012306,"type":"the analyst","id":"blackcapx02"},{"user":{"id":"1553753362633719808","name":"Gantrol","description":"全干工程师,计算机心理学家","followers_count":1251,"friends_count":96,"statuses_count":2588,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1904463887736655872/boo0HZaD_normal.jpg","screen_name":"gantrols","location":"","entities":{"description":{"urls":[]},"url":{"urls":[{"display_url":"github.com/gantrol","expanded_url":"http://github.com/gantrol","url":"https://t.co/ny8ID1IZ06","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Gantrol is a computer psychologist and all-around engineer who dived deep into the synergy of AI and coding. With a knack for breaking down complex AI tools and trends, they turn technical chaos into clear, actionable insights. Their feed is a treasure trove for those curious about AI’s intersection with programming and psychology.","purpose":"To decode the complexities of AI and software development, making cutting-edge technology accessible and usable for developers and tech enthusiasts alike. Gantrol aims to bridge human behavior with artificial intelligence through insightful analysis and practical applications.","beliefs":"They believe in the power of AI to augment human intellect and creativity, emphasizing transparency, innovation, and the importance of ethical tech development. Gantrol values curiosity, critical thinking, and continuous learning, always pushing boundaries to understand and improve the digital landscape.","facts":"Fun fact: Gantrol humorously transformed a classic undercover phrase from ‘有内鬼终止交易’ (There’s a mole, terminate the deal) to ‘有猫猫可以交易’ (If there’s a cat, deals can proceed), showing their playful side alongside serious tech analysis.","strength":"Expertise in dissecting AI applications and large-scale code repositories; an ability to communicate complex tech subjects clearly; adept at spotting trends and practical innovations in programming culture.","weakness":"Sometimes deep analytical dives may overwhelm casual followers, potentially limiting wider audience appeal. Also, focusing heavily on technical topics might reduce engagement from non-specialists.","recommendation":"To grow their audience on X, Gantrol should mix in more bite-sized explainers or relatable tech anecdotes paired with engaging visuals or threads to invite broader interaction. Collaborating with influencers from the AI and developer communities can also amplify reach.","roast":"Gantrol’s tweets are so deep in AI code they probably dream in binary — just don’t expect them to explain it without launching into a full research paper first. It’s like asking a philosopher to tell a joke; the answer is there, but you might need a PhD to find it!","win":"Gantrol’s insights inspired the creation of a web app that enhances large codebase navigation using AI, a testament to their influence on the developer ecosystem and practical innovation."},"created":1763201700395,"type":"the analyst","id":"gantrols"},{"user":{"id":"1889316413275623424","name":"Vector","description":"20 | Wannabe polymath | CS+Data science","followers_count":222,"friends_count":270,"statuses_count":1438,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1981801955216236544/-2DeE4hH_normal.jpg","screen_name":"_vector15","location":"127.0.0.1","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"Vector is a curious mind weaving through the worlds of computer science and data science, eager to connect dots across disciplines. With a solid tweet count and an active following list, Vector actively engages in thoughtful interactions, fueled by a desire to learn and share knowledge. They thrive on diving deep into complex topics, striving to become a true polymath on their journey.","purpose":"Vector’s life purpose is to cultivate a broad and nuanced understanding across multiple fields, especially in technology and data, breaking down intricate concepts to make sense of the vast information landscape. They seek to not only learn but also to facilitate insightful conversations that push boundaries and foster intellectual growth.","beliefs":"Vector values continuous learning, intellectual curiosity, and the power of data-driven insights. They believe in the strength of cross-disciplinary knowledge and view thoughtful analysis as a key to innovation and personal growth. Authentic engagement over superficial popularity matters more than follower counts to them.","facts":"Fun fact: Vector’s tweet about their 'Twitter Interaction Circle' suggests a preference for meaningful engagement with their community, reflecting a desire to build genuine connections rather than just amassing followers.","strength":"Vector excels in deep analytical thinking, quick adaptability to new topics, and using data to back up their insights. Their diverse interests across CS and data science fuel a unique perspective that combines technical rigor with broad conceptual horizons.","weakness":"A potential weakness is sometimes getting lost in the details, which can make their communication seem less accessible to casual followers. They might also undervalue the importance of consistent branding and louder social presence in favor of substantive content.","recommendation":"To grow their audience on X, Vector should blend their analytical posts with light, relatable content that invites broader interaction. Using threads to simplify complex topics, engaging more actively with trending discussions, and adding a personal touch to their tweets will help increase visibility and foster community growth.","roast":"Vector’s like that friend who corrects the game rules mid-play—super smart, but you’re not always sure if you’re having fun or taking a calculus exam. Chill on the deep dives sometimes; not every follower signed up for a lecture series!","win":"Vector’s biggest win is creating a recognized niche on X where thoughtful analysis and data-driven conversations thrive, setting themselves apart from the noise through their unique blend of curiosity and technical expertise."},"created":1763201686014,"type":"the analyst","id":"_vector15"},{"user":{"id":"1851722358177902592","name":"Anjuli Pierce","description":"Learning to prompt the future @ https://t.co/rF3Mgd4ZIH","followers_count":451,"friends_count":1342,"statuses_count":4120,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1970329879200542720/Alhjfh4q_normal.jpg","screen_name":"anjulipie","location":"","entities":{"description":{"urls":[{"display_url":"intü.com","expanded_url":"http://www.xn--int-joa.com","url":"https://t.co/rF3Mgd4ZIH","indices":[32,55]}]},"url":{"urls":[{"display_url":"anjulipierce.substack.com","expanded_url":"https://anjulipierce.substack.com/","url":"https://t.co/XDChFPSqHo","indices":[0,23]}]}}},"details":{"type":"The Analyst","description":"Anjuli Pierce is a thoughtful and inquisitive mind diving into the future of AI and society with a curiosity that sparks both caution and creativity. She combines a scientific background with a reflective perspective on social issues, often challenging conventional narratives. Her tweets weave insightful observations with a touch of personal vulnerability, making complex topics relatable and engaging.","purpose":"To uncover the nuanced realities of emerging technologies and societal change, guiding her community through thoughtful discourse that illuminates the path ahead. Anjuli aims to foster a deeper understanding of the future by blending analytical rigor with empathy.","beliefs":"She values intellectual honesty, curiosity, and the power of technology to reshape professions and social structures while acknowledging the human cost. Anjuli believes in confronting uncomfortable truths and exploring the balance between innovation and ethical responsibility.","facts":"Fun fact: She once described how reconnecting with a fellow thinker reignited her 'science brain,' showing her love for intellectual challenge and growth—even when it's 'sort of dangerous and fun.'","strength":"Her key strength lies in connecting complex ideas with real-world implications, making her analysis both accessible and thought-provoking. She excels at spotting irony and nuance, especially in debates around AI and societal change.","weakness":"At times, her analytical nature may lead her to overthink or appear skeptical, potentially alienating more optimistic or less technical audiences. The deep dive into nuanced topics might limit her reach to broader, more casual followers.","roast":"Anjuli probably spends more time debating an AI's ethical implications than deciding what to eat for lunch—because why settle for simplicity when you can analyze your sandwich's societal impact first?","win":"Successfully sparked meaningful conversations around AI's future in traditional industries, including a poignant comparison that highlights the generational divide in tech acceptance within the legal and culinary fields.","recommendation":"To grow her audience on X, Anjuli should blend her deep analyses with occasional lighter, relatable content, making complex ideas accessible through storytelling or visual threads. Engaging directly with diverse communities—especially those skeptical about AI—could broaden her impact and invite richer dialogue."},"created":1763200022020,"type":"the analyst","id":"anjulipie"},{"user":{"id":"99824067","name":"于川海","description":"痴迷于学习笛箫演奏。","followers_count":1925,"friends_count":688,"statuses_count":7123,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1981345300427018240/H1-0A-to_normal.jpg","screen_name":"joyrap","location":"宇宙中心","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"于川海 is a thoughtful and reflective user who immerses deeply in learning and personal growth, particularly in the art of flute and xiao performance. Their tweets reveal a keen eye for dissecting societal concepts, health advice, and personal anecdotes with a critical mindset. Always questioning norms and sharing insights, they engage followers by blending intellect with personal experience.","purpose":"To unravel conventional beliefs and provide clarity through well-reasoned analysis, offering followers actionable wisdom grounded in both life and professional experiences.","beliefs":"Believes in questioning societal assumptions (like '刚需'), values practical health knowledge tailored for modern lifestyles, and champions developing sustainable habits over fleeting trends. Prioritizes critical thinking, continuous learning, and balanced self-discipline.","facts":"Fun fact: 于川海 has tweeted over 7,000 times, showing remarkable dedication to sharing knowledge and engaging with their community frequently without relying heavily on follower count.","strength":"Exceptional at critical analysis and providing clear, nuanced perspectives on complex topics, particularly related to lifestyle, health, and personal reflections that resonate deeply with thoughtful audiences.","weakness":"May struggle with audience growth due to a low follower count despite high engagement and frequent posting. Their deep, reflective style might not appeal to more casual scrollers looking for quick, light content.","roast":"If 于川海’s X profile were a musical instrument, it’d be a perfectly tuned flute—beautifully intricate but occasionally so subtle that most people just walk by without noticing the melody.","win":"Achieved a viral discussion on the concept of '刚需' that garnered nearly 400,000 views and sparked widespread conversation with over a thousand likes and hundreds of replies, demonstrating influence beyond follower numbers.","recommendation":"To grow their audience on X, 于川海 should consider blending their deep analytical tweets with more visually engaging content like short videos of their flute performances or health tips. Engaging more in conversations by replying to trending posts could also help increase visibility while maintaining their intellectual brand."},"created":1763199780544,"type":"the analyst","id":"joyrap"},{"user":{"id":"1894197783206531074","name":"curry.eth","description":"@ethereum / ZK","followers_count":1777,"friends_count":2571,"statuses_count":51840,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1955940630091456526/i1vugq6B_normal.jpg","screen_name":"hangjin162536","location":"이더리움","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"curry.eth dives deep into the ZK (zero-knowledge) and Ethereum ecosystems, sharing detailed insights and updates with an engaged tech-savvy audience. With a prolific posting habit of over 51,000 tweets, they function as a persistent source of information and thoughtful commentary on cutting-edge crypto developments. Their content reveals a passion for advancing the community’s understanding of complex blockchain technologies.","purpose":"To illuminate and demystify intricate blockchain and ZK technologies, empowering the community to make informed decisions and contribute to the ecosystem’s growth through clear, data-driven analysis and transparent communication.","beliefs":"curry.eth values technological innovation, transparency, and community-driven progress within the blockchain space, believing that knowledge sharing and thoughtful discussion are critical to fostering trust and adoption of emerging decentralized technologies.","facts":"Fun fact: With over 51,840 tweets and a laser focus on ZK and Ethereum, curry.eth could probably tweet blockchain updates in their sleep—and maybe already does!","strength":"Their strengths lie in deep technical knowledge, consistent high-volume engagement, and a talent for breaking down complex topics like dual-token models, AI reputation systems, and roadmap developments into accessible insights for their followers.","weakness":"The vast volume of tweets, while impressive, might overwhelm or exhaust their audience, and their niche focus can limit appeal outside the blockchain-enthusiast community, potentially slowing follower growth.","recommendation":"To grow their audience on X, curry.eth should intersperse technical deep-dives with engaging, bite-sized threads or visuals that appeal to newcomers. Collaborating with influencers in adjacent crypto or tech fields and creating more interactive content like AMAs could also widen their reach.","roast":"With a tweet count high enough to crash Ethereum nodes, curry.eth’s keyboard must be burning hotter than the gas fees on the blockchain. At this rate, even Vitalik might tap out before the next tweet drops!","win":"Securing an invite to exclusive ZK-focused private dinners and gaining recognition from top projects like @brevis_zk showcases curry.eth’s status as a respected voice within the zero-knowledge proof community."},"created":1763199594749,"type":"the analyst","id":"hangjin162536"},{"user":{"id":"2836323086","name":"Kurosh 🕶️","description":"Impact Founder / nCMO @Solana / Generalist Observer / posts in English-Persian","followers_count":7781,"friends_count":2630,"statuses_count":27599,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1844611539258503175/FCp5h3NB_normal.jpg","screen_name":"Kurosh_La","location":"","entities":{"description":{"urls":[]}}},"details":{"type":"The Analyst","description":"Kurosh 🕶️ is a sharp-minded generalist who merges deep cultural insights with cutting-edge tech analysis. Bridging Persian and English worlds, he dissects everything from ancient architecture to blockchain trends with equal passion. His timeline is a vibrant tapestry of thoughtful observations and intellectual curiosity.","purpose":"To enlighten his audience by unraveling complex ideas across cultures and technologies, encouraging critical thinking and informed decision-making.","beliefs":"Kurosh believes in respecting historical context and cultural depth while embracing innovation and scientific progress—valuing an analytical, open-minded approach to understanding both past and future.","facts":"Fun fact: Kurosh once stood in front of a tomb feeling so conflicted about its architecture that he ended up backing away in respect of ancient customs—showing his unique blend of intellectual curiosity and cultural sensitivity!","strength":"His strengths lie in synthesizing diverse topics—ranging from ancient Persian history to modern blockchain trends—into insightful, engaging content that resonates with a knowledgeable audience.","weakness":"His highly analytical style and frequent posting (over 27k tweets!) might overwhelm casual followers or those less familiar with his bilingual, multifaceted approach.","roast":"Kurosh tweets so much and so fast that if thoughts were currency, he’d be a billionaire—just don’t expect him to pause long enough to explain why he thinks that ancient tomb’s architect secretly broke all the rules!","win":"Successfully growing an engaged bilingual community that spans culture, tech, and philosophy, making complex ideas approachable and sparking meaningful conversations.","recommendation":"To grow his audience on X, Kurosh should leverage thread storytelling—breaking down deep analyses into bite-sized, narrative-driven threads complete with visuals and translations, making it easier to attract and retain followers across languages and interests."},"created":1763199371410,"type":"the analyst","id":"kurosh_la"},{"user":{"id":"1768802827361730560","name":"佩德罗研究员 | Alpha 🧲 📈","description":"摒弃杂音,觅寂静。慢就是快,Find your way.| #BTC $Sol $Eth #Crypto 独立投资人 可提供投资咨询,欢迎加入我的社区: https://t.co/UfSI6uUztb 商务合作联系Tg: @A8Pedro 佣金全返币安钱包邀请码: C8TK3X9O","followers_count":10132,"friends_count":3289,"statuses_count":2560,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1768803337955385344/W1mDe_As_normal.jpg","screen_name":"A8_Pedro","location":"台湾","entities":{"description":{"urls":[{"display_url":"t.me/PedroResearch","expanded_url":"https://t.me/PedroResearch","url":"https://t.co/UfSI6uUztb","indices":[78,101]}]}}},"details":{"type":"The Analyst","description":"佩德罗研究员 | Alpha 🧲 📈 is a crypto-savvy independent investor who thrives on cutting through noise to find clarity in the chaotic world of blockchain. With a sharp eye on innovative projects, technical feasibility, and community-building, he provides insightful investment advice and fosters a dedicated crypto community. His tweets are a blend of deep research, market updates, and practical tools for fellow investors.","purpose":"To demystify the crypto universe by offering clear, data-driven insights and empower others with knowledge and tools to confidently navigate investments, accelerating both personal and communal growth in the crypto industry.","beliefs":"佩德罗相信技术的透明度与合理性是投资成功的基石,坚持慢即是快的理念,注重长远价值而非短期投机。对社区的开发与共享抱有高度热情,坚信团结协作能助力所有人共赢。","facts":"Fun fact: Despite the chaotic nature of crypto, Pedro finds peace and strength in silence and slow deliberate moves, a mantra rarely associated with the high-speed crypto world!","strength":"Exceptional research skills with a laser focus on technical validation combined with strong community engagement and the ability to break down complex concepts into actionable advice.","weakness":"Sometimes his deep analytical approach can seem too technical or slow-paced for fast-moving markets, potentially missing out on spur-of-the-moment opportunities or engaging less with casual audiences.","roast":"You’re so busy analyzing every micro-detail of crypto that you probably have a spreadsheet ranking your spreadsheets — by growth potential, of course, because even your chaos is systematic!","win":"Successfully cultivated a strong, engaged community around cutting-edge crypto projects, earned recognition from major influencers like @a1lon9, and provided valuable investment consulting that bridges technical detail with real-world impact.","recommendation":"To grow your audience on X, blend your deep-dive analyses with more frequent, bite-sized insights and interactive polls. Use engaging visuals and invite community debates to make your technical content more accessible and spark higher engagement."},"created":1763199291182,"type":"the analyst","id":"a8_pedro"}],"activities":{"nreplies":[{"label":"2025-10-17","value":1,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":6,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":0,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":1,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":1,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":1,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":6,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":10,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":6,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":4,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":1,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":5,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":7,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":1,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":1,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}],"nbookmarks":[{"label":"2025-10-17","value":0,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":29,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":1,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":119,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":11,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":1,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":89,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":26,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":2,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":16,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":2,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}],"nretweets":[{"label":"2025-10-17","value":0,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":0,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":0,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":0,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":20,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":1,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":0,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":14,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":2,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":0,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":1,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":0,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":0,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":0,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":0,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}],"nlikes":[{"label":"2025-10-17","value":2,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":22,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":0,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":4,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":101,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":0,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":19,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":15,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":72,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":0,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":37,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":0,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":1,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":13,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":3,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":11,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":1,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":2,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":0,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}],"nviews":[{"label":"2025-10-17","value":1848,"startTime":1760572800000,"endTime":1760659200000,"tweets":[{"bookmarked":false,"display_text_range":[0,95],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4LUDq","indices":[72,95]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/WLGo1gG2yW","expanded_url":"https://x.com/0xmomonifty/status/1978814822859898906/photo/1","id_str":"1978814476314136576","indices":[96,119],"media_key":"3_1978814476314136576","media_url_https":"https://pbs.twimg.com/media/G3YpSDEa0AA5pxN.jpg","type":"photo","url":"https://t.co/WLGo1gG2yW","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":676,"w":1004,"resize":"fit"},"medium":{"h":676,"w":1004,"resize":"fit"},"small":{"h":458,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":676,"width":1004,"focus_rects":[{"x":0,"y":0,"w":1004,"h":562},{"x":0,"y":0,"w":676,"h":676},{"x":30,"y":0,"w":593,"h":676},{"x":157,"y":0,"w":338,"h":676},{"x":0,"y":0,"w":1004,"h":676}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978814476314136576"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978814822859898906","view_count":1185,"bookmark_count":0,"created_at":1760621193000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978814822859898906","full_text":"我去,这是个什么玩意?\n\n赶紧进了点!\n\n0xd5ad50a7198f6b4aa2ff58fcf6a1747777777777\n\n结尾全是7\n\nhttps://t.co/Pqo6c4LUDq https://t.co/WLGo1gG2yW","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,20],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/53DtG09rmP","expanded_url":"https://x.com/0xmomonifty/status/1978851614736670865/photo/1","id_str":"1978851406338523137","indices":[21,44],"media_key":"3_1978851406338523137","media_url_https":"https://pbs.twimg.com/media/G3ZK3qIXAAEUY7c.jpg","type":"photo","url":"https://t.co/53DtG09rmP","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1000,"w":903,"resize":"fit"},"medium":{"h":1000,"w":903,"resize":"fit"},"small":{"h":680,"w":614,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1000,"width":903,"focus_rects":[{"x":0,"y":71,"w":903,"h":506},{"x":0,"y":0,"w":903,"h":903},{"x":0,"y":0,"w":877,"h":1000},{"x":24,"y":0,"w":500,"h":1000},{"x":0,"y":0,"w":903,"h":1000}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1978851406338523137"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1978851614736670865","view_count":663,"bookmark_count":0,"created_at":1760629964000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978851614736670865","full_text":"这一波改规则炸了啊,公平模式越来越不公平 https://t.co/53DtG09rmP","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-18","value":5177,"startTime":1760659200000,"endTime":1760745600000,"tweets":[{"bookmarked":false,"display_text_range":[0,130],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[117,125]}]},"favorited":false,"lang":"zh","retweeted":false,"fact_check":null,"id":"1978977005266669949","view_count":4658,"bookmark_count":29,"created_at":1760659860000,"favorite_count":22,"quote_count":0,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"【 1011 大跌之后,程序监控提醒的一些想法 】\n\n大家都知道在 1011 那天凌晨 (华人时间),加密货币市场出现历史级暴跌,被业内称为“1011 黑天鹅”。例如USDe、wBETH、BnSOL,都出现了 \"脱锚\" 的现象,听过 @rnmumu3 大佬的 Space,回去复盘一下如果那天自己有提醒功能,能够叫醒其实可以存在减少损失和有币价套利的机会,所以接下来也会简单的给自己做一个多所包括链上价格的监控提醒 Bot。\n\n以下仅自己的想法,如大佬们有建议恳求指点一二。\n\nCex 的数据获取其实很简单,各大所的 Http Api 一个 Get 请求就能获取全所上线的交易对(现货/合约)数据,如果不需要高频量化,按秒级轮询全量 tickers 就够了。Dex pool 的交易对价格可以从链上合约、聚合器 API、数据聚合平台、扫链平台 (API、或做 Client ) 获取。\n\n获取的数据频率不高仅做监控可以使用一些中间件,也可以做成各套利大佬们直接使用前端轮询获取数据和监控规则,个人比较喜欢纯内存所以会尝试并学习深入一下 Rust 的内存读写,HashMap/BTreeMap 等。\n\n监控规则个人认为可以从固定时间间隔的价差阀值(涨跌幅),或者同交易对跨所价差阀值来设定。从这几天大佬们分析的推文来看,其实监控交易所做市流动性来判断也是一个很好的选择,1011 当天价格下跌开始,做市商流动性会大幅减少和撤离,所以会尝试一下从交易盘口或者深度来监控,大佬们如果有更好的建议亦可指点。\n\n提醒方面常见的 TG,也可以飞书/钉钉/企微 Bot,但是听了大佬那天的 Space 其实电话提醒确实是个好点子,监控消息做好等级分类,就如 Log 分级 (info/warn/err) ,监控提醒也可以做分成,特别重要的可以使用电话提醒。(看到几个大佬也在做了)\n\n来到区块链发现可以做的东西有很多,边做也可以边学习到很多知识,也非常感谢各位大佬指点和分享!小白的我也会努力成长!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1978991214096429117","view_count":424,"bookmark_count":0,"created_at":1760663247000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@wquguru @rnmumu3 大佬细说学习一下","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1978990281472241758","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[18,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1882700477684764672","name":"小鸡毛🐶","screen_name":"dev_xjm","indices":[0,8]},{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[9,17]}]},"favorited":false,"in_reply_to_screen_name":"dev_xjm","lang":"ja","retweeted":false,"fact_check":null,"id":"1979118112239948183","view_count":95,"bookmark_count":0,"created_at":1760693502000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1978977005266669949","full_text":"@dev_xjm @rnmumu3 大佬可以","in_reply_to_user_id_str":"1882700477684764672","in_reply_to_status_id_str":"1979024981301330405","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-19","value":0,"startTime":1760745600000,"endTime":1760832000000,"tweets":[]},{"label":"2025-10-20","value":243,"startTime":1760832000000,"endTime":1760918400000,"tweets":[{"bookmarked":false,"display_text_range":[14,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1979873967856115956","view_count":243,"bookmark_count":1,"created_at":1760873712000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1979853846764822684","full_text":"@0xAA_Science 用快照","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1979853846764822684","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-21","value":0,"startTime":1760918400000,"endTime":1761004800000,"tweets":[]},{"label":"2025-10-22","value":0,"startTime":1761004800000,"endTime":1761091200000,"tweets":[]},{"label":"2025-10-23","value":0,"startTime":1761091200000,"endTime":1761177600000,"tweets":[]},{"label":"2025-10-24","value":3575,"startTime":1761177600000,"endTime":1761264000000,"tweets":[{"bookmarked":false,"display_text_range":[0,162],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}],"symbols":[{"indices":[481,486],"text":"SEND"},{"indices":[754,757],"text":"CC"}],"timestamps":[],"urls":[{"display_url":"x.com/cantonwallet/s…","expanded_url":"https://x.com/cantonwallet/status/1975627353947545838","url":"https://t.co/Qls3gFjZkK","indices":[549,572]},{"display_url":"templedigitalgroup.com","expanded_url":"https://templedigitalgroup.com/","url":"https://t.co/undxwbAZFM","indices":[648,671]},{"display_url":"x.com/angelhack/stat…","expanded_url":"https://x.com/angelhack/status/1978793051934839103","url":"https://t.co/f8nieIQs2q","indices":[786,809]}],"user_mentions":[{"id_str":"1635419045058031617","name":"Canton Network","screen_name":"CantonNetwork","indices":[845,859]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/mnsgd0JOf3","expanded_url":"https://x.com/0xmomonifty/status/1981188088220258522/photo/1","id_str":"1981188064094351360","indices":[163,186],"media_key":"3_1981188064094351360","media_url_https":"https://pbs.twimg.com/media/G36YDCmWcAAXjk0.jpg","type":"photo","url":"https://t.co/mnsgd0JOf3","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":678,"w":1577,"resize":"fit"},"medium":{"h":516,"w":1200,"resize":"fit"},"small":{"h":292,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":678,"width":1577,"focus_rects":[{"x":0,"y":0,"w":1211,"h":678},{"x":0,"y":0,"w":678,"h":678},{"x":0,"y":0,"w":595,"h":678},{"x":27,"y":0,"w":339,"h":678},{"x":0,"y":0,"w":1577,"h":678}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981188064094351360"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981188088220258522","view_count":1311,"bookmark_count":0,"created_at":1761187023000,"favorite_count":4,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981188088220258522","full_text":"2025 是 RWA 的标准年,它从“区块链的一个应用”进化为“全球金融体系的替代层”,使得传统金融世界在“链上重构”。\n那么目前 RWA 赛道有什么项目可以参与,能够博取未来空投呢?(带教程)\n\n最近火热的 - Canton Network\n\nCanton Network 并不是又出了一个 L1 区块链,而是真正的去一个 “全球金融操作系统”(Financial OS),它结合了公共链的开放连接能力与私有链的隐私保护和访问控制能力,专为满足金融行业严格的合规与隐私需求而设计。\n\n投资背景也非常强大,1.35 亿美元战略轮由 DRW Venture Capital 与 Tradeweb Markets 领投,参投方包括 Yzi Labs、Circle、Virtu 等,高盛、BNP、HSBC、DTCC 等华尔街巨头深度参与。\n\n那么如何参与进来呢?\n\n▰▰▰▰▰▰\nSend App + Canton Wallet 奖励\n\n1⃣ Send App × Canton Wallet \n门槛:KYC + 买 sendtag + 存 30 U + 持 1 k $SEND\n收益:每 10–30 分钟自动分发,预估日入约 180–360 CC\n状态:目前注册暂停,每日仍需登入领取,10 月底重开\nhttps://t.co/Qls3gFjZkK\n\n2⃣ Temple Loop 挖矿\n门槛:官网注册申请邀请码→KYC→每日签到\n收益:24 CC/天,填问卷获取 DC 身份\n状态:进行中,可参与\nhttps://t.co/undxwbAZFM\n\n3⃣ AngelHack Construct Ideathon \n门槛:注册并完成 5 个 Quest(含社交/原型)\n收益:完成Quest 1-5 完成赚取 $CC\n截止:Phase 1 在 10 月 31 日前分发代币\nhttps://t.co/f8nieIQs2q\n\n目前生态活动还处于活动早期,撸毛项目当然是越早参与越好!\n官方推特:@CantonNetwork","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1981296252206928005","view_count":2264,"bookmark_count":0,"created_at":1761212811000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1981292617406304324","full_text":"@0xAA_Science 有好多大额贷款的","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1981292617406304324","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-25","value":6701,"startTime":1761264000000,"endTime":1761350400000,"tweets":[{"bookmarked":false,"display_text_range":[0,178],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366749351079936","indices":[179,202],"media_key":"3_1981366749351079936","media_url_https":"https://pbs.twimg.com/media/G386j5DXcAAFffg.jpg","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1157,"w":2048,"resize":"fit"},"medium":{"h":678,"w":1200,"resize":"fit"},"small":{"h":384,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1954,"width":3458,"focus_rects":[{"x":0,"y":18,"w":3458,"h":1936},{"x":0,"y":0,"w":1954,"h":1954},{"x":0,"y":0,"w":1714,"h":1954},{"x":0,"y":0,"w":977,"h":1954},{"x":0,"y":0,"w":3458,"h":1954}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366749351079936"}}},{"display_url":"pic.x.com/JnGVaAjkjU","expanded_url":"https://x.com/0xmomonifty/status/1981532463907426791/photo/1","id_str":"1981366842514907136","indices":[179,202],"media_key":"3_1981366842514907136","media_url_https":"https://pbs.twimg.com/media/G386pUHWoAA8j1T.png","type":"photo","url":"https://t.co/JnGVaAjkjU","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1096,"w":1840,"resize":"fit"},"medium":{"h":715,"w":1200,"resize":"fit"},"small":{"h":405,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1096,"width":1840,"focus_rects":[{"x":0,"y":66,"w":1840,"h":1030},{"x":416,"y":0,"w":1096,"h":1096},{"x":484,"y":0,"w":961,"h":1096},{"x":690,"y":0,"w":548,"h":1096},{"x":0,"y":0,"w":1840,"h":1096}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1981366842514907136"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1981532463907426791","view_count":6701,"bookmark_count":119,"created_at":1761269129000,"favorite_count":101,"quote_count":1,"reply_count":1,"retweet_count":20,"user_id_str":"1744901065886318592","conversation_id_str":"1981532463907426791","full_text":"【 分享一个能够像查找数据库一样来搜索查询 EVM 链交易的工具 - mevlog-rs 】\n\n在学习 Dex / Mev bot 的时候,经常要去查找特定的交易,比如某个区块的 Uni sync/swap/mint/burn 交易,或者查找最近几个区块高 Gas 价格进行筛选,或者查找如转账大于>1000 个代币的合约地址等等,mevlog-rs 都可以轻松做到。\n\n它可以适合研究MEV 相关的交易行为,监控特定链上的交易活动,挖掘特定类型的交易数据,以及追踪智能合约存储变化,分析合约调用行为。\n\n目前 mevlog-rs 有网页版和 Cli 版本,且与 ChainList 集成支持多链使用。\n\n总之 `mevlog-rs` 是一个功能强大的工具,非常适合开发者、链上爱好们使用!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-26","value":0,"startTime":1761350400000,"endTime":1761436800000,"tweets":[]},{"label":"2025-10-27","value":149,"startTime":1761436800000,"endTime":1761523200000,"tweets":[{"bookmarked":false,"display_text_range":[39,51],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]},{"id_str":"1749307986449985536","name":"River","screen_name":"RiverdotInc","indices":[12,24]},{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[25,38]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1982451036129472690","view_count":149,"bookmark_count":0,"created_at":1761488133000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982420193034035307","full_text":"@Supers6061 @RiverdotInc @momochenming 什么时候能跟s哥同屏一下","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1982420193034035307","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-28","value":13068,"startTime":1761523200000,"endTime":1761609600000,"tweets":[{"bookmarked":false,"display_text_range":[0,29],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}],"symbols":[{"indices":[24,29],"text":"USDA"}],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/J227EFo9Vs","expanded_url":"https://x.com/0xmomonifty/status/1982662540552499441/photo/1","id_str":"1982662531266007040","indices":[30,53],"media_key":"3_1982662531266007040","media_url_https":"https://pbs.twimg.com/media/G4PVEU2WUAASDN5.jpg","type":"photo","url":"https://t.co/J227EFo9Vs","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":947,"resize":"fit"},"medium":{"h":1200,"w":555,"resize":"fit"},"small":{"h":680,"w":314,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":947,"focus_rects":[{"x":0,"y":1321,"w":947,"h":530},{"x":0,"y":1101,"w":947,"h":947},{"x":0,"y":968,"w":947,"h":1080},{"x":0,"y":154,"w":947,"h":1894},{"x":0,"y":0,"w":947,"h":2048}]},"media_results":{"result":{"media_key":"3_1982662531266007040"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1982662540552499441","view_count":11581,"bookmark_count":11,"created_at":1761538560000,"favorite_count":18,"quote_count":0,"reply_count":5,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1982662540552499441","full_text":"又有脱锚的了,靠,怎么样监控才能抓住这种机会! $USDA https://t.co/J227EFo9Vs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,17],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1982665004529963132","view_count":514,"bookmark_count":0,"created_at":1761539147000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982398893452403181","full_text":"@wquguru 找到了,感谢大佬","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1982398893452403181","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1345108752534368257","name":"MOMO默默","screen_name":"momochenming","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"momochenming","lang":"zh","retweeted":false,"fact_check":null,"id":"1982659478400233633","view_count":973,"bookmark_count":0,"created_at":1761537830000,"favorite_count":0,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1982650551180652702","full_text":"@momochenming 卧槽,这个应该怎么监控","in_reply_to_user_id_str":"1345108752534368257","in_reply_to_status_id_str":"1982650551180652702","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-29","value":2663,"startTime":1761609600000,"endTime":1761696000000,"tweets":[{"bookmarked":false,"display_text_range":[0,174],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}],"symbols":[],"timestamps":[],"urls":[{"display_url":"0xmomo.com/ux","expanded_url":"http://0xmomo.com/ux","url":"https://t.co/Pqo6c4MssY","indices":[37,60]}],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983170362134409217","indices":[175,198],"media_key":"3_1983170362134409217","media_url_https":"https://pbs.twimg.com/media/G4Wi7-QasAEzV98.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":255,"y":471,"h":111,"w":111},{"x":795,"y":259,"h":147,"w":147},{"x":345,"y":627,"h":145,"w":145},{"x":909,"y":623,"h":155,"w":155},{"x":911,"y":785,"h":169,"w":169},{"x":1475,"y":961,"h":157,"w":157}]},"medium":{"faces":[{"x":149,"y":276,"h":65,"w":65},{"x":466,"y":152,"h":86,"w":86},{"x":202,"y":367,"h":85,"w":85},{"x":532,"y":365,"h":91,"w":91},{"x":534,"y":460,"h":99,"w":99},{"x":864,"y":563,"h":92,"w":92}]},"small":{"faces":[{"x":84,"y":156,"h":36,"w":36},{"x":264,"y":86,"h":49,"w":49},{"x":114,"y":208,"h":48,"w":48},{"x":302,"y":207,"h":51,"w":51},{"x":302,"y":260,"h":56,"w":56},{"x":489,"y":319,"h":52,"w":52}]},"orig":{"faces":[{"x":434,"y":800,"h":189,"w":189},{"x":1350,"y":441,"h":251,"w":251},{"x":586,"y":1065,"h":247,"w":247},{"x":1543,"y":1058,"h":264,"w":264},{"x":1547,"y":1333,"h":288,"w":288},{"x":2503,"y":1631,"h":268,"w":268}]}},"sizes":{"large":{"h":1217,"w":2048,"resize":"fit"},"medium":{"h":713,"w":1200,"resize":"fit"},"small":{"h":404,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3474,"focus_rects":[{"x":0,"y":0,"w":3474,"h":1945},{"x":1410,"y":0,"w":2064,"h":2064},{"x":1663,"y":0,"w":1811,"h":2064},{"x":2176,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3474,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983170362134409217"}}},{"display_url":"pic.x.com/xuj0T7iR8u","expanded_url":"https://x.com/0xmomonifty/status/1983174013359927577/photo/1","id_str":"1983171844367917057","indices":[175,198],"media_key":"3_1983171844367917057","media_url_https":"https://pbs.twimg.com/media/G4WkSQAbIAEOR0j.jpg","type":"photo","url":"https://t.co/xuj0T7iR8u","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":277,"y":643,"h":91,"w":91},{"x":1664,"y":407,"h":117,"w":117}]},"medium":{"faces":[{"x":162,"y":377,"h":53,"w":53},{"x":975,"y":238,"h":69,"w":69}]},"small":{"faces":[{"x":92,"y":213,"h":30,"w":30},{"x":552,"y":135,"h":39,"w":39}]},"orig":{"faces":[{"x":471,"y":1091,"h":155,"w":155},{"x":2821,"y":691,"h":200,"w":200}]}},"sizes":{"large":{"h":1208,"w":2048,"resize":"fit"},"medium":{"h":708,"w":1200,"resize":"fit"},"small":{"h":401,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2048,"width":3472,"focus_rects":[{"x":0,"y":0,"w":3472,"h":1944},{"x":1424,"y":0,"w":2048,"h":2048},{"x":1676,"y":0,"w":1796,"h":2048},{"x":2448,"y":0,"w":1024,"h":2048},{"x":0,"y":0,"w":3472,"h":2048}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1983171844367917057"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1983174013359927577","view_count":581,"bookmark_count":1,"created_at":1761660505000,"favorite_count":13,"quote_count":0,"reply_count":9,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983174013359927577","full_text":"【 UniversalX 的 全链战壕 + 聪明钱监控 来啦 】\n\n链接:https://t.co/Pqo6c4MssY\n\n这一次 UX 大版本更新,重点增加了仅需一个界面就可以监控所有链的代币发射、迁移以及全链聪明钱等。\n再也不用多开页面一会儿追 BSC 错过 Base 又忘记去看 SOL 啦!\n\n现在就是一眼看全链,直接打天下,用起来真的爽! https://t.co/xuj0T7iR8u","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1494981048496627712","name":"Supers🔶 BNB | Ⓜ️Ⓜ️T","screen_name":"Supers6061","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Supers6061","lang":"zh","retweeted":false,"fact_check":null,"id":"1983033647583375856","view_count":569,"bookmark_count":0,"created_at":1761627039000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983021002612252681","full_text":"@Supers6061 我在农村有山有地她有么","in_reply_to_user_id_str":"1494981048496627712","in_reply_to_status_id_str":"1983021002612252681","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[13,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1416454684525662215","name":"币世王","screen_name":"0xKingsKuan","indices":[0,12]}]},"favorited":false,"in_reply_to_screen_name":"0xKingsKuan","lang":"zh","retweeted":false,"fact_check":null,"id":"1983187682084958565","view_count":22,"bookmark_count":0,"created_at":1761663763000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983180212578734321","full_text":"@0xKingsKuan 是个插件吗","in_reply_to_user_id_str":"1416454684525662215","in_reply_to_status_id_str":"1983180212578734321","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[31,38],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1125309529145524224","name":"WquGuru🦀","screen_name":"wquguru","indices":[0,8]},{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[9,20]},{"id_str":"1612183962767749120","name":"NagnoHux老徐","screen_name":"HuxNagno","indices":[21,30]}]},"favorited":false,"in_reply_to_screen_name":"wquguru","lang":"zh","retweeted":false,"fact_check":null,"id":"1983204019419111435","view_count":1491,"bookmark_count":0,"created_at":1761667659000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983197405320491366","full_text":"@wquguru @Web3Tinkle @HuxNagno 谢谢哥,收藏了","in_reply_to_user_id_str":"1125309529145524224","in_reply_to_status_id_str":"1983197405320491366","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-10-30","value":12328,"startTime":1761696000000,"endTime":1761782400000,"tweets":[{"bookmarked":false,"display_text_range":[0,135],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[{"display_url":"defi.krystal.app","expanded_url":"https://defi.krystal.app","url":"https://t.co/LOv5Td1vcf","indices":[406,429]}],"user_mentions":[]},"favorited":false,"lang":"zh","quoted_status_id_str":"1886062558282666435","quoted_status_permalink":{"url":"https://t.co/Xtkr3srCl9","expanded":"https://twitter.com/0xmomonifty/status/1886062558282666435","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1983549030996353427","view_count":12328,"bookmark_count":89,"created_at":1761749916000,"favorite_count":72,"quote_count":1,"reply_count":6,"retweet_count":14,"user_id_str":"1744901065886318592","conversation_id_str":"1983549030996353427","full_text":"在之前写过一次 Uni V4 大致更新了什么,但是还没有深入的去学习,这几天埋伏在大佬的群里发现,一些 Meme 代币因热点叙事快速启动交易量暴增的时候,组 V4 自定义高费率池子会有非常炸裂的收益,甚至有些地址大概采用高频窄区间的 Bot 能够在短时间超高高 APR。\n\n个人认为这也需要非常敏锐的嗅觉或者代币对流量监控,在短时间热点爆发的时候进行切入,也要在冷却下来之前理性的撤出,因为我自己之前在玩 V3 AutoLP 的时候,无偿损失还是经常会大于手续费收益的。\n\nV4 是一个非常好的协议,我觉得确实也可以把它引入到自己的交易系统里,深入的去学习一下单例架构、闪电核算以及 Hooks 机制。\n\n这里分享一个大佬推荐的网站,它能够一键快速组池子(会自动聚合 Swap 代币、自动复投等高阶操作),发掘各种池子收益,以及观察其他地址池子收益、历史状态等,超级实用!当然有能力也可以尝试自己去写 Bot!(https://t.co/LOv5Td1vcf)","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null}]},{"label":"2025-10-31","value":1690,"startTime":1761782400000,"endTime":1761868800000,"tweets":[{"bookmarked":false,"display_text_range":[12,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"732807878424334336","name":"Tinkle","screen_name":"Web3Tinkle","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"Web3Tinkle","lang":"ja","retweeted":false,"fact_check":null,"id":"1983772613173506539","view_count":1598,"bookmark_count":0,"created_at":1761803222000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983761955497377821","full_text":"@Web3Tinkle 大佬牛逼,先收藏了","in_reply_to_user_id_str":"732807878424334336","in_reply_to_status_id_str":"1983761955497377821","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1892893080334053376","name":"City Protocol","screen_name":"cityprotocolHQ","indices":[0,15]},{"id_str":"1586321159745720321","name":"Mocaverse","screen_name":"Moca_Network","indices":[16,29]}]},"favorited":false,"in_reply_to_screen_name":"cityprotocolHQ","lang":"zh","retweeted":false,"fact_check":null,"id":"1983776039521382816","view_count":92,"bookmark_count":0,"created_at":1761804039000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1983594155843432732","full_text":"@cityprotocolHQ @Moca_Network 听起来很棒","in_reply_to_user_id_str":"1892893080334053376","in_reply_to_status_id_str":"1983594155843432732","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-01","value":4880,"startTime":1761868800000,"endTime":1761955200000,"tweets":[{"bookmarked":false,"display_text_range":[0,179],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/dttED0oXZN","expanded_url":"https://x.com/0xmomonifty/status/1984151798387806599/photo/1","id_str":"1984151711460847616","indices":[180,203],"media_key":"3_1984151711460847616","media_url_https":"https://pbs.twimg.com/media/G4kfeBYbcAAT4Z3.jpg","type":"photo","url":"https://t.co/dttED0oXZN","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":2048,"w":1845,"resize":"fit"},"medium":{"h":1200,"w":1081,"resize":"fit"},"small":{"h":680,"w":613,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":4084,"width":3680,"focus_rects":[{"x":0,"y":1522,"w":3680,"h":2061},{"x":0,"y":404,"w":3680,"h":3680},{"x":49,"y":0,"w":3582,"h":4084},{"x":819,"y":0,"w":2042,"h":4084},{"x":0,"y":0,"w":3680,"h":4084}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1984151711460847616"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1984151798387806599","view_count":3284,"bookmark_count":26,"created_at":1761893627000,"favorite_count":37,"quote_count":0,"reply_count":4,"retweet_count":2,"user_id_str":"1744901065886318592","conversation_id_str":"1984151798387806599","full_text":"打了几天狗,继续把之前的 Arb/Mev 状态捡回来。\n\nhardhat 和 foundry是目前优秀且最受欢迎的两个 solidity 合约开发工具,而目前大佬们使用 foundry 更加多一点,同比 hardhat 它的运行速度更快,可以直接使用 Solidity 测试,并且支持 Fork 主网环境进行本地测试,比如常用的 uniswap 就非常方便。\n\nFoundry 包含 4 个工具:forge, cast, anvil, chisel\n\n- forge 用于项目的编译、部署、测试等\n- cast 可以轻松的交互 RPC,如拉取链上信息,发送交易以及交互合约等,有些时候我甚至会用 AI Agent 配合它来获取一些地址/合约的最新状态\n- anvil 可以在本地创建测试节点,支持 RPC 分叉,快速的模拟主网环境\n- chisel 本地开启 solidity 环境,能够在命令行中运行 solidity 代码\n\n在我学习 arb 的过程中,发现 anvil 也可以用于分叉当前的链状态并在本地快速的检测套利机会,过程中 anvil 会按需从 RPC 获取必要的链上数据,如 eth_getCode、eth_getBalance 等,之后的请求都在本地的 anvil 进行以便快速运行节省节点性能。","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[28,35],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]},{"id_str":"1657253994996310017","name":"ETH Strategy","screen_name":"eth_strategy","indices":[14,27]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"ja","retweeted":false,"fact_check":null,"id":"1984279295997751807","view_count":1468,"bookmark_count":0,"created_at":1761924024000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984232362218279271","full_text":"@0xAA_Science @eth_strategy huff 省油","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1984232362218279271","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[12,23],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"902926941413453824","name":"CZ 🔶 BNB","screen_name":"cz_binance","indices":[0,11]}]},"favorited":false,"in_reply_to_screen_name":"cz_binance","lang":"zh","retweeted":false,"fact_check":null,"id":"1984171302467596776","view_count":128,"bookmark_count":0,"created_at":1761898277000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984169966858367363","full_text":"@cz_binance 都币圈首富了还差这点?","in_reply_to_user_id_str":"902926941413453824","in_reply_to_status_id_str":"1984170451241705753","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-02","value":1802,"startTime":1761955200000,"endTime":1762041600000,"tweets":[{"bookmarked":false,"display_text_range":[11,22],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1676484342821040129","name":"Bruce","screen_name":"BTCBruce1","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"BTCBruce1","lang":"zh","retweeted":false,"fact_check":null,"id":"1984417659539374329","view_count":1802,"bookmark_count":0,"created_at":1761957013000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984409556500586614","full_text":"@BTCBruce1 鲍威尔怎么也来搭矿场了","in_reply_to_user_id_str":"1676484342821040129","in_reply_to_status_id_str":"1984409556500586614","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-03","value":3085,"startTime":1762041600000,"endTime":1762128000000,"tweets":[{"bookmarked":false,"display_text_range":[16,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1428246848301502464","name":"吴说区块链","screen_name":"wublockchain12","indices":[0,15]}]},"favorited":false,"in_reply_to_screen_name":"wublockchain12","lang":"zh","retweeted":false,"fact_check":null,"id":"1984998269941141854","view_count":3085,"bookmark_count":2,"created_at":1762095441000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1984946361041657978","full_text":"@wublockchain12 做 LP 是不是也能实现","in_reply_to_user_id_str":"1428246848301502464","in_reply_to_status_id_str":"1984946361041657978","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-04","value":4104,"startTime":1762128000000,"endTime":1762214400000,"tweets":[{"bookmarked":false,"display_text_range":[0,67],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/ld6S1jXa6N","expanded_url":"https://x.com/0xmomonifty/status/1985263260434829411/photo/1","id_str":"1985261684060196864","indices":[68,91],"media_key":"3_1985261684060196864","media_url_https":"https://pbs.twimg.com/media/G40Q-7iaEAArAiS.jpg","type":"photo","url":"https://t.co/ld6S1jXa6N","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":732,"w":1360,"resize":"fit"},"medium":{"h":646,"w":1200,"resize":"fit"},"small":{"h":366,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":732,"width":1360,"focus_rects":[{"x":0,"y":0,"w":1307,"h":732},{"x":144,"y":0,"w":732,"h":732},{"x":189,"y":0,"w":642,"h":732},{"x":327,"y":0,"w":366,"h":732},{"x":0,"y":0,"w":1360,"h":732}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985261684060196864"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1985263260434829411","view_count":1567,"bookmark_count":1,"created_at":1762158620000,"favorite_count":6,"quote_count":1,"reply_count":5,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985263260434829411","full_text":"以太坊 DeFi Balancer 被盗约 7000wu ?\n\n以前学习闪电贷的时候看过它,记得 0 fee 来着\n\n熊市节目又来了呀 https://t.co/ld6S1jXa6N","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[0,159],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[]},"extended_entities":{"media":[{"display_url":"pic.x.com/s8BQj16nLf","expanded_url":"https://x.com/0xmomonifty/status/1985381256587358578/photo/1","id_str":"1985381055541739520","indices":[160,183],"media_key":"3_1985381055541739520","media_url_https":"https://pbs.twimg.com/media/G419jQ9bAAA-5ng.jpg","type":"photo","url":"https://t.co/s8BQj16nLf","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[]},"medium":{"faces":[]},"small":{"faces":[]},"orig":{"faces":[]}},"sizes":{"large":{"h":1821,"w":2048,"resize":"fit"},"medium":{"h":1067,"w":1200,"resize":"fit"},"small":{"h":605,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":3272,"width":3680,"focus_rects":[{"x":0,"y":347,"w":3680,"h":2061},{"x":204,"y":0,"w":3272,"h":3272},{"x":405,"y":0,"w":2870,"h":3272},{"x":1022,"y":0,"w":1636,"h":3272},{"x":0,"y":0,"w":3680,"h":3272}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1985381055541739520"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"quoted_status_id_str":"1984151798387806599","quoted_status_permalink":{"url":"https://t.co/wiHySLOX0l","expanded":"https://twitter.com/0xmomonifty/status/1984151798387806599","display":"x.com/0xmomonifty/st…"},"retweeted":false,"fact_check":null,"id":"1985381256587358578","view_count":1007,"bookmark_count":15,"created_at":1762186752000,"favorite_count":7,"quote_count":0,"reply_count":0,"retweet_count":1,"user_id_str":"1744901065886318592","conversation_id_str":"1985381256587358578","full_text":"上一次讲过使用 Foundry 的 Anvil 来 Fork 当前的链状态在本地快速的进行交易测试,因为 Anvil 能够快速的运行一个本地节点,那么作为用 Rust 语言实现的以太坊虚拟机 - REVM,它能够快速的 build 一个虚拟机,并可以将交易在本地虚拟机中运行。\n\n再加上 revm:: database ,之前我们说过使用它来构建我们的内存数据库,那么现在可以就非常完美的使用 InMemoryDB 构建一个 EVM 实例,快速的在环境中测试交易,并且 Anvil 的底层就是使用 REVM 实现的,配合 InMemoryDB 同样减少了 RPC 调用的次数,减少节点压力。\n\n在这里可以查看 solidquant/revm-is-all-you-need 和之前分享过 mevlog-rs 的大佬博客文章 revm-alloy-anvil-arbitrage,非常清楚的讲了 revm 构建一个实例的原理,以及各种本地模拟方法的性能比较。\n\n当然有小伙伴感兴趣的话我也可以用中文详细的写一篇,以便我更加的巩固去学习这方面的知识。\n\n有问题也欢迎大佬指点一二!","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":1,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,32],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985261147445198913","view_count":1530,"bookmark_count":0,"created_at":1762158116000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985259460361854981","full_text":"@0xAA_Science 没节目就没没有熊市的味道了,哈哈哈哈","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985259460361854981","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-05","value":914,"startTime":1762214400000,"endTime":1762300800000,"tweets":[{"bookmarked":false,"display_text_range":[9,11],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1355081624711401472","name":"May","screen_name":"0xMayyy","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"0xMayyy","lang":"ja","retweeted":false,"fact_check":null,"id":"1985579396380627225","view_count":31,"bookmark_count":0,"created_at":1762233993000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985332644046049698","full_text":"@0xMayyy 羡慕","in_reply_to_user_id_str":"1355081624711401472","in_reply_to_status_id_str":"1985332644046049698","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[14,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1456122941192605705","name":"0xAA","screen_name":"0xAA_Science","indices":[0,13]}]},"favorited":false,"in_reply_to_screen_name":"0xAA_Science","lang":"zh","retweeted":false,"fact_check":null,"id":"1985704108016480322","view_count":331,"bookmark_count":0,"created_at":1762263726000,"favorite_count":2,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985575545887998330","full_text":"@0xAA_Science 隐私赛道最喜欢 XMR","in_reply_to_user_id_str":"1456122941192605705","in_reply_to_status_id_str":"1985575545887998330","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[9,21],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"2688688196","name":"秋田散人 Mr.Akita","screen_name":"lnkybtc","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"lnkybtc","lang":"zh","retweeted":false,"fact_check":null,"id":"1985687569263362416","view_count":552,"bookmark_count":0,"created_at":1762259783000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985663894871027718","full_text":"@lnkybtc 回忆我都会,往前一片迷茫","in_reply_to_user_id_str":"2688688196","in_reply_to_status_id_str":"1985663894871027718","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-06","value":1311,"startTime":1762300800000,"endTime":1762387200000,"tweets":[{"bookmarked":false,"display_text_range":[0,156],"entities":{"hashtags":[],"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]},{"id_str":"1815660590008025088","name":"INFINIT","screen_name":"Infinit_Labs","indices":[561,574]}]},"extended_entities":{"media":[{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083653982842880","indices":[157,180],"media_key":"3_1986083653982842880","media_url_https":"https://pbs.twimg.com/media/G4_8j4HbcAATkAf.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1575,"y":1027,"h":111,"w":111}]},"medium":{"faces":[{"x":923,"y":602,"h":65,"w":65}]},"small":{"faces":[{"x":523,"y":341,"h":36,"w":36}]},"orig":{"faces":[{"x":1983,"y":1294,"h":140,"w":140}]}},"sizes":{"large":{"h":1479,"w":2048,"resize":"fit"},"medium":{"h":867,"w":1200,"resize":"fit"},"small":{"h":491,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":1862,"width":2578,"focus_rects":[{"x":0,"y":0,"w":2578,"h":1444},{"x":716,"y":0,"w":1862,"h":1862},{"x":945,"y":0,"w":1633,"h":1862},{"x":1647,"y":0,"w":931,"h":1862},{"x":0,"y":0,"w":2578,"h":1862}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083653982842880"}}},{"display_url":"pic.x.com/qldRgQLYGR","expanded_url":"https://x.com/0xmomonifty/status/1986084249750147200/photo/1","id_str":"1986083789081333761","indices":[157,180],"media_key":"3_1986083789081333761","media_url_https":"https://pbs.twimg.com/media/G4_8rvZa0AEPNQH.jpg","type":"photo","url":"https://t.co/qldRgQLYGR","ext_media_availability":{"status":"Available"},"features":{"large":{"faces":[{"x":1271,"y":469,"h":129,"w":129},{"x":907,"y":525,"h":121,"w":121},{"x":755,"y":517,"h":139,"w":139}]},"medium":{"faces":[{"x":745,"y":275,"h":76,"w":76},{"x":531,"y":307,"h":71,"w":71},{"x":442,"y":303,"h":81,"w":81}]},"small":{"faces":[{"x":422,"y":155,"h":43,"w":43},{"x":301,"y":174,"h":40,"w":40},{"x":250,"y":171,"h":46,"w":46}]},"orig":{"faces":[{"x":2163,"y":799,"h":221,"w":221},{"x":1544,"y":894,"h":207,"w":207},{"x":1286,"y":881,"h":238,"w":238}]}},"sizes":{"large":{"h":1213,"w":2048,"resize":"fit"},"medium":{"h":711,"w":1200,"resize":"fit"},"small":{"h":403,"w":680,"resize":"fit"},"thumb":{"h":150,"w":150,"resize":"crop"}},"original_info":{"height":2064,"width":3484,"focus_rects":[{"x":0,"y":0,"w":3484,"h":1951},{"x":0,"y":0,"w":2064,"h":2064},{"x":0,"y":0,"w":1811,"h":2064},{"x":266,"y":0,"w":1032,"h":2064},{"x":0,"y":0,"w":3484,"h":2064}]},"allow_download_status":{"allow_download":true},"media_results":{"result":{"media_key":"3_1986083789081333761"}}}]},"favorited":false,"lang":"zh","possibly_sensitive":false,"possibly_sensitive_editable":true,"retweeted":false,"fact_check":null,"id":"1986084249750147200","view_count":1015,"bookmark_count":2,"created_at":1762354359000,"favorite_count":10,"quote_count":0,"reply_count":7,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986084249750147200","full_text":"之前一直看到过 INFINIT 但是没有仔细去了解它到底是做什么的,一直以为他就是做稳定币等数字化资产的,直到我看了它的白皮书和文档,原来 INFINIT 是一个全面的代理式去中心化金融(DeFi)生态系统。\n\nINFINIT 利用其 AI 代理基础设施,改变了用户与 DeFi 交互的方式:\n🔸 简化 DeFi 交互:不用懂代码,AI 会实时扫描链上收益,根据你的持仓和目标给出量身定制的方案。\n🔸 一键执行复杂策略:无论只是找个高收益挖矿组合,还是多协议的组合挖矿,都能一键完成。\n🔸 自然语言操作:像聊天一样用自然语言说出想法,AI 代理立刻帮你拼装、校验并上链,全程无需手动拆步骤。\n\n当然,如此优秀的功能离不开优秀的技术架构,INFINIT 拥有多个大语言模型,能够根据复杂性和上下文自动将用户查询路由到最佳模型,并将自然语言命令转换为确定性、可执行的操作。\n并且拥有多个专业的DeFi 智能体互相协作,能够在 100 多个不同区块链不同协议中进行数据聚合和处理,提供准确、标准化的信息给 AI 代理,用于实时和精确的策略推荐和执行。\n\n总的来说INFINIT 通过现在流行的 AI 代理方式,能够让普通用户就可以拥有专家级策略,同时保持完全的非托管控制,能够为我们这些普通用户拥有一个无缝的 DeFi 体验。\n@Infinit_Labs","in_reply_to_user_id_str":null,"in_reply_to_status_id_str":null,"is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[17,24],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1484231561784737792","name":"炼金叔叔.sol💍","screen_name":"AirdropAlchemis","indices":[0,16]}]},"favorited":false,"in_reply_to_screen_name":"AirdropAlchemis","lang":"zh","retweeted":false,"scopes":{"followers":false},"fact_check":null,"id":"1985916517784150481","view_count":296,"bookmark_count":0,"created_at":1762314369000,"favorite_count":1,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1985915800222597136","full_text":"@AirdropAlchemis 你这个隔壁大叔","in_reply_to_user_id_str":"1484231561784737792","in_reply_to_status_id_str":"1985915800222597136","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-07","value":1558,"startTime":1762387200000,"endTime":1762473600000,"tweets":[{"bookmarked":false,"display_text_range":[15,26],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"763250971141025792","name":"陳威廉","screen_name":"William11Chan","indices":[0,14]}]},"favorited":false,"in_reply_to_screen_name":"William11Chan","lang":"ja","retweeted":false,"fact_check":null,"id":"1986294094893883783","view_count":1558,"bookmark_count":0,"created_at":1762404390000,"favorite_count":1,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1986291074852397290","full_text":"@William11Chan 直接迎接新年 挺好的","in_reply_to_user_id_str":"763250971141025792","in_reply_to_status_id_str":"1986291074852397290","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-08","value":0,"startTime":1762473600000,"endTime":1762560000000,"tweets":[]},{"label":"2025-11-09","value":0,"startTime":1762560000000,"endTime":1762646400000,"tweets":[]},{"label":"2025-11-10","value":0,"startTime":1762646400000,"endTime":1762732800000,"tweets":[]},{"label":"2025-11-11","value":1574,"startTime":1762732800000,"endTime":1762819200000,"tweets":[{"bookmarked":false,"display_text_range":[11,25],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"313059654","name":"Gala","screen_name":"GalalaWen","indices":[0,10]}]},"favorited":false,"in_reply_to_screen_name":"GalalaWen","lang":"zh","retweeted":false,"fact_check":null,"id":"1987794316576899077","view_count":59,"bookmark_count":0,"created_at":1762762071000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987744567798718886","full_text":"@GalalaWen ai 高效 手写真诚,双结合","in_reply_to_user_id_str":"313059654","in_reply_to_status_id_str":"1987744567798718886","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[24,122],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1982109970696126464","name":"思维回响","screen_name":"SiweiHuixiang","indices":[0,14]},{"id_str":"1905661250971062272","name":"FogoNFT","screen_name":"FogoNFT","indices":[15,23]}]},"favorited":false,"in_reply_to_screen_name":"SiweiHuixiang","lang":"en","retweeted":false,"fact_check":null,"id":"1987868931907084565","view_count":3,"bookmark_count":0,"created_at":1762779860000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987823395778818327","full_text":"@SiweiHuixiang @FogoNFT Totally agree, Fogo is a gem. This genesis NFT has huge potential! Thanks for the whitelist guide.","in_reply_to_user_id_str":"1982109970696126464","in_reply_to_status_id_str":"1987823395778818327","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[25,28],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1623150253452177413","name":"真诚小道士丨MemeMax⚡️","screen_name":"realxiodos","indices":[0,11]},{"id_str":"1416454684525662215","name":"币世王 |MemeMax⚡️","screen_name":"0xKingsKuan","indices":[12,24]}]},"favorited":false,"in_reply_to_screen_name":"realxiodos","lang":"ja","retweeted":false,"fact_check":null,"id":"1987727193934602435","view_count":47,"bookmark_count":0,"created_at":1762746067000,"favorite_count":2,"quote_count":0,"reply_count":1,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987551815609840049","full_text":"@realxiodos @0xKingsKuan 道士王","in_reply_to_user_id_str":"1623150253452177413","in_reply_to_status_id_str":"1987551815609840049","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[19,34],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1716256762289098752","name":"奶昔 𝕏 全自动亏钱😭","screen_name":"0xNaiXi","indices":[0,8]},{"id_str":"1799089203483193344","name":"SOON - Solana Optimistic Network (Mainnet Arc)","screen_name":"soon_svm","indices":[9,18]}]},"favorited":false,"in_reply_to_screen_name":"0xNaiXi","lang":"zh","retweeted":false,"fact_check":null,"id":"1987909531037507806","view_count":1416,"bookmark_count":0,"created_at":1762789540000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987898022932742152","full_text":"@0xNaiXi @soon_svm 我刚关电脑,这是什么 奶昔哥!","in_reply_to_user_id_str":"1716256762289098752","in_reply_to_status_id_str":"1987898022932742152","is_quote_status":0,"is_ai":null,"ai_score":null},{"bookmarked":false,"display_text_range":[30,41],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1385900937051475974","name":"Charles.edge🦭MemeMax ⚡️","screen_name":"charles48011843","indices":[0,16]},{"id_str":"1887759577455992837","name":"MemeX","screen_name":"MemeX_MRC20","indices":[17,29]}]},"favorited":false,"in_reply_to_screen_name":"charles48011843","lang":"zh","retweeted":false,"fact_check":null,"id":"1988027602486038672","view_count":49,"bookmark_count":0,"created_at":1762817690000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1987853639290167759","full_text":"@charles48011843 @MemeX_MRC20 我操。2wu也太欧了吧","in_reply_to_user_id_str":"1385900937051475974","in_reply_to_status_id_str":"1987853639290167759","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-12","value":0,"startTime":1762819200000,"endTime":1762905600000,"tweets":[]},{"label":"2025-11-13","value":125,"startTime":1762905600000,"endTime":1762992000000,"tweets":[{"bookmarked":false,"display_text_range":[9,18],"entities":{"hashtags":[],"symbols":[],"timestamps":[],"urls":[],"user_mentions":[{"id_str":"1597583113160474624","name":"十年一梦","screen_name":"rnmumu3","indices":[0,8]}]},"favorited":false,"in_reply_to_screen_name":"rnmumu3","lang":"zh","retweeted":false,"fact_check":null,"id":"1988501746277380433","view_count":125,"bookmark_count":0,"created_at":1762930735000,"favorite_count":0,"quote_count":0,"reply_count":0,"retweet_count":0,"user_id_str":"1744901065886318592","conversation_id_str":"1988473399728054399","full_text":"@rnmumu3 正在研究印钱...","in_reply_to_user_id_str":"1597583113160474624","in_reply_to_status_id_str":"1988473399728054399","is_quote_status":0,"is_ai":null,"ai_score":null}]},{"label":"2025-11-14","value":0,"startTime":1762992000000,"endTime":1763078400000,"tweets":[]},{"label":"2025-11-15","value":0,"startTime":1763078400000,"endTime":1763164800000,"tweets":[]},{"label":"2025-11-16","value":0,"startTime":1763164800000,"endTime":1763251200000,"tweets":[]}]},"interactions":{"users":[{"created_at":1675824163000,"uid":"1623150253452177413","id":"1623150253452177413","screen_name":"realxiodos","name":"真诚小道士丨MemeMax⚡️","friends_count":5062,"followers_count":25331,"profile_image_url_https":"https://pbs.twimg.com/profile_images/1987712262484922368/FtzdMKxM_normal.jpg","description":"✧ 信仰 $OKB $PARTI ,立志要成为嘴撸王的男人丨 #蓝鸟会\n\n✦ 全链交易用UX丨https://t.co/XlXPMmAmIM 邀请码:2BEHE5\n\n✧ 出入金用BiYa丨https://t.co/fCvElmWLwf\n\n✦ 省钱就用Weex丨https://t.co/Xvk56bV3Sh","entities":{"description":{"urls":[{"display_url":"xiodos.com/ux","expanded_url":"http://xiodos.com/ux","url":"https://t.co/XlXPMmAmIM","indices":[47,70]},{"display_url":"xiodos.com/biya","expanded_url":"http://xiodos.com/biya","url":"https://t.co/fCvElmWLwf","indices":[95,118]},{"display_url":"xiodos.com/weex","expanded_url":"http://xiodos.com/weex","url":"https://t.co/Xvk56bV3Sh","indices":[131,154]}]},"url":{"urls":[{"display_url":"realxiodos.t.me","expanded_url":"http://realxiodos.t.me","url":"https://t.co/GI7czuMUyt","indices":[0,23]}]}},"interactions":1}],"period":14,"start":1761991343309,"end":1763200943309}}},"settings":{},"session":null,"routeProps":{"/creators/:username":{}}}